在移动互联网时代,电商领域的O2O服务检索(检索目标为服务商家和优惠券等)和在线商品检索必然存在许多不同点。比如,O2O服务检索更强调“移动”的特点,有一定的地域和距离的限制。同时,检索需求也跟用户所处的“情境”有很大的关系,因而在不同“情境”下用户对检索结果的期望也有所不同。O2O场景下,一个好的检索系统必然要考虑到这些特点,检索结果要能够做到对用户所在地域和所处“情境”的自适应调整。相比传统的电商商品检索,O2O服务检索对检索系统的召回和排序算法都提出了更高的要求。
尽管如此,O2O服务检索和在线商品检索也存在很多共性,比如检索结果的相关性都是衡量用户满意度和检索系统是否成功的重要指标之一。就相关性度量算法而言,传统检索系统存在的问题在O2O服务检索系统中依然存在,比如文本的“mismatch”问题、检索结果的主题转义问题等。O2O服务检索相关性的另一个挑战是数据质量的问题。由于O2O行业还是一个比较年轻同时又竞争激烈的行业,检索系统对O2O服务的数据录入和校验相对来说比较宽松,加上在运营数据方面投入的资源相对较少,导致O2O垂直搜索引擎索引的文档数据质量严重不如传统电商的商品数据。与传统电商相比,O2O搜索服务要求对数据更多的结构化表示,比如每个O2O服务必然要关联一个POI,同时每个POI必然要关联地址、品牌、经纬度和所在城市等数据,因而O2O数据质量更难把控,数据的运维也需要很多的成本。在我们的系统中,发现的跟数据质量有关的问题包括:服务所在城市的信息错误、服务所关联的POI信息错误、服务挂载到不相关的类目等等。甚至O2O服务的类目体系都存在很多不合理的方面,比如存在很相似的类目,导致服务本身不知道到底应该挂载在哪个类目的情况,另外,不同类目下商品/服务数量不均衡也是一个问题。
由于O2O业务是一个较新的尝试,因而由传统电商业务积累而来的基础算法都不能直接应用到O2O业务场景。比如,为传统电商业务而生的分词和词性标注算法,在O2O场景下直接应用就会导致很多的bad case。O2O服务商品数量的限制、O2O用户行为数据的不足都直接导致很多为传统电商业务而生的算法在O2O业务场景下失去了用武之地。
综上所述,在O2O业务场景下,基础数据运维、基础算法积累和O2O特定算法的开拓和尝试成为O2O算法团队的主要工作内容。
下面主要介绍O2O检索业务所用到的一些基础算法。
Term weighting
Term的权重为检索系统的召回和排序提供了重要的信息。衡量一个Term的重要程度有很多方法。目前我们使用多个特征的线性加权来获得最终的权重分。考虑的特征包括:TF、ICF、类目信息熵、词性Tag等。有了这些特征,当然也可以用监督学习的方法来学习Term的权重,这是我们未来尝试的方向之一。
- TF(Term frequency): Term的频率,即Term在语料库中出现次数除以语料中的Term总数。
- ICF:Term的逆类目频率,计算公式为$log(|C|/|{c:t∈c}| )$。其中$|C|$表示系统中的类目总数,$|{c:t∈c}|$表示包含Term $t$的类目的集合的大小 。这个类似于传统的IDF(逆文档频率),即把一个类目下的所有商品/服务数据的文本信息(比如商品title)作为一个文档。
TF/ICF则类似于传统检索系统中使用的TF-IDF算法。 - 类目信息熵:$-\sum_c{p(c│t)logp(c|t)}$。类目信息熵越大说明Term的类目信息越不确定,因而该Term的表意就越泛,其重要程度就越低;反之,类目信息熵越小表明Term越重要。这里的条件概率$p(c│t)$是基于语料数据直接统计得到,当然还可以基于其他数据来计算该条件概率,比如可以基于点击log数据统计Term点击类目的概率分布。
- 词性Tag和语义Tag。根据经验产品词(服务内容)应赋予较高的权重,其他的Tag比如商品品牌、重要修饰词等都可以人为赋予适当的权重。词性Tag和语义Tag一般来自于带词性标准的分词工具。
相关词挖掘
基于bag of words方法的Term匹配仍然是现代搜索引擎的主要召回手段。“一义多词”和“一词多义”导致的文本语义失配(mismatch)一直是导致检索系统召回率不足和相关性较差的罪魁祸首。比如,搜索“KFC”未必能召回“肯德基”相关的内容;搜索“小米”可能既召回了小米手机,又召回了小米这种食物。另一方面,缺乏词之间的语义相关信息,也可能导致召回和相关性的问题。比如,搜索“美食”应能召回小吃之类的内容;搜索“标准间”应能召回酒店、宾馆之类的结果;但如果不去理解文本背后的语义,仅仅从文本字面匹配的角度出发,这样的召回都是不能够实现的。
相关词挖掘是Query改写的主要方法之一,同时也能够为相关性模型提供必要的特征。这里介绍几种常用的相关词挖掘算法。
- 正则化的点互信息: $pmi(x,y)=log(\frac{p(x,y)}{p(x)p(y)})$
如果两个词经常同时在相同的上下文中出现,那么这两个词之间必然有较强的关联关系。互信息正是度量这种关联关系强弱的一种较好的方法。 - Word2vec
Word2vec是基于神经网络的语言模型学习方法,其能够学习到较好的词向量,即Term的Distributed Representation。通过计算词向量的相似度可以计算出词之间的相关程度。
由于介绍Word2vec的文献资料较多,这里就不再介绍了。只是强调一点相关领域的训练数据收集应尽可能多,同时又要排除不相关的数据。 - 基于点击反馈数据的方法
- Dice coefficient
计算公式为:
其中,$C(q, w)$是Query中包含Term $q$且文档title中包含Term $w$的query-title对的数量,$C(w)$是所有包含Term $w$的query-title对的数量。 - EM算法
基于点击数据用Query-title对作为训练语料,求$P(q|w)$的最大似然。具体细节参考:Brown, P. F., Della Pietra, S. A., Della Pietra, V. J., and Mercer, R. L. 1993. The mathematics of statistical machine translation: parameter estimation. Computational Linguistics, 19(2): 263-311.
- SimRank++算法
SimRank++算法是SimRank算法的扩展。该算法的基本原理就是“与相似对象相关的对象之间也相似”。SimRank++算法在SimRank算法的基础上考虑了Query-Document点击二部图中边的权重和方差,以及两个待求解节点共同邻居节点的数量,可以取得更好的效果。SimRank++算法的迭代公式:其中,$W(q,i)=e^{-var(i)} \cdot \frac{w(q,i)}{\sum_{j∈E(q)}{w(q,j)}}$
- Dice coefficient
Query类目预测
Query的预测类目可以用来作为召回文档的方法,而且其召回能力往往要比通过Term匹配方式的召回能力强。另外,Query的预测类目也是保证召回结果相关性的重要方法。类目相关度高的商品或服务应该有更靠前的排序,类目不相关的商品和服务应不予展现或靠后展现。
有丰富行为反馈数据时,在检索某个Query时,用户浏览、点击、收藏、购买等行为关联到的商品或服务的类目,为Query的预测类目提供了很好的候选集,尤其是对高频Query,往往通过简单的统计方法就能够获得不错的效果。然而,在O2O这个较新的业务场景下,行为数据不够丰富,因而要解决Query的类目预测问题只能另辟蹊径。
解决方案是从商品数据出发,通过计算出Term到类目的条件概率$p(c|w)$,再辅助以Term的权重,加上精心设计的规则,为Query的类目预测提供了一套完整且有效的流程,概况如下:
- Step1: 计算$p(c_1 |w)$, $p(c_2 |w)$,…
- Step2: $score(q,c)=\sum_{w∈q}{weight_w \cdot p(c|w)}$
- Step3: 根据规则做截断
其中,计算条件概率$p(c|w)$是其关键,我们采用一个混合概率模型来解决这个问题。我们认为一个商品title中的一个词$w$,可能来自于该商品所在类目下的语言模型,也可能来自于全局的背景语言模型,通过参数$λ$来来自于调节两者的概率,并通过EM算法来计算$p(w|c)$,反过来将其作为我们需要的$p(c|w)$。
EM算法求解步骤:
- 隐含变量条件概率, $w$来自于$c$的概率
- 最大化期望估计参数
相关性
O2O检索的排序模型主要考虑距离、质量(热度、人气)和相关性等。相关性分的计算主要考虑文本相关性、主题相关性和实体匹配度。
文本相关性
文本相关性计算框架:$P(Q│D)=\prod_{q∈Q}{P(q|D)}$
其中,$P(q│D)=αP(q│C)+(1-α)\sum_{w∈D}{P(q│w)P(w|D)}$
$P(q|C)$是背景模型,表示词$q$来自于背景的概率,通过统计全局的Query Log获得;$P(w|D)$是文档模型,表示词$w$在文档$D$中出现的概率,大部分情况下可以认为$P(w|D)$是一个常量。因为对于商品数据而且,$D$的长度通常很短,而且一个词在$D$中重复出现并不能意外着这个词更重要。用词$w$在$D$中的权重占比代替可能更好。
$P(q│w)$即用前面小节所介绍的相关词挖掘算法获得,不同的算法可以得到不同的值,这些值都可以拿来作为特征。正是由于这里的$q$和$w$可以是不同的词,所以可以在一定程度上解决文本mismatch的问题。
主题相关性
这里说的主题是一个相对宽泛的概念,主题可以表示为类目的向量,也可以表示为词的向量。
抽象一点说,主题相关度模型通过把Query和文档映射到同一个潜空间(latent space),在潜空间上度量两者的相似性,通常用内积的方法。类似于机器学习的核方法(kernerl method)。不同的是,这里我们需要显式地定义两个映射函数:$∅:Q→H$和$∅’:D→H$。Query和文档的相关性度量可以定义为$∅(q)$和$∅’(d)$的内积,即:$k(q,d)=〈∅(q),∅’(d)〉$。该方法的示意图如下:
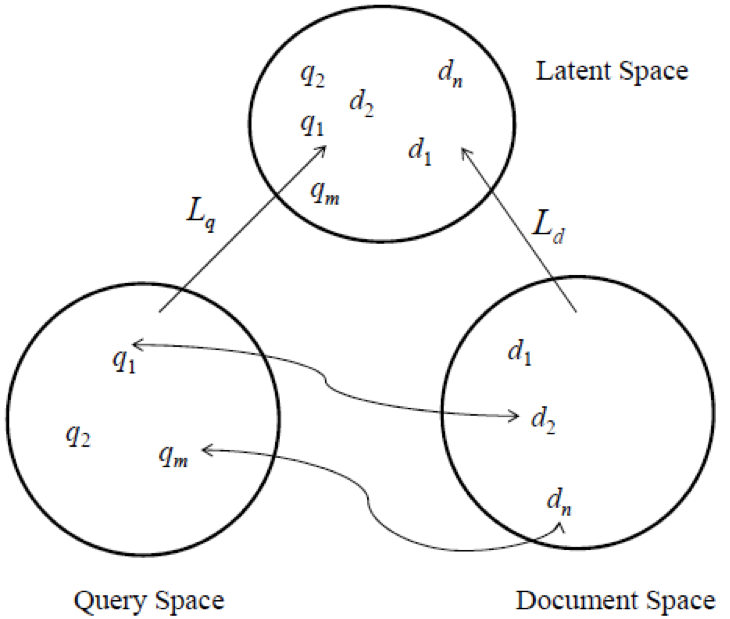
举个例子,比如用类目空间作为潜空间,那么Query到类目空间的映射即前面介绍的Query类目预测;商品到类目空间的映射直接用商品挂载的类目或通过算法纠正过的类目(解决类目错误挂载的问题)。
如果用Term向量作为潜空间,那么可以用PLSA或LDA等方法把Query和商品映射到潜空间。
当前潜空间还有很多其他的表示方法,对应的算法包括:PLS(Partial Least Square), Bilingual Topic Model, Deep Structured Semantic Model等。
实体匹配度
实体(entity)建立在知识图谱的基础之上,表征无歧义的概念。产品、服务、品牌、属性等都可以表示为实体。基于实体匹配我们可以建立很强的相关性排序规则,比如只允许在匹配上某种类型的实体时才认为是相关的,否则认为不相关。
基于实体的匹配是一件很简单的事情,但实体本身的挖掘和表示,以及如果与Query和商品关联,是基于实体匹配算法的重点。比如说给商品打上“产品”这个实体Tag,可能需要用到分词词性标注、词的权重、上下文、关联的属性列表等因子。
总结
本文简单地总结了在O2O垂直搜索引擎中,使用的一些跟匹配和排序相关的基础算法,具体内容没有过多的展开。一方面是对自己过去一段时间的工作内容进行总结,同时也希望能够给到相关领域的其他同学一些参考思路,感兴趣的读者可以根据文章中的思路去查阅更详细的资料,也欢迎大家留言跟我互动。

