背景
本文主要针对广告检索领域的查询重写应用,根据查询-广告点击二部图,在MapReduce框架上实现SimRank++算法,关于SimRank++算法的背景和原理请参看前一篇文章《SimRank++算法原理解析》。关于权值转移概率矩阵的实现请参看另一位文章《用hadoop实现SimRank++算法(1)----权值转移矩阵的计算》。
准备工作
在广告检索系统的查询重写应用中,对象分为两种类型:查询和广告。对象间的关系为点击关系。关系图为二部图,图中的每一条边表示在相应的查询下点击了对应的广告,边的权值为点击次数。下图表示由3个查询和2个广告构成的完全二部图,图中略去了边的权值。
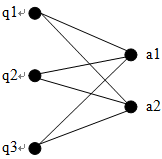
其对应的权值矩阵为:
把矩阵P右上角的非零子矩阵记为Q2A,左下角的非零子矩阵记为A2Q,则矩阵P可以写成分块矩阵的形式:$P=\left[ \begin{smallmatrix}0 & Q2A \\ A2Q & 0 \end{smallmatrix} \right]$
对应的矩阵P的转置矩阵为:$P^T=\left[ \begin{smallmatrix}0 & (A2Q)^T \\ (Q2A)^T & 0 \end{smallmatrix} \right]$
假设算法在第$k$轮迭代时计算出的相似性分数矩阵为:
把矩阵$S_k$的左上角的非零子矩阵记为$(Q-Q)^k$,右下角的非零子矩阵记为$(A-A)^k$,则矩阵$S_k$可以简写为:$S_k=\left[ \begin{smallmatrix}(Q-Q)^k & 0 \\ 0 & (A-A)^k \end{smallmatrix} \right]$
根据SimRank++算法的计算公式可得,
所以,二部图的相似性计算可以拆分成两部分:
其中, 操作符$Diag(M)$表示把矩阵$M$的非对角线元素全部都置为0得到的新矩阵,$N(q)$是参加计算的Query总数量,$N(a)$是参与计算的广告总数量。为了计算方便,公式可以变换为:
其中,$(A-A)^0=I_{N(a)}$,$(Q-Q)^0=I_{N(q)}$。
由于矩阵$(Q-Q)$和矩阵$(A-A)$的规模与原始的权值矩阵P相比,减少了很多。这样,通过把SimRank++算法的每一步都拆分成两个独立的操作,大大减少了算法操作数的规模,提高了算法的伸缩性。
迭代计算
由于SimRank算法依赖于矩阵乘法运算,因此这里用一个函数封装矩阵乘法运算MapReduce作业。函数的声明和主要参数如下:
MatrixMultiply(String inputPathA, String inputPathB, String outputDirPath, double decayFactor, boolean transA, boolean trans_multiply_self, boolean symm_result, …)
参数的含义如下表所示:
| 参数 | 含义 |
|---|---|
| inputPathA | 矩阵乘法的左操作数(矩阵A)的输入文件或目录 |
| inputPathB | 矩阵乘法的右操作数(矩阵B)的输入文件或目录 |
| outputDirPath | 运算结果的输出目录 |
| decayFactor | SimRank算法的衰减因子,默认值为1.0 |
| transA | 标识是否要在乘法运算前转置矩阵A |
| trans_multiply_self | 若为真,则计算AT * A(忽略inputPathB参数) |
| symm_result | 标识输出结果是否为对称矩阵,若为真,则只输出上(或下)对角阵 |
迭代计算的算法会产生大量的中间结果。对过期的中间结果应及时清理,否则占用的HDFS空间很可能会超过运行算法的账户配额,导致算法中途停止。我们通过输出输出目录的重复使用来及时清理中间结果。假设“MatrixMultiply”函数会在输出前自动删除outputDirPath目录内的所有内容。
计算两两Query之间的相似性分数的函数伪代码如下表所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17computeQ2Q(curr_iter){
if (0 == curr_iter)
{
inputPathA = inputPath_W_A2Q;
inputPathB = null;
outputPath = outputPath_S_Q2Q;
MatrixMultiply(inputPathA, inputPathB, outputPath, decay_factor, true, true, true);
}
else {
inputPathA = outputPath_S_A2A;
inputPathB = inputPath_W_A2Q;
outputPath = outputPath_M_Q2Q;
MatrixMultiply(inputPathA, inputPathB, outputPath, 1.0, false, false, false);
inputPathA = outputPath_M_Q2Q;
outputPath = outputPath_S_Q2Q2;
MatrixMultiply(inputPathA, inputPathB, outputPath, decay_factor, true, false, true);
}
计算两两Ad之间的相似性分数的函数伪代码如下所示:
1 | computeA2A(curr_iter){ |
SimRank迭代计算的伪代码如下:1
2
3
4
5
6
7curr_iter = 0
while (curr_iter < iter_times)
{
computeQ2Q(curr_iter);
computeA2A(curr_iter);
curr_iter++;
}

