在推荐算法领域,时常会出现模型离线评测效果好,比如AUC、准召等指标大涨,但上线后业务指标效果不佳,甚至下降的情况,比如线上CTR或CVR下跌。
本文尝试列举一些常见的原因,为大家排查问题提供一点思路。
1. 离线、在线特征不一致
离线、在线特征不一致通常是模型线上效果不好的主要原因,然而,造成离在线特征不一致的原因却千奇百怪,有些还非常隐蔽。
- 实现上存在Bug。离线、在线特征的ETL过程通常不是由同一份代码完成的,比如,离线特征的计算过程一般是使用SQL语言在大数据平台上完成,而在线特征的加工通常是由C++、Go这样的语言计算得到。这样就存在相同的逻辑需要实现两次,而且可能是不同的人来实现,如果不仔细测试,出现不一致的可能性还是很高的。要严格保证线上线下的特征一致性,最根本的方法就是同一套代码和数据源抽取特征,业内目前通用的方法就是,在线实时请求打分的时候落地实时特征,训练的时候就没有特征拼接的流程,只需要关联label,生成正负样本即可
- 特征更新存在延迟。一些需要实时计算得到的特征,如实时统计特征、序列特征等,离线模拟时不存在问题,然而,上线后由于各种原因,如果不能及时更新,那就造成了离线、在线的特征分布不一致,相当于是模型过拟合了。小时级更新、天级更新的特征,也有可能出现更新延迟的问题。
2. 存在数据泄露
数据泄露(data leakage),有时也叫做泄露、穿越等。它说的是用于训练机器学习算法的数据集中包含了一些将要预测的事务的东西(when the data you are using to train a machine learning algorithm happens to have the information you are trying to predict),也就是说测试数据中的一些信息泄露到了训练集中。这里说的信息是指关于目标标签或者在训练数据中可用但在真实世界中却不可用、不合法的数据。
数据泄露的类型介绍
我们可以将数据泄露分为两大类:训练数据泄露和特征泄露。训练数据泄露通常是测试数据或者未来的数据混合在了训练数据中,特征泄露是指特征中包含了关于真实标签的信息。
导致训练数据泄露可能有以下几种情况:
- 在进行某种预处理时是使用整个数据集(训练集和测试集)来计算的,这样得到的结果会影响在训练过程中所看到的内容。这可能包括这样的场景:计算参数以进行规范化和缩放,或查找最小和最大特征值以检测和删除异常值,以及使用变量在整个数据集中的分布来估计训练集中的缺失值或执行特征选择。
- 在处理时间序列数据时,另一个需要注意的关键问题是,未来事件的记录意外地用于计算特定预测的特性。
导致特征泄露可能有以下几种情况:
- 使用了一些不合法的特征,例如一个用来诊断特定疾病的模型,使用了病人是否做过当前疾病的手术这样的特征;再比如,CTR预估模型中使用了用户在商品详情页的交互行为特征,如是否评论、是否联系卖家等,这些行为在预测时没有发生的。
检测数据泄露
当我们了解了什么是数据泄露了之后,下一步来看下如何检测数据泄露。
在构建模型之前,我们可以先对数据进行一些探索分析。例如,寻找与目标标签或者值高度相关的特征,相关性非常高的特征可能是泄露特征。
当构建模型之后,我们可以检查下模型中权重极高的特征是否存在泄漏的情况。如果在构建模型之后,发现模型的效果好到不可思议,这时候需要考虑下是否发生了数据泄露。
另一个更可靠的检查泄漏的方法是,对经过训练的模型进行有限的实际部署,看看模型的训练时的性能与真实环境的表现之间是否有很大的差别。但是如果差别比较大的话,也有可能是是过拟合造成的。
3. 数据分布不一致
- 数据分布随时间发在漂移。例如,营销平台的大促活动、季节的变化、流行元素和审美标准的变化等等。
- 数据分布随地理位置发生漂移。同一时间点,南方人偏爱的服饰等物品与北方人可能是不同的,如果训练集中只包含某些地理位置的数据,而测试数据出现了另外的地理位置,这种情况就会出现。跨境电商平台通常需要考虑目标市场是南北半球的情况,而针对性地推荐不同季节的物品。
- 数据分布在不同场景是不同的。小场景往往因为数据量不够,会借助其他流量较多的场景的数据做模型训练,大场景的base模型可能是一个个性化的推荐系统,而小场景的base算法是非个性化的热门推荐,大小两个场景间的数据分布有较大的不同。这个时候训练样本的分布被大场景占据主导,训练出来的模型用在小场景效果可能会不好。做迁移学习时需要谨慎!
- 冰山效应。推荐系统里非常常见,并且往往非常的隐蔽的一种数据分布不一致的情况被称之为冰山效应,也就是说离线训练用的是有偏的冰山上的数据,而在线上预估的时候,需要预测的是整个冰山的数据,包括大量冰面以下的数据!我们看下面这张图。左边是我们的Baseline,绿色的表示正样本,红色表示负样本,灰色部分表示线上由于推荐系统的“偏见”(预估分数较低),导致根本没有展现过的数据。
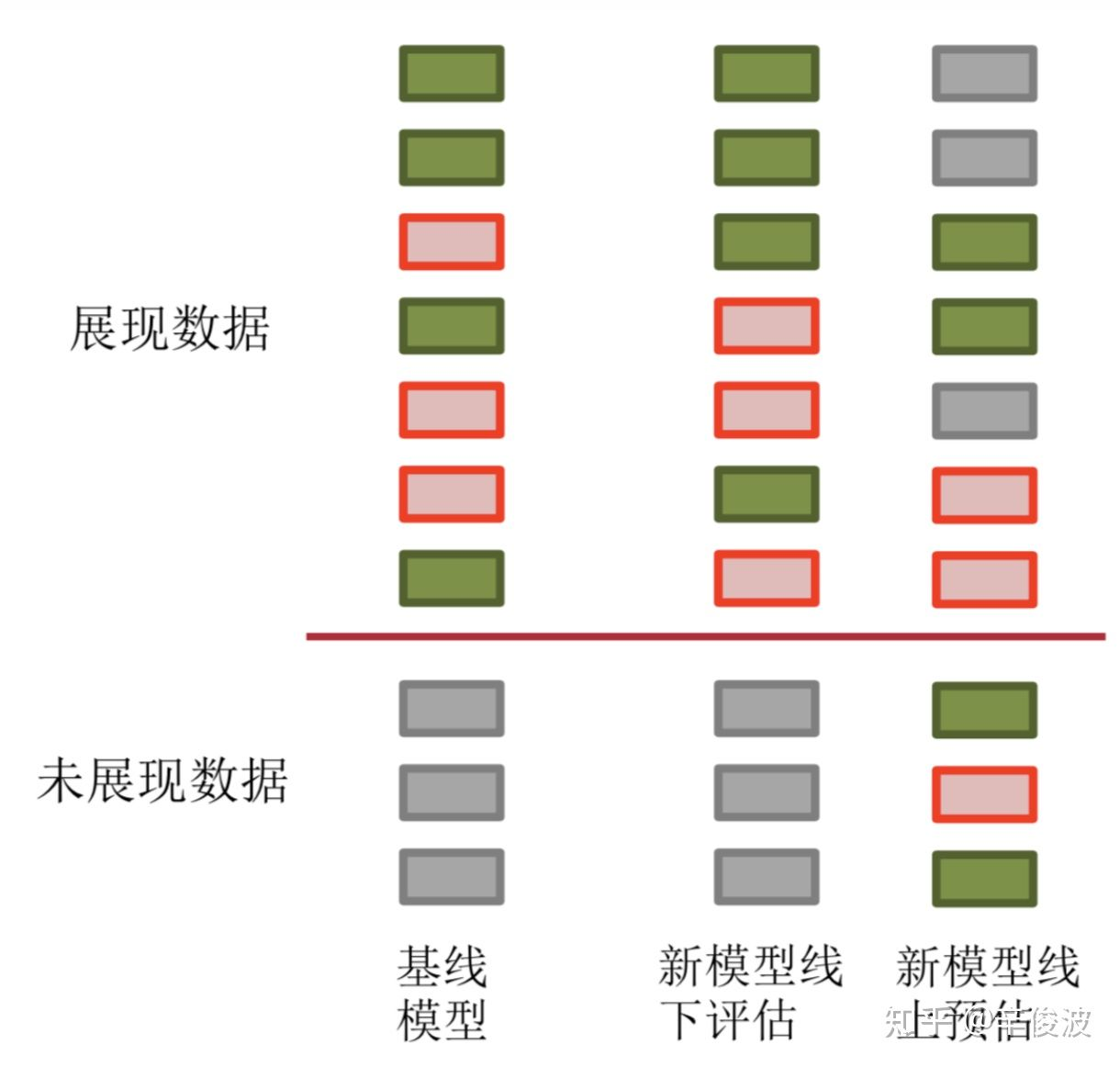
离线阶段,我们通过各种优化,新模型的离线评估表现更好了,例如图中第二列,可以发现第4个绿色的正样本和第7个绿色的正样本排到了第3和第6的位置,离线的auc指标涨了。
到了真正线上的预估也就是第三列,发现对于这部分离线见过的样本,模型的预估序并未改变。但是新模型给了灰色没有见过的数据更高的预估分数,这部分数据一旦表现不好,很可能造成我们前面说的情况,离线(第二列)评估指标明明涨了不少,在线(第三列)评估指标ctr却下降。
冰山效应在实验模型与baseline的模型相差较大时很容易造成较大的影响,比如实验模型是个性化推荐的DNN模型,而baseline是一个热门推荐的策略,这个时候新模型往往会推荐很多baseline不会展现出来的之前很少曝光的物品,而这些物品是否能够被高效点击和转化有一定的不确定性。新模型一开始相当于都是在拟合老模型产生的样本,刚上线效果如果比较差,经过一段时间迭代,影响的样本分布慢慢趋近于新模型,也能收敛,但效率较低。
缓解冰山效应的两个思路:
- 对无偏数据进行上采样
这里的无偏是相对的,可以是随机/探索流量产生的样本,也可以是新模型产生的样本。大概意思,就是尽可能利用这些对新模型有利的样本 - 线上线下模型融合
新模型预估分数 $pctr_{new}$ 和老模型预估分数 $pctr_{old}$ 直接在线上做线性融合,刚上线的时候平滑系数 $a$ 选取比较小,随着慢慢迭代,$a$ 慢慢放大。
4. 模型过拟合
假设离线评测用的测试数据是与训练数据做了隔离的,这种情况下仍然有一定的概率发生模型过拟合。
在Kaggle比赛中经常会出现模型在公开榜单(public leaderboard)上排名很高,但在切换到非公开榜单(private leaderboard)时排名很靠后的情况,这其实就是模型过拟合到公开榜单上了。如果离线我们训练了很多模型(对应不同的超参数),都是用同一个测试数据集来评估和选择模型,当这个过程重复很多次之后,最后选出来的模型有可能是过拟合到这个测试数据集上的,上线后效果就不一定好。
用测试数据集来选择模型的过程其实就相当于用测试数据集训练了一个“筛选模型”的模型,这个过程本身也是有可能过拟合的。举一个极端一点的例子,最终我们可能选择出一个在测试数据集上效果很好的模型,它能记住测试数据集中的每个样本的label,但不在测试数据集中样本全部预测错误的一无是处的模型。这也就是一些机器学习模型号称能够在benchmark数据集上识别准确率能够打败人类的原因。
5. 离线、在线评估指标不一致
在模型优化过程中,我们曾遇到过离线AUC 很高(或提升很多)但 CTR 效果不理想;或 AUC 提升幅度不大,但 CTR 提升幅度很大的情况,这是为什么呢?想要回答这个问题,我们先来看 AUC 与 CTR 的关系。
AUC指标反应的是模型把全局任意一对正负样本中的正样本排序在负样本之前的概率。离线计算AUC指标其实对应了模型对多个请求的样本之间进行排序,而点击率提升需要模型对一个请求内部的多个 Item 进行排序。模型的全局排序能力强不一定就表示同一次请求内部的item排序能力强。
GAUC(Group AUC)的指标可能更加接近线上CTR的点击偏好。这里的Group表示按照用户Session来分组评估样本。
6. 其他原因
比如说实验结果是否置信等,具体可以参考这篇文章:《推荐效果不佳时的检查清单》。
还有诸如流量抢夺,链路纠缠等原因,典型的比如在营销场景,你在前面的PUSH,短信,固定入口广告做优化,把好转化的用户都转化了。那么下游的IVR电销,人工电销一定就变难了。这时候你离线用历史数据训练的模型可能离线指标提升了,线上也不会有太多的效果。这种在一些瀑布流程的场景中更为常见,一定要关注实验的上下游变化,比较经典的方法是做MVP机制,一直维持着最优流量的AB测。这样相对提升是可以把握住的。即使小模块指标变得难看了也没关系,可能大盘整体还是变好的。

