梯度下降算法是深度学习中使用得最多的优化算法。它是一种用来最小化目标函数$J(\theta)$($\theta \in \mathbb{R}^d$是模型的参数)的方法,其沿着与目标函数相对于参数的梯度$\nabla_\theta J(\theta)$相反的方向更新参数的值。形象地说,就是沿着目标函数所在的超平面上的斜坡下降,直到到达山谷(目标函数极小值)。
关于梯度下降算法的具体介绍请参考我的另一篇博文:《梯度下降算法分类及调参优化技巧》
梯度更新通常有两大类方法,一类是基于随机梯度下降及其变种的一阶方法;另一类是以牛顿方法、共轭梯度为代表的二阶近似优化方法。
基本算法
SGD
在训练数据非常多时,一般使用小批量随机梯度下降算法,也常常被简称为SGD,其更新公式如下:
其中,$\epsilon$为学习率。
动量(momentum)
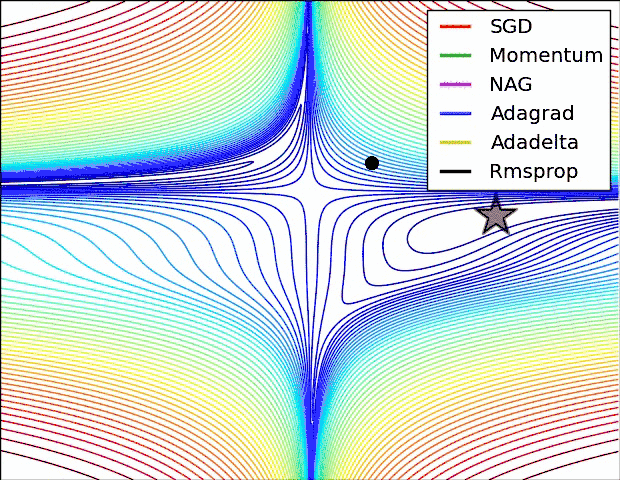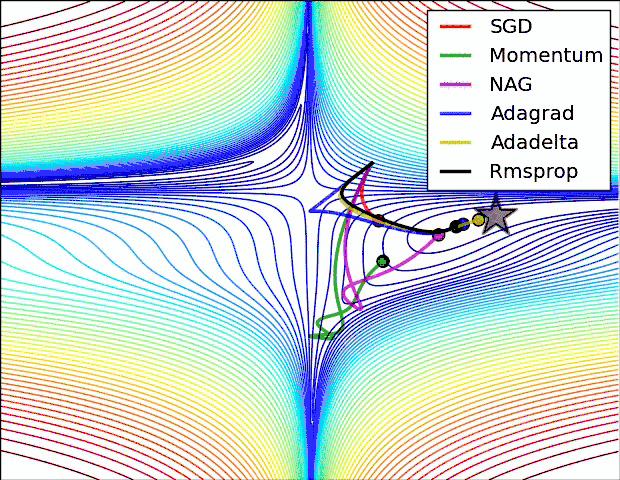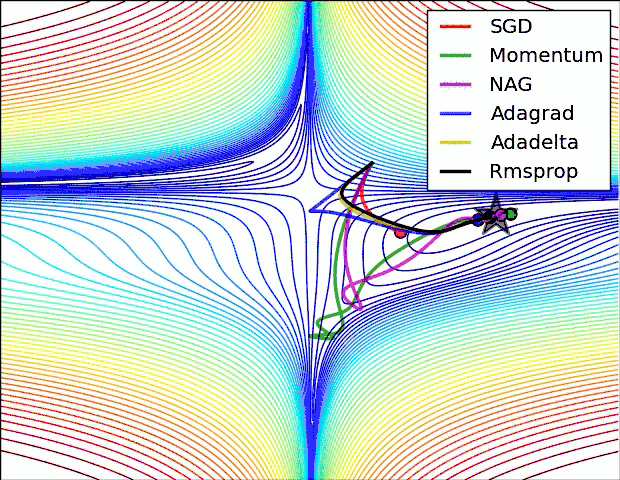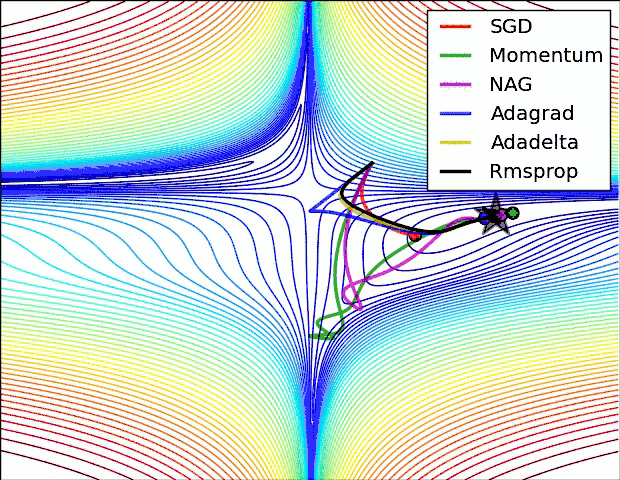
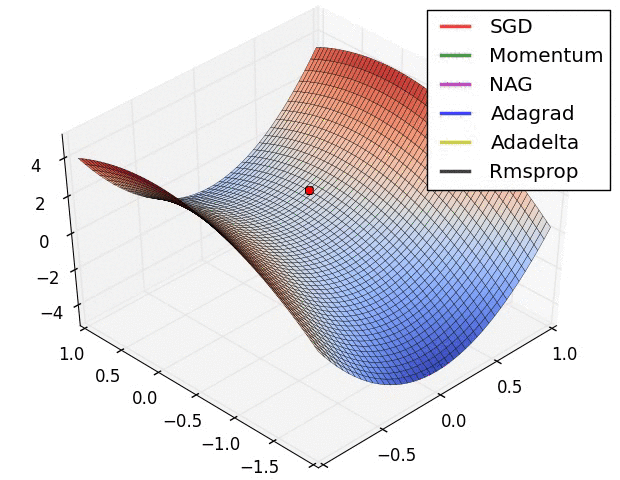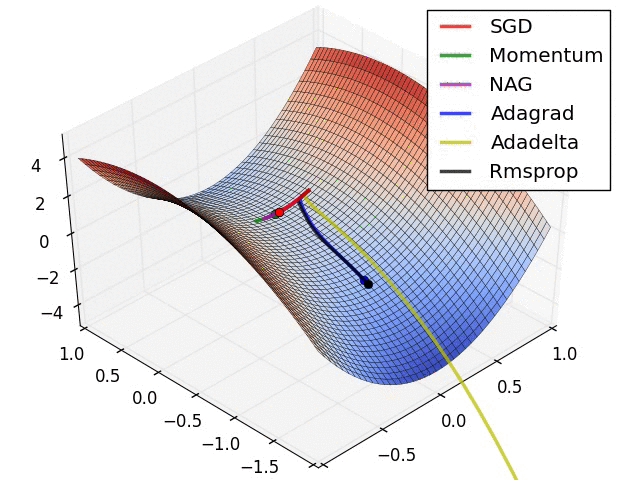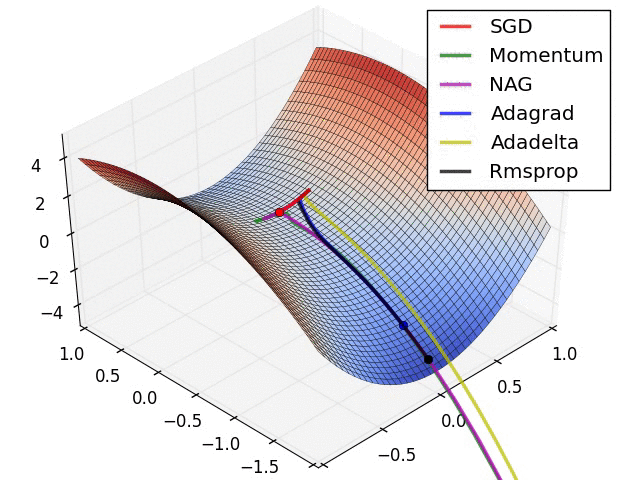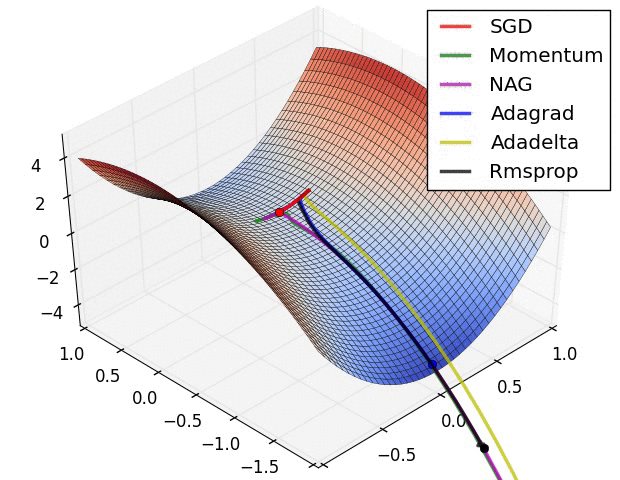
现实任务的误差超平面往往是非常复杂的,存在许多局部极小点或者鞍点,使得原生的SGD算法收敛速度较慢,且容易陷入泛化性能不太好的区域,如下图所示。
动量方法旨在加速学习,特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。动量算法积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。从形式上看,动量算法引入了变量$v$充当速度角色——它代表参数在参数空间移动的方向和速率。速度被设为负梯度的指数衰减平均。名称动量来自物理类比,根据牛顿运动定律,负梯度是移动参数空间中质点的力。动量在物理学上定义为质量乘以速度。在动量学习算法中,我们假设是质点是单位质量,因此速度向量$v$也可以看作是质点的动量。其梯度更新公式如下:
超参数$α∈[0,1)$决定了之前梯度的贡献衰减得有多快。实践中,$α$的一般取值为0.5,0.90和0.99。和学习率一样,α也可以随着时间不断调整。一般初始值是一个较小的值,随后会慢慢变大。随着时间推移调整$α$没有收缩$ϵ$重要。
形象地,当我们沿着误差超平面滚动一个小球下山时,小球的速度回越来越快,使得小球可以越过山腰上的沟壑,有机会最终到达谷底。动量项使得参数在梯度方向一致的维度上获得较大的更新,在梯度方向改变的维度上获得较小的更新。相对于SGD,可以减少参数更新过程中代价函数的抖动,获得更快的收敛速度。
Nesterov动量
沿着误差超平面滚动一个小球下山时,如果盲目地跟随斜坡下降是不能令人满意的,我们需要一个更加智能的小球,它能够知道自己如果不做任何改变时下一步将会到达什么位置,并根据此位置调整当前的动作。
基于Nesterov动量的算法,也叫做NAG(Nesterov accelerated gradient)算法,能够提供这样的预知。在动量算法中,$\theta + \alpha v_{t-1}$近似表示了参数下一步即将到达的位置,因此,我们可以基于即将到达的位置来计算梯度,即计算代价函数相对于未来一步的参数的梯度,并沿着计算出的梯度的反方向更新参数。
Nesterov动量和标准动量之间的区别体现在梯度计算上。Nesterov动量中,梯度计算在施加当前速度之后。因此,Nesterov动量可以解释为往标准动量方法中添加了一个校正因子。

如上图中的蓝线所示,在动量算法中,我们首先计算当前的梯度,然后沿着累积的梯度方向前进一大步。在Nesterov动量算法中,我们首先沿着先前累积的梯度方向前进一大步(棕色向量),再评估梯度,然后做出校正(红色向量),最终的实际效果是沿着绿色向量方向前进一步。
自适应学习率的算法
在多层网络中,代价函数的梯度大小在不同的层可能会相差很大,尤其是在网络权重初始化为很小的值的情况下。同时,节点的输出误差对节点的输入非常敏感。因此,对网络中的所有权重更新采用相同的全局学习率,在某种程度上来说,不是最好的选择。损失通常高度敏感于参数空间中的某些方向,而不敏感于其他。如果我们相信方向敏感有轴对齐的偏好,那么为每个参数设置不同的学习率,在整个学习过程中自适应地改变这些学习率是有道理的。
有些模型的部分参数可能在整个训练过程中被有效使用的频率要低于其他部分,比如在其对应的输入(特征)在大部分训练样本中都为0的情况下,代价函数对这些参数的梯度大部分时候也为0,因而这次参数的更新频率要低于其他参数。一个例子就是在训练词向量的Word2vec模型中,低频词对应的权重向量更新的频率就要低于高频词。如果我们希望对应频繁更新的参数采用较小的学习率,对不频繁更新的参数采用较大的学习率,那么也必须为网络中的每个参数设置不同的学习率。
下面介绍几种自适应学习率的算法。
AdaGrad
AdaGrad算法按照参数的历史梯度平方和的平方根的倒数来收缩学习率。
具体地,首先计算mini-batch的梯度: 然后,累积平方梯度:
接着计算更新:
其中$\epsilon$是初始学习率,$\delta$是一个很小的常数,通常设为$10^{-7}$(用于被小数除时的数值稳定)。最后,执行更新:
具有较大偏导的参数相应地有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。净效果是在参数空间中更为平缓的倾斜方向会取得更大的进步。
AdaGrad算法倾向于给很少出现的特征更多的权重,因为这些权重更新的频率较低,从而累积的平方梯度较小。
在凸优化背景中,AdaGrad算法具有一些令人满意的理论性质。然而,经验上已经发现,对于训练深度神经网络模型而言,从训练开始时积累梯度平方会导致有效学习率过早和过量的减小。AdaGrad,在某些深度学习模型上效果不错,但不是全部。
RMSProp
RMSProp算法修改AdaGrad以在非凸设定下效果更好,改变梯度积累为指数加权的移动平均。 AdaGrad旨在应用于凸问题时快速收敛。当应用于非凸函数训练神经网络时,学习轨迹可能穿过了很多不同的结构,最终到达一个局部是凸碗的区域。AdaGrad根据平方梯度的整个历史收缩学习率,可能使得学习率在达到这样的凸结构前就变得太小了。
RMSProp使用指数衰减以丢弃遥远过去的历史,使其能够在找到凸碗状结构后快速收敛,它就像一个初始化于该碗状结构的AdaGrad算法实例。
RMSProp使用指数衰减累积梯度:
相比于AdaGrad,使用移动平均引入了一个新的超参数$\rho$,用来控制移动平均的长度范围。
计算参数更新大小:
执行参数更新:
RMSProp算法还可以和动量结合在一起使用,过程如下:
- 计算临时更新:$\tilde{\theta} \leftarrow \theta + \alpha v$
- 计算梯度:$g \leftarrow \frac{1}{m} \nabla_{\tilde{\theta}} \sum_i L(f(x^{(i)};\tilde{\theta}),y^{(i)})$
- 累积梯度:$r \leftarrow \rho r + (1-\rho) g \odot g$
- 计算速度更新:$v \leftarrow \alpha v -\frac{\epsilon}{\sqrt{r}} \odot g$
- 执行更新:$\theta \leftarrow \theta + v$
AdaDelta
与RMSProp算法类似,AdaDelta算法也是为了克服AdaGrad算法过度积极地单调衰减学习率问题而做的另一种扩展。
AdaDelta算法和RMSProp算法非常类似,其提出者Matthew D. Zeiler是Hinton的亲传弟子之一,而Hinton就是RMSProp算法的提出者,因此这两个算法比较相似也就不足为怪了。
AdaDelta算法的作者注意到SGD、Momentum、AdaGrad和RMSProp等算法在参数更新时,单位并不匹配,他认为更新应该和参数应有相同的假想单位,为了实现这一想法,AdaDelta在RMSProp的基础上,还考虑了参数更新的指数衰减累积平方和:
和RMSProp算法一样,AdaDelta也需要计算指数衰减的累积梯度平方和:
AdaDelta算法每一步的参数更新为:
其中,$\delta$是一个很小的常数,用于被小数除时的数值稳定。最终的参数更新公式为:
由此可见,AdaDelta算法不需要设置初始学习率。
Adam
Adam是另一种学习率自适应的优化算法。“Adam”这个名字派生自短语”adaptive moments”。
除了维护指数衰减的累积梯度平方和,Adam还维护一份指数衰减的累积梯度和,就像momentum算法一样。其算法如下:
Require: 步长 $\epsilon$ (建议默认为: $0.001$)
Require: 矩估计的指数衰减速率, $\rho_1$ 和 $\rho_2$ 在区间 $[0, 1)$内。(建议默认为:分别为$0.9$ 和 $0.999$)
Require: 用于数值稳定的小常数 $\delta$ (建议默认为: $10^{-8}$)
Require: 初始参数 $\theta$
初始化一阶和二阶矩变量 $s = 0 $, $r = 0$
初始化时间步 $t=0$
while{没有达到停止准则}
从训练集中采包含$m$个样本$\{ x^{(1)},\dots, x^{(m)}\}$ 的小批量,对应目标为$y^{(i)}$。
计算梯度:$g \leftarrow \frac{1}{m} \nabla_{\theta} \sum_i L(f(x^{(i)};\theta),y^{(i)})$
$t \leftarrow t + 1$
更新有偏一阶矩估计: $s \leftarrow \rho_1 s + (1-\rho_1) g$
更新有偏二阶矩估计:$r \leftarrow \rho_2 r + (1-\rho_2)g \odot g$
修正一阶矩的偏差:$\hat{s} \leftarrow \frac{s}{1-\rho_1^t}$
修正二阶矩的偏差:$\hat{r} \leftarrow \frac{r}{1-\rho_2^t}$
计算更新:$\Delta \theta = - \epsilon \frac{\hat{s}}{\sqrt{\hat{r}} + \delta}$ (逐元素应用操作)
执行更新:$\theta \leftarrow \theta + \Delta \theta$
end while
Adam通常被认为对超参数的选择相当鲁棒,尽管学习率有时需要从建议的默认修改。
如何选择合适的优化算法
在这一点上并没有达成共识,还需要具体问题具体分析。下面两幅图可以提供一些关于收敛速度的参考。第一幅图展示了在代价函数误差等高线上几种不同的优化算法收敛速度情况;第二幅图展示了在遇到鞍点时,算法的鲁棒性。