深度学习技术已经在很多领域取得了非常大的成功,然而其调参的复杂性也导致很多机器学习从业者迷失在丛林里。本文旨在总结一些训练出一个性能优秀的深度模型的相关经验,帮助自己以及这个领域的初学者少走弯路。
激活函数
sigmoid/tanh. 存在饱和的问题,现在不建议使用。
ReLU. 最近几年常用的激活函数,形式为$f(x) = \max(0, x)$,目前建议首先尝试用这个激活函数。
- 相比于sigmoid/tanh函数而言,ReLU能极大地加快SGD算法的收敛速度,因为其分段线性的形式不会导致饱和;
- 相比于sigmoid/tanh函数而言,ReLU实现简单不需要昂贵的指数运算
- 然而,训练过程中ReLU单元可能会失效。例如,当一个非常大的梯度流经ReLU单元时,导致该单元对应的权重更新后(变得非常小)再也无法在任何数据点上激活。因此,需要小心设置学习率,较小的学习率可以缓解该问题。(太大的学习率可能会导致40%以上的ReLU单元变成dead的不可逆状态) Leaky ReLU. 函数形式为:$f(x) = \mathbb{1}(x < 0) (\alpha x) + \mathbb{1}(x>=0) (x)$,其中$\alpha$是一个小的常数。Leaky ReLU是为了修复ReLU的dying问题,然后实际使用的结果并不一致。
Maxout. 可以看作是ReLU的泛化。形式如: $\max(w_1^Tx+b_1, w_2^Tx + b_2)$
如何决定网络结构(层数和每层的节点数)
增加神经网络的层数或者节点数,模型的容量(能够表示的函数空间)会增大。下图是在一个二分类问题上不同隐层节点数的3个单隐层神经网络模型的训练结果。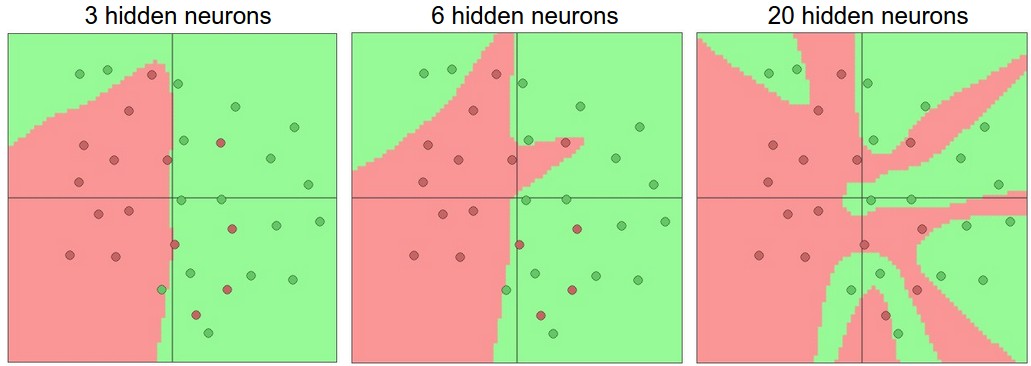
可以看出,节点数越多越能够表示复杂的函数,然而也越容易过拟合,因为高容量的模型容易捕获到训练数据噪音。如上图所示,只有隐层只有3个节点的模型的分类决策面是比较光滑的,它把那些错误分类的点认为是数据中的异常点/噪音(outlier)。实际中,这样的模型泛化性能可能更好。
那么是否意味着我们应该偏好小的模型呢?答案是否定的,因为我们有其他更好的方法来防止模型过拟合,比如说正则化、dropout、噪音注入等。实际中,更常用这些方法来对抗过拟合问题,而不是简单粗暴地减少节点数量。
这其中微妙的原因在于,小的神经网络用梯度下降算法更难训练。小的神经网络有更少的局部极小值,然而其中许多极小值点对应的泛化性能较差且易于被训练算法到达。相反,大的神经网络包含更多的局部极小值点,但这些点的实际损失是比较小的。更多内容请参考这篇论文《The Loss Surfaces of Multilayer Networks》。实际中,小的网络模型的预测结果方差比较大;大的网络模型方差较小。
重申一下,正则化是更加好的防止过拟合的方法,下图是有20个节点的单隐层网络在不同正则化强度下的结果。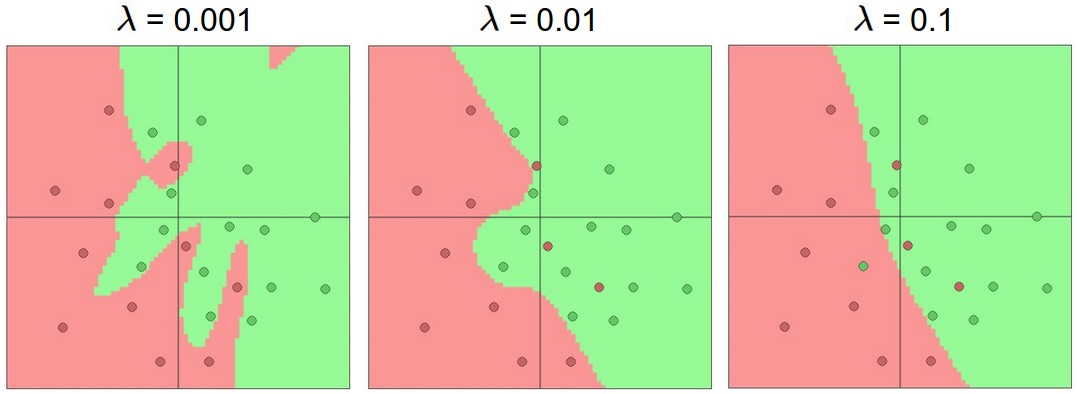
可见,合适的正则化强度可以使得一个较大的模型的决策分类面比较光滑。然而,千万要注意的是不能让正则项的值淹没了原始数据损失,那样的话梯度就主要有正则项来决定了。
因此,在计算能力预算充足的情况下,应该偏好使用大的网络模型,同时使用一些防止过拟合的技术。
数据预处理
假设有数据集为一个N * D的矩阵X,N是数据记录数,D是每条数据的维数。
减去均值。在每个特征上都把原始数据减去该维特征的均值是一种常用的预处理手段,处理之后的数据是以原点为中心的。
X -= np.mean(X, axis = 0)归一化。使得不同维度的数据有相同的scale。主要有两种归一化方法,一种是各个维度上首先减去均值后再除以标准差:
X /= np.std(X, axis = 0;另一种是最小最大标准化,这种方法归一化之后的范围在[-1,1],只有在不同维度特征数据有不同的单位或者scale时,采用这种方法才是有意义的。
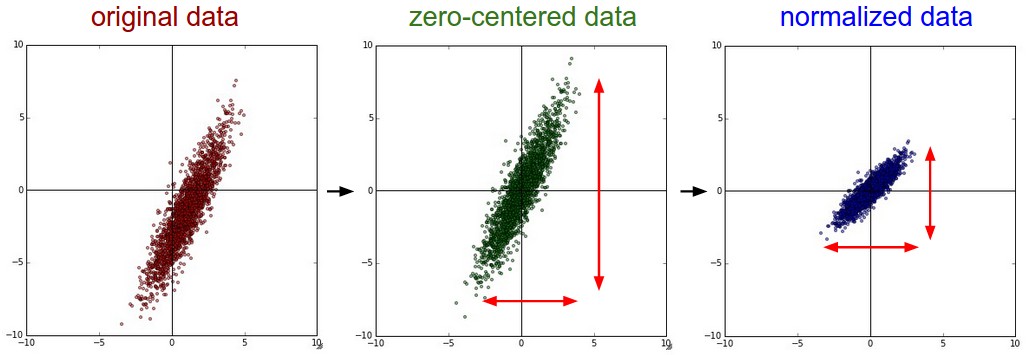
- 降维。如PCA方法、Whitening方法。这是一个可选的步骤。
注意数据预处理的陷阱。所有预处理阶段需要用到的统计数据,比如均值、标准差等,只能在训练集上计算,然后应用到包括测试集和验证集的数据上。例如,在整个数据集上计算均值,然后每条数据减去均值做数据原点中心化,最后再把数据集分裂为训练集、验证集和测试集的流程是错误的。这种类型的错误有时候被叫做数据穿透,即训练集中包含了本不该包含的数据或数据的统计特征,是机器学习从业者常犯的一种数据。比如,在做商品点击率预估时,假设我们用不包括昨天在内的前7天的日志数据作为特征提取的数据集,昨天的日志数据作为数据样本的label生成数据集,那么需要格外小心计算特征(比如,用户的偏好类目)时,千万不要把昨天的数据也统计进去。
权重初始化
神经网络权重初始化的基本原则是要打破网络结构的对称性(symmetry breaking)。比如,权重全部初始化为0是错误的,这样的话所有节点计算到的梯度值都是一样的,权重更新也是一致的,最终的结果就是所有权重拥有相同的值。
- 随机初始化为小的数值。当然也不能太小,否则计算出的梯度就会很小。
W = 0.01* np.random.randn(D,H) - 用n的平方根校正方差。
w = np.random.randn(n) / sqrt(n),其中n是输入的数量。这也意味着,权重需要逐层初始化,因为每层的节点对应的输入通常是不同的。如果节点的激活函数为ReLU,那么用sqrt(2.0/n)来校正方差更好:w = np.random.randn(n) * sqrt(2.0/n)。 - 稀疏初始化。首先把所有的权重初始化为0,然后为每个节点随机选择固定数量(比如10)的链接赋予小的高斯权重。该方法也可以打破网络结构的对称性。
- Batch Normalization。
偏置(biases)通常初始化为0。
损失函数
多分类问题的常见损失函数为:
- SVM loss:$L_i = \sum_{j\neq y_i} \max(0, f_j - f_{y_i} + 1)$
- Cross-entropy loss: $L_i = -\log\left(\frac{e^{f_{y_i}}}{ \sum_j e^{f_j} }\right)$。对应非常多类别的分类任务,交叉熵损失的计算代价是非常大的,缓解这一问题的常用方法包括Hierarchical Softmax和negative sampling。
属性分类问题(Attribute classification,即每个样本的label不止一个)的常用损失函数为:
上式中的加和是在所有类别$j$上进行的,当第i个样本有第j个类别标签时$y_{ij}$的值为1,否则为-1;当第j个类别被预测时,$f_j$的值为正,否则为负。
另一种常见的方法,是为每一个类别训练一个二分类模型,这时采用的损失为逻辑回归损失函数:,其中$y_{ij}$在模型预测为正例时值为1,预测为负例时值为0。
回归问题的损失函数:
- L2 loss: $L_i = \Vert f - y_i \Vert_2^2$
- L1 loss: $L_i = \Vert f - y_i \Vert_1 = \sum_j \mid f_j - (y_i)_j \mid$
L2损失通常比较难优化,相对于比较稳定的Softmax损失而言,因为它需要网络输出尽可能精确逼近一个值;而对于Softmax而言,每个节点输出的具体值并不是那么重要,softmax只关心它们的(相对)大小是否恰当。并且,L2损失易受异常点的影响,鲁棒性不够。
因此,当遇到一个回归问题时,首先考虑能否转化为分类问题,即可否把要回归的值划分到固定大小的桶。比如,一个评分预测任务,与其训练一个回归模型,不如训练5个独立的分类模型,用来预测用户是否给评分1~5。
When faced with a regression task, first consider if it is absolutely necessary. Instead, have a strong preference to discretizing your outputs to bins and perform classification over them whenever possible.
检查梯度
如果自己实现模型,需要做梯度的解析解和数值解的对比验证。数值解用下面的公式计算:
其中,$h$的推荐值为1e-4 ~ 1e-6。
在比较两者的差异时,使用相对误差,而不是绝对误差:
- relative error > 1e-2 usually means the gradient is probably wrong
- 1e-2 > relative error > 1e-4 should make you feel uncomfortable
- 1e-4 > relative error is usually okay for objectives with kinks. But if there are no kinks (e.g. use of tanh nonlinearities and softmax), then 1e-4 is too high.
- 1e-7 and less you should be happy.
网络越深,两者的相对误差越大。另外,为了防止数值问题,在计算过程中使用double类型而不是float类型。还需要额外注意不可导的点,比如ReLU在原点出不可导。需要在尽可能多的节点比较两者,而不只是一小部分。可以只在一部分维度上做检查。做梯度检查时,需要关闭正则项、dropout等。
训练前的检查
- 初始化权重之后,检查损失是否符合预期。比如,10个类别的分类问题,采用交叉熵损失函数,那么期望的初始数据损失(不包括正则项)为2.302左右,因为我们预计初始时每个类别被预测的概率都是0.1,因此交叉熵损失就是正确类别的负对数概率:-ln(0.1)=2.302。对于The Weston Watkins SVM损失,初始时假设有9个类别都违反了最小间隔是合理的,因此期望损失为9(因为每一个错误的列表的最小间隔为1)。
- 增加正则项强度,应该要能对应地增加损失。
- 用一小部分数据训练模型,直到模型过拟合,最终的损失为0(正则项强度设为0)。如果这项检查没有通过,就不该开始训练模型。
监控训练过程
跟踪损失的变化情况(evaluated on the individual batches during the forward pass),验证学习率是否设置合理。

跟踪正确率的变化(在训练集和验证集上分别跟踪),判断模型是否过拟合,以及模型该在什么时候停止训练。
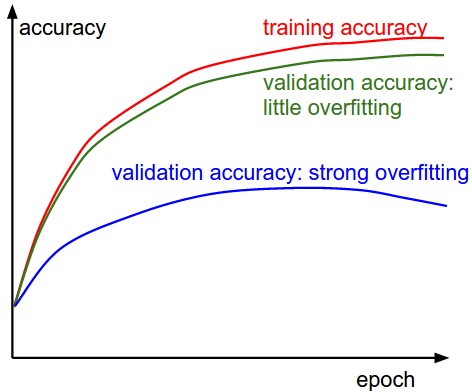
如果发生过拟合,则应加强正则化的强度,比如增加L2正则项的系数$\lambda$,或者增加dropout的概率等。当然,如果验证集的正确率和训练集的正确率一直吻合得很好也是有问题的,这意味着模型的容量可能不够,应该尝试增加更多的节点(参数)。跟踪权重更新情况,计算并记录每组参数更新的比率:$\frac{\Delta w}{w}$,这个比率应该在1e-3左右,如果比这个值小意味着学习率可能过小,反之,则应怀疑学习率是否过大。
1
2
3
4
5
6# assume parameter vector W and its gradient vector dW
param_scale = np.linalg.norm(W.ravel())
update = -learning_rate*dW # simple SGD update
update_scale = np.linalg.norm(update.ravel())
W += update # the actual update
print update_scale / param_scale # want ~1e-3跟踪每层的激活函数值分布或梯度分布,验证初始化是否正确。比如使用tanh激活函数的层,如果看到激活函数的值大量集中在0、1或者-1,则表示不正常。
如果是在处理图像任务,则可以尝试可视化第一层的权重,查看模拟的图片是否光滑、干净。
参数更新
神经网络模型的参数更新有多种方式,具体可以查看这篇文章:深度学习中的常用训练算法。
SGD+Nesterov Momentum 或者 Adam 是两种推荐的参数更新方法。
超参数优化
神经网络模型的主要超参数包括:
- 初始学习率
- 学习率衰减调度方法
- 正则化的强度
由于神经网络模型通常比较大,因此交叉验证的代价很高,通常用一折验证来代替交叉验证。
在log scale上搜索超参数是推荐的做法,比如学习率的搜索范围可以设为learning_rate = 10 ** uniform(-6, 1),正则化强度也可以采用类似的方法。这是因为学习率和正则化强度都是以乘积的形式影响代价函数的。如果学习率为0.001,那么加上0.01就会产生巨大的影响;但如果学习率为10,那么加上0.01则几乎观察不到任何影响,因此考虑学习率的范围时乘以或除以一个数,要不加上或者减去一个数更好。在另外一些参数上,则还是保留原来的量级较好,比如dropout概率:dropout = uniform(0,1)。
需要注意搜索范围的边界,如果效果在边界处最好,则可能需要修改搜索范围并重新搜索。
与Grid search相比,random search更好,据说random search效率更高。深度学习中经常发生的情况是,其中一些超参数要比另一些更加重要,与网格搜索相比随机搜索能够精确地在重要的超参数上发现更好的值。具体查看这偏论文:《Random Search for Hyper-Parameter Optimization》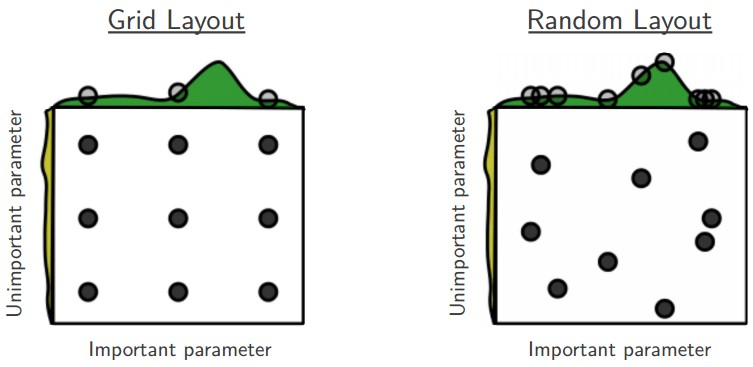
超参搜索需要分阶段,从粗粒度到细粒度分层进行。比如首先先搜索较粗的范围(e.g. 10 ** [-6, 1]),然后根据搜索到的最好的值,使用更窄的搜索范围。粗粒度搜索时,可以不用等待训练完全收敛,只需要观察前面几个epoch即可。
贝叶斯超参数优化是一个研究如何高效地探索超参数空间的研究领域,其核心思想是在不同的超参数上验证性能时做好探索和利用的平衡(exploration - exploitation trade-off)。 Spearmint,SMAC,Hyperopt是几个有名的基于贝叶斯超参数优化方法的库。
模型集成
训练几个独立的神经网络模型,用他们预测结果的平均值(或者多数表决)来确定最终的结果,是一种常用的改进性能的方法。通常集成的模型数量越多,改进的空间也越大。当然,集成彼此之间有差异化的模型更好。几种构建集成模型的常用方法如下:
- 相同的模型,不同的初始化。用交叉验证的方法确定最佳超参数,然后训练多个使用最佳超参数但不同初始化的模型。这样方法,集成的模型多样性可能不够。
- 交叉验证中发现的性能最好的多个模型。有足够的多样性,但也增加了集成进一些次优的模型的风险。
- 保留同一个模型在训练过程中的不同副本(checkpoint)。因为深度学习的训练通常都是昂贵的,这种方法不需要训练多个模型,是非常经济的。但也有缺乏多样性的风险。
- 在训练过程中平均模型的参数得到一个新的模型。在训练过程中维护一个额外的网络,它的参数取值与正式模型权重的指数衰减和(an exponentially decaying sum of previous weights during training)。相对于是维护了最近几次迭代生成的模型的移动平均,这种平滑的方法相对于是前一种方法的一种特殊实现,在实际中可以获得一到两个百分点的性能提升。对这种方法一个比较粗略的认识是,代价函数的误差超平面是一个碗状的结构,模型尝试到达碗底的位置,因此平均之后的模型更容易到家接近碗底的位置。
参考资料
Dark Knowledge from Geoff Hinton
Practical Recommendations for Gradient-Based Training of Deep Architectures from Yoshua Bengio
CS231n: Convolutional Neural Networks for Visual Recognition from Andrew Ng

