推荐系统已经成为互联网应用提升点击率、转化率、留存率和用户体验的必备手段,然而,随着流量和数据量的爆发式增长,以及企业竞争环境日新月异的变化,快速搭建一套易用、精准、可灵活扩展的个性化推荐系统已成为每一家互联网企业必备的生存技能。
推荐系统一方面需要能够及时处理海量的用户行为日志,从中挖掘出用户的画像信息及行为偏好;另一方面又要对海量的物料数据(推荐候选集)进行精准的分析,预测每个候选物料未来一段时间内的转化概率;同时还需要对推荐的上下文进行分析,精准预测出在应该在什么时间、什么地点、给什么用户推荐什么内容。推荐内容的精准度、时效性、多样性、短长期受益平衡等各方面都对推荐系统提出了很高的要求。从零开始搭建一套合格的推荐系统绝非易事。所幸,随着云计算平台的兴起,搭建推荐系统所需要的各种基础技术、工具、产品和平台越来越成熟,相信搭建云上的智能推荐系统对中小企业来说是一个比较好的选择。
本文主要介绍如何基于阿里云平台,从0到1搭建一套高效、精准、易用、可扩展的智能推荐系统。
1 系统架构
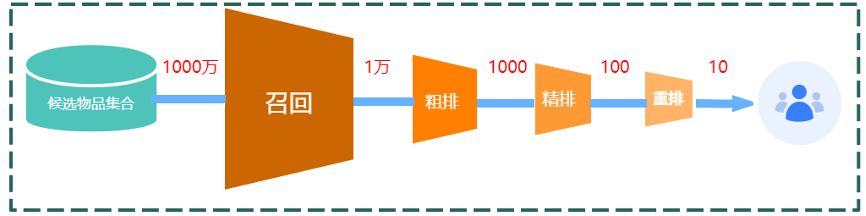
粗略来看,推荐算法可以简单地分为召回和排序两个阶段。召回模块负责从海量的物品库里挑选出用户可能感兴趣的物品子集,通常返回几百个物品。排序模块负责对召回阶段返回的物品集个性化排序,通常返回几十个物品组成的有序列表。总结起来,召回和排序有如下特点:
- 召回层:候选集规模大、模型和特征简单、速度快,尽量保证用户感兴趣数据多召回。
- 排序层:候选集不大,目标是保证排序的精准,一般使用复杂和模型和特征。
在实际的生成环境中部署推荐系统时,当物品库很大时,召回模块的返回结果可能是在万的量级,一般会把上述排序模块拆分成粗排、精排、重排三个模块,粗排模块使用简单的机器学习模型进一步过滤掉部分候选物品,保证进入精排的物品量级在一千以下,精排模块使用较复杂的模型给每个候选物品计算一个排序分。排序分一般以业务指标为拟合目标,比如在电商场景可能会用CTR预估值,或者CTR CVR price以便最大化GMV。重排模块一般实现一些list-wise的页面级排序,或是打散等多样性业务规则。
召回模块一般采用多路召回的策略,从不同的角度构建用户与候选商品之间的连接,并度量该连接的强弱程度。召回模块的结果即为用户可能感兴趣的商品集合。召回的算法有很多,这里举例如下:
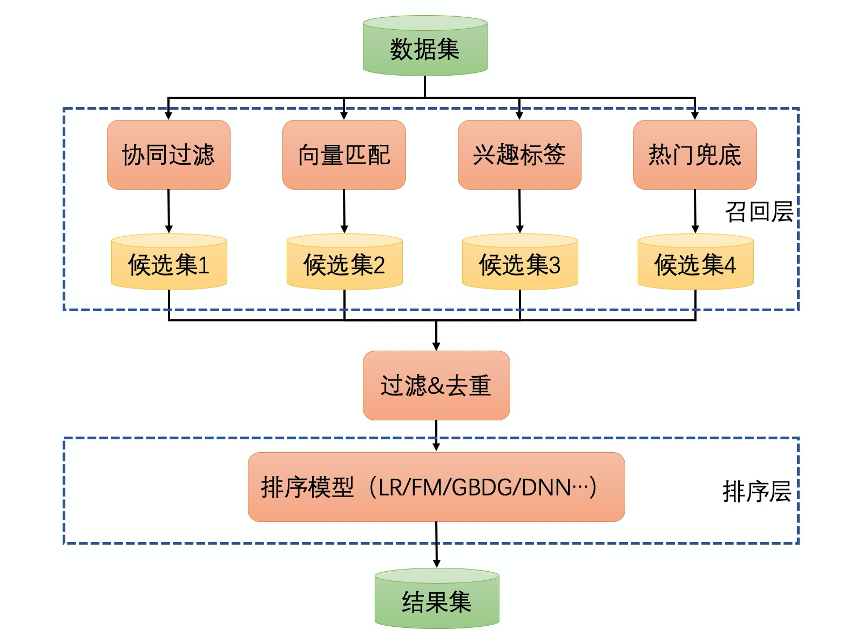
不管使用哪一种召回方法,都需要大数据计算平台和分布式数据库的支持。推荐系统中,召回阶段的要求是能够低延时地从大量的候选集找筛选出用户可能感兴趣的物品。大规模、低延时是召回阶段面临的两大挑战;解决方案就是建立倒排索引,使用分布式数据存储引擎存储索引数据,而索引数据的生成则交给大数据计算平台(如MaxCompute、EMR等)负责。
通常有两种类型的索引:
- key-value 索引:根据指定的key实现快速的点查
- 向量索引:向量引擎可以快速返回与query向量的top N邻近向量集合
阿里云交互式分析产品Hologres是集 key/value 点查、向量匹配引擎、关系式数据库 与一体的分布式数据存储和分析引擎,非常适合在推荐系统中存储召回阶段的索引数据及排序阶段的特征数据。Hologres兼容PostgreSQL协议,与大数据生态无缝连接,支持高并发和低延时地查询分析万亿级数据。在推荐系统中使用Hologres至少有以下两点好处:
- 统一的查询语言实现点查、向量匹配、条件过滤等功能,较少推荐系统需要对接的下级工具产品,降低开发工作量。
- 可以轻松实现计算下沉,例如查询和过滤可以在同一个查询里实现,减少推荐引擎与数据存储系统之间的交互次数。
排序阶段的主要目标是调用算法模型对召回结果的每个物品计算一个或多个目标分数,并拟合成一个最终的排序分,最后推荐系统根据排序分取top N个商品返回给请求方。这个阶段涉及的工作包括:样本构建、特征工程、模型训练、模型评估、模型部署。每个子阶段,阿里云计算平台事业部PAI团队都提供了相应的工具,可以提高工作效率,减少出错的概率,下文将详细介绍。
准备好了召回阶段需要的索引数据、排序阶段需要的特征数据和算法模型,最后还需要一个推荐服务串起整个流程。基于PAI团队提供的PaiRec推荐引擎,用户可以轻松搭建一个完整的推荐服务。一个完整的推荐系统,通常需要在线测试不同的推荐策略和算法,少不了A/B测试框架的帮助。PAI-ABTest平台是独立于PaiRec推荐引擎的A/B测试平台,支持横向、纵向切流和分层实验,是推荐系统必不可少的重要组成部分。
实时特征/模型对应提升推荐算法的效果有很大的帮助,基于阿里日志服务和阿里云全托管的Flink实时计算平台,可以轻松为推荐系统提高实时响应能力。
通常,常规的召回、粗排、精排算法对新物品、新用户都不太友好,新物品很大程度上,会被模型“低估”,因此有必要在推荐系统中显式地处理冷启动问题。冷启动问题处理不好会影响内容创造者的积极性,进而影响平台生态的健康发展。Pai团队提供了基于contextual bandit算法的物品冷启动产品化方案,需要部署冷启动算法的客户可联系我们。
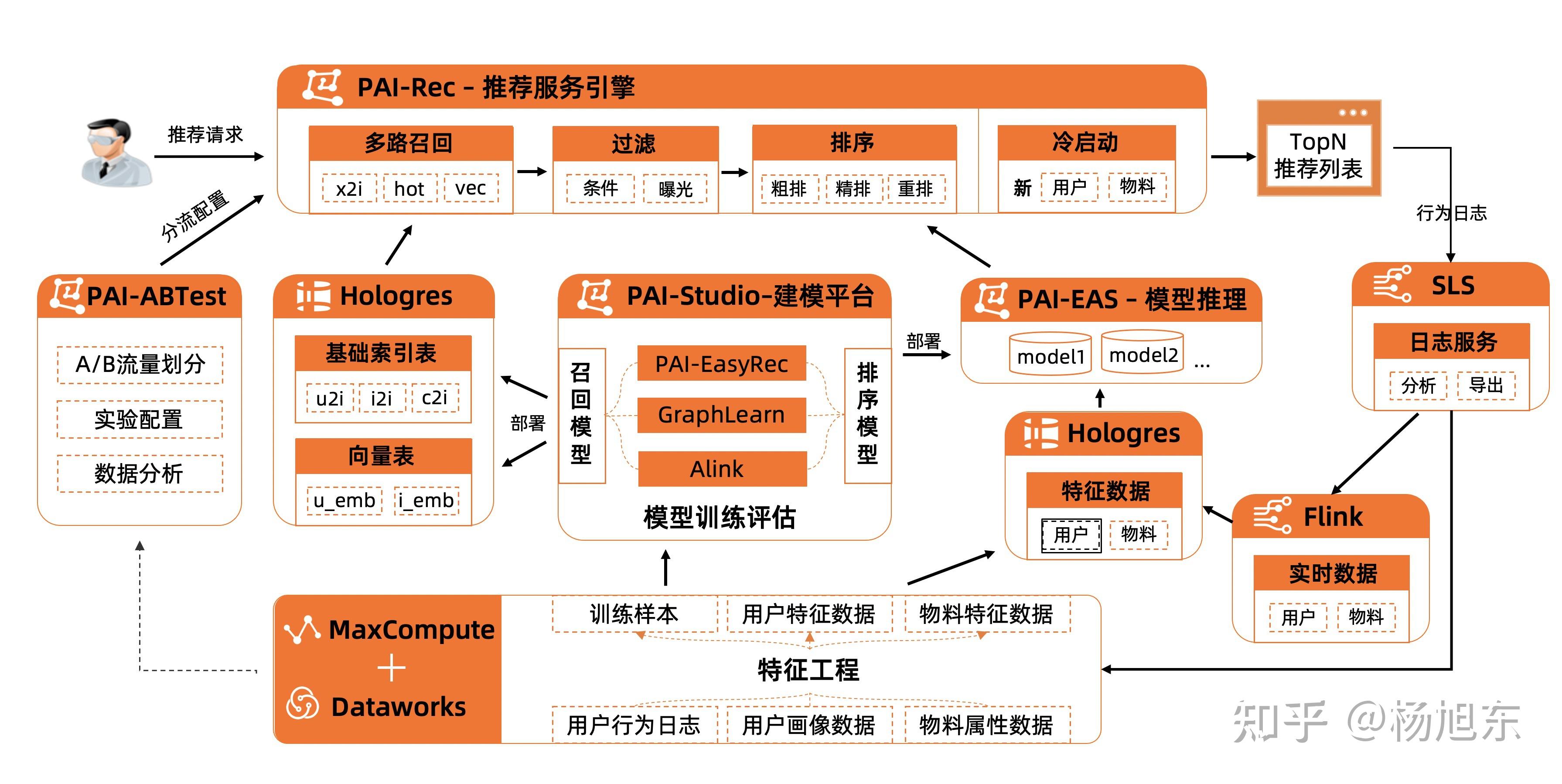
一个可行的基于阿里云产品搭建的云上个性化推荐系统架构如下图所示:
2 召回
2.1 协同过滤
协同过滤算法是完全基于用户交互行为的召回算法,分为User Based CF(为当前用户推荐相似用户喜欢的物品)和Item Based CF(为当前用户推荐该用户曾经喜欢过的物品的相似物品)两大类。具体选择哪一种,需要依据业务场景的特定来定,通常,因为用户兴趣的多样性和易变性,UserCF在实际中使用较少,多数推荐系统会优先选择ItemCF算法。
要使用协同过滤算法,首先需要构建用户和物品的交互行为矩阵,比如在电商场景,主要使用用户的隐式反馈数据来构建行为矩阵,比如使用点击、收藏、购买等行为数据构建User-Item行为矩阵。行为矩阵是很稀疏的,大多数元素都是空缺的,表示对于的用户和商品之间没有产生交互行为。协同过滤算法本质上就是使用User-Item行为矩阵中已有的值作为输入构建模型来填充对空缺值的预估。有了预估值之后,就可以对某用户推荐得分比较高的预估值对应的商品列表了。
交互行为矩阵的原始数据通常来自于平台记录的行为日志。行为日志一般有前端上报到日志服务器,最终导入到大数据处理平台,形成行为日志表,该数据是推荐算法的重要输入之一。在阿里云PAI平台上可用的协同过滤算法包括:etrec、swing、simrank等。这些算法通过不同的公式计算物品与物品(或者用户与用户)之间的相似性,最终构建出每个物品的相似物品及相似分列表,这就是协同过滤算法召回用的索引数据。
PAI-Studio支持通过可视化或PAI命令的方式,配置使用协同过滤算法。以etrec算法为例,pai命令的调用方式如下:
1 | PAI -name pai_etrec |
swing算法的调用方式如下:1
2
3
4
5
6
7
8
9
10PAI -name swing_rec_ext
-project algo_public
-DinputTable='swing_test_input'
-DoutputTable='swing_test_result'
-DmaxClickPerUser='500'
-DmaxUserPerItem='600'
-Dtopk='100'
-Dalpha1='5'
-Dalpha2='1'
-Dbeta='0.3'
参考资料:基于协同过滤的物品推荐
2.2 兴趣标签
广义上来说,兴趣标签的召回是一种基于内容的召回。通常分为三个步骤:
- 挖掘物品的内容标签;
- 根据历史交互行为计算用户对各个内容标签是偏好程度;
- 给目标用户推荐他偏好的内容标签下对应的热门物品。
协同过滤通过相似性来构建目标用户与候选物品之间的桥梁,而兴趣标签的召回则是通过“标签”来架起目标用户与候选物品之间的桥梁。
挖掘物品的标签通常需要NLP、图像、视频相关的算法,如中心词提取、短语挖掘等方法可以从文本信息中挖掘兴趣标签;图像/视频 打标算法则从图像和视频内容本身来预测兴趣标签。这些基础技术在阿里云平台上都有对应的工具。
参考资料:基于用户和物品画像的物品推荐
2.3 向量召回
向量召回是一种基于模型的召回方法,首先我们需要训练一个深度学习模型,得到用户和物品的低维实数向量(通常叫做embedding向量),每个向量对应N维空间的一个点,这些点之间的距离越近表示对应的两个物体在现实世界中越相似。这样我们可以在N维空间中通过找到与当前目标用户的点最近的M个邻居,限定邻居的类型为候选物品,这样我们就可以召回top M个待推荐后续物品集合。
双搭模型是学习embedding向量的常用方法。在Pai团队开源的推荐算法框架EasyRec中,实现了两种常用的召回模型:DSSM和MIND,包括增强的随机负采样版本,可以开箱即用。顺便说一下,EasyRec致力于成为容易上手的工业界深度学习推荐算法框架,支持大规模训练、评估、导出和部署。EasyRec实现了业界领先的模型,包含排序、召回、多目标等模型,支持超参搜索,显著降低了建模的复杂度和工作量。想了解更多EasyRec的内容,可以查看EasyRec帮助文档。
有了embedding向量后,可以通过hologres构建向量索引,从而在推荐服务中快速检索出top K的推荐物品。Hologres深度集成了阿里达摩院自研的Proxima向量检索引擎,能够提供低延时、高吞吐的在线查询服务,其基于SQL查询接口,兼容PostgreSQL生态,简单易用,且支持带复杂过滤条件的检索;能够支持分布式构建向量索引、以及对索引进行检索,简单支持水平扩展。
全量检索查询语法如下:1
2
3
4select id, pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3}')) as distance
from feature_tb
order by distance asc
limit 10;
复杂条件下检索查询语法如下:1
2
3
4
5
6select id, pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3}')) as distance
from feature_tb
where data_time between '1990-11-11 12:00:00' and '1990-11-11 13:00:00'
and tag in ('X', 'Y', 'Z')
order by distance asc
limit 10;
2.4 热门召回
热门召回通常是在前几种召回策略失效的情况下(通常针对冷启动用户前几种召回方法会失效),或者为了增加召回多样性,而采用的一种策略。
我们可以统计候选物品在过去一段时间内的指标数据,比如商品销量,视频播放量,文章阅读量等来筛选出全局热门或针对某个人群热门的候选物品集,从而为这些用户或人群推荐对应的物品。然而,这种方式对新物品不友好,新上线的物品(如,短视频平台发布的内容)没有机会被曝光,从而影响内容创作者的积极性,以及平台生态的健康发展。因此,我们需要对一个对候选物品人气分预估的模型,来统一对新老物品进行预估,并且根据预估分(而不是简单的统计值)来确定热门物品。
人气分模型可以基于GBDT算法来建模,由于GBDT算法能够很好地建模特征与目标直接的非线性关系,并且对特征工程的要求比较低,很容易实施。人气分模型的一个例子可参考《商品人气分模型》。
PAI平台上可以使用ps_smart算法(GBDT算法的一种实现)来训练人气分模型,pai命令如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26PAI -name ps_smart
-project algo_public
-DmodelName="product_popularity"
-DinputTableName="product_popularity_model_samples"
-DinputTablePartitions="ds=${bizdate}"
-DoutputTableName="product_popularity_model"
-DoutputImportanceTableName="product_popularity_feature_importance"
-DlabelColName="label"
-DweightCol="weight"
-DfeatureColNames="features"
-DenableSparse="true"
-Dobjective="binary:logistic"
-Dmetric="error"
-DfeatureImportanceType="gain"
-DtreeCount="100"
-DmaxDepth="5"
-Dshrinkage="0.3"
-Dl2="1.0"
-Dl1="0"
-Dlifecycle="3"
-DsketchEps="0.03"
-DsampleRatio="1.0"
-DfeatureRatio="1.0"
-DbaseScore="0.2"
-DminSplitLoss="0"
-DfeatureNum=@feaNum
可以在阿里云DataWorks开发工具上新建一个SQL节点,粘贴如上的命令即可执行。
3. 排序
3.1 特征工程
样本构建、特征加工通常是搭建推荐系统的过程中最耗时耗力的阶段,这个阶段工作量大,也容易出错。为此,阿里云PAI团队开发了一套推荐模板,可根据配置文件,由三大输入表(用户信息表、物品信息表、交互行为表)自动为客户生成一套初始的ETL SQL代码,完成了大部分召回、排序所需要的离线计算代码的生成。客户可基于该代码继续调整优化。
通常排序模型的特征由三部分构成:
- 用户侧特征:包括用户画像信息、用户粒度统计信息(过于一段时间窗口内用户各种行为的统计值)、用户偏好信息(用户-物品或用户-物品属性粒度的交叉统计信息)
- 物品侧特征:物品基础内容信息、物品粒度的统计信息、物品偏好信息(物品-用户画像、物品-人群画像粒度的统计信息)
- 上下文特征:地理位置、访问设备、天气、时间等
有了上述三部分原始特征后,还需要对特征进行加工,生成最终模型可接受的格式的数据。由于模型加工的过程离线和在线服务都需要,因此,如果离线计算开发一套代码,在线服务又开发一套代码,不仅耗费精力,而且容易出错,造成离在线特征值不一致,从而影响模型的实际效果。因此,为保证离在线特征加工逻辑的一致性,我们用C++开发了一套feature generator的代码,供在线服务使用;同时,把同一份代码用jni封装后,在离线MapReduce任务中使用。
Feature generator工具支持多种特征类型的加工,包括IdFeature、RawFeature、LookupFeature、ComboFeature、MatchFeature、SequenceFeature等,基本满足了日常所需。
3.2 模型训练
Pai团队开源了开箱即用的推荐算法训练框架EasyRec。用户可直接用自己的数据训练内置的算法模型,也可以自定义新的算法模型。目前,已经内置了多个排序模型,如 DeepFM / MultiTower / Deep Interest Network / DSSM / DCN / WDL 等,以及 DBMTL / MMoE / ESMM / PLE 等多目标模型。另外,EasyRec兼容odps/oss/hdfs等多种输入,支持多种类型的特征,损失函数,优化器及评估指标,支持大规模并行训练。使用EasyRec,只需要配置config文件,通过命令调用的方式就可以实现训练、评估、导出、推理等功能,无需进行代码开发,帮您快速搭建推广搜算法。
相比NLP和CV领域的模型,推荐模型的特定是输入的field特别多,可能有几百个,并且各个field的类型和语义也各不相同,需要不同的处理,比如,有的field当成原始特征值使用,有的field需要转embedding之后再接入model,因此,对输入数据的处理通常是开发推荐模型时需要很多重复劳动、易出错、又没有多少技术含量的部分,这让算法工程师头疼不已。EasyRec工具对输入特征的处理进行了自动化,只需要简单的配置即可省去很多重复性劳动。
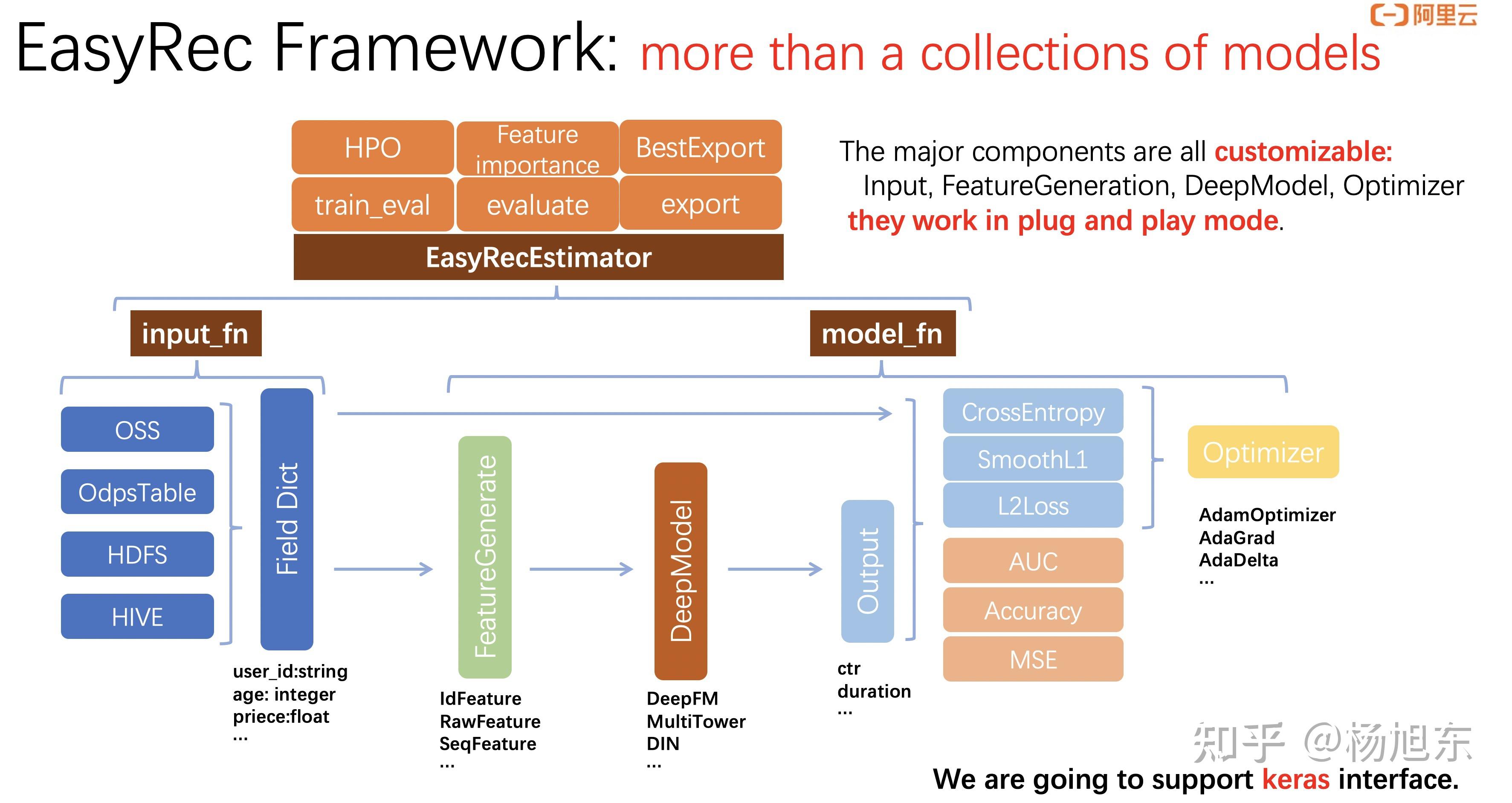
在阿里云平台上《使用EasyRec构建推荐模型》请查看对应的文档。
请查看EasyRec使用教程视频了解详细使用方法。更多资料请查看机器学习PAI视频内容。
3.3 模型部署
模型还需要部署成服务才能被推荐引擎调用。为实现一站式算法应用,PAI针对在线推理场景提供了在线预测服务PAI-EAS(Elastic Algorithm Service),支持基于异构硬件(CPU和GPU)的模型加载和数据请求的实时响应。
通过PAI-EAS,您可以将模型快速部署为RESTful API,再通过HTTP请求的方式调用该服务。PAI-EAS提供的弹性扩缩和蓝绿部署等功能,可以支撑您以较低的资源成本获取高并发且稳定的在线算法模型服务。同时,PAI-EAS还提供了资源组管理、版本控制及资源监控等功能,便于将模型服务应用于业务。
为了让更多环境的开发者使用便捷的模型服务部署功能,PAI-EAS支持通过EASCMD方式完成服务部署的所有操作,详情请参见命令使用说明。举例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41bizdate=$1
cat << EOF > eas_config_rank.json
{
"name": "dbmtl_rank_ml",
"generate_token": "true",
"model_path": "oss://algo/rec_dbmtl/${bizdate}/export/best/",
"processor": "tensorflow_cpu",
"oss_endpoint": "oss-us-west-1.aliyuncs.com",
"token": "******",
"metadata":{
"region": "us-west-1",
"instance": 2,
"cpu": 8,
"gpu": 0,
"memory": 8000
}
}
EOF
echo "-------------------eas_config_rank.json-------------------"
cat eas_config_rank.json
# 创建服务
/home/admin/usertools/tools/eascmd -i ${access_id} -k ${access_key} \
-e pai-eas.${region}.aliyuncs.com create eas_config_rank.json
# 更新服务
echo "-------------------更新服务-------------------"
/home/admin/usertools/tools/eascmd -i ${access_id} -k ${access_key} \
-e pai-eas.${region}.aliyuncs.com \
modify dbmtl_rank_ml -s eas_config_rank.json
status=$?
# 查看服务
echo "-------------------查看服务-------------------"
/home/admin/usertools/tools/eascmd -i ${access_id} -k ${access_key} \
-e pai-eas.${region}.aliyuncs.com desc dbmtl_rank_ml
exit ${status}
4. 推荐服务
最后,还需要推荐服务串联起所有的环节,对外提供后续物品的内容推荐。PaiRec是Pai团队研发的一款基于 go语言 的在线推荐服务引擎的框架,用户可以基于此框架快速搭建推荐在线服务,也能定制化进行二次开发。
PAIRec框架 提供如下功能:
- 集成 go http server, 提供路由注册功能,方便开发 Restful Api
- 包含完成的推荐引擎的 pipeline 流程,里面预定义了多种召回、过滤,排序策略,内置访问阿里云 模型推理 EAS 服务
- 包含多种数据源的加载,支持 hologres, mysql, redis, OTS, kafka 等
- 基于灵活的配置描述推荐流程
- 集成轻量级 A/B Test 实验平台
- 支持简单易用的扩展点,方便自定义操作
整体框架如下: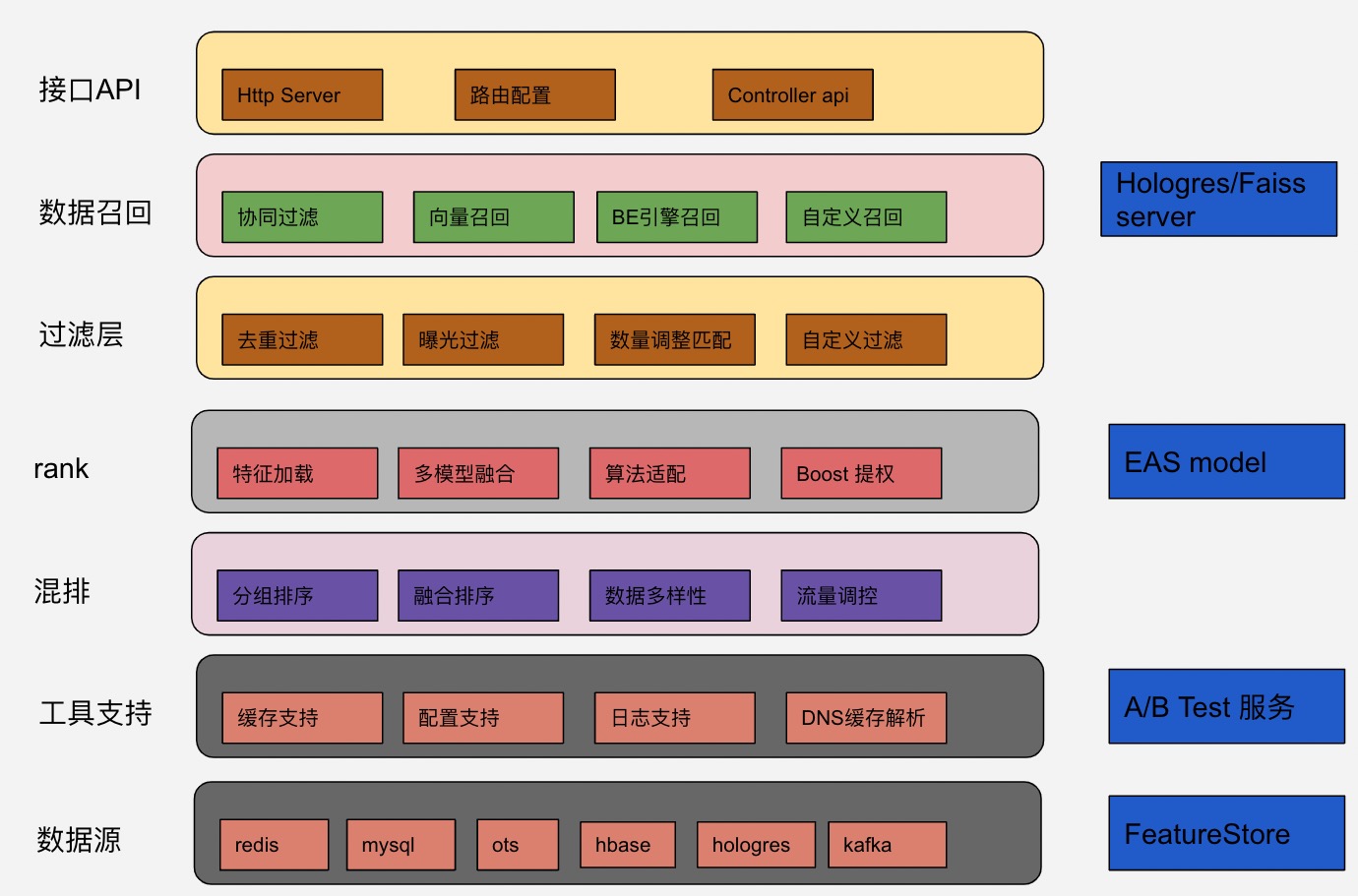
内置功能模块包括: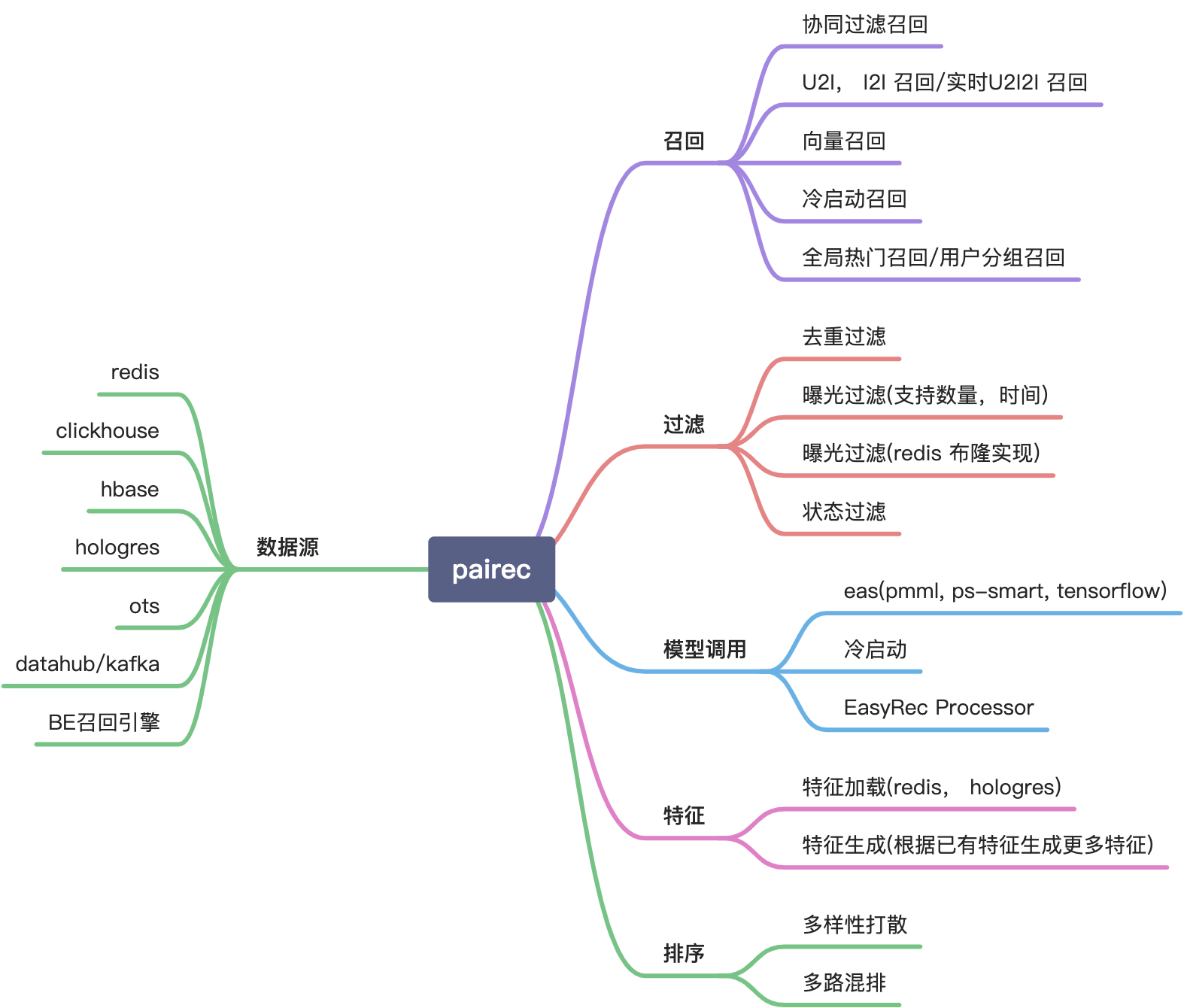
基于PAIRec框架开发的推荐服务可以以自定义镜像容器的方式部署在PAI-EAS平台上,可以复用PAI-EAS平台的集群管理、监控、报警等基础功能,使用起来非常方便。

