提供好的特征是机器学习任务中最重要的工作,那么何为优秀的机器学习特征?以及如何高效地组合这些特征?
以二分类问题为例,好的特征具有很好的区分性。例如学习任务是区分两种不同类型的狗:灰猎犬(Greyhound)和拉布拉多犬(Labrador)。假设有身高和眼睛的颜色两种特征。一般而言,灰猎犬的平均身高要比拉布拉多犬要高一些,而狗的眼睛的颜色不取决于够的品种,因此可以认为“身高”这个特征就比“眼睛颜色”这个特征更有用,因为“眼睛颜色”这个特征没有告诉我们任何信息。
虽然灰猎犬的平均身高要比拉布拉多犬要高一些,但并不是说所有灰猎犬的身高都要比拉布拉多犬要高,那么为什么“身高”是一个有用的特征呢?假设在一个数据集D上两种类型的狗的身高分布如下图所示,其中红色表示灰猎犬,蓝色表示比拉布拉多犬。在这个数据集D上灰猎犬和拉布拉多犬各有500值,平均身高分别为28英寸和24英寸。
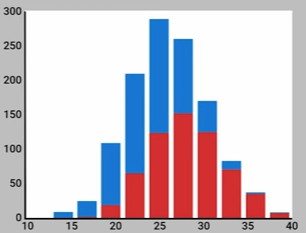
现在我们需要断定在特定的身高每种狗的概率分布。现假设有一批身高为20英寸的狗,我们该如何预测这批狗的品种,使得我们的预测错误率最低呢?根据上面的图,我们判断这批狗中的大部分可能是拉布拉多犬。同样,看图的靠右侧的柱状图,比如35英寸的身高的狗我们有信心认为其是灰猎犬。25英寸高的狗呢?这个时候我们就很难判断其是什么品种了。综上,身高是一个有用的特征,但它并不完美。一般而言,机器学习任务都很难只需要单一的特征。这就是为什么在机器学习任务里我们需要多种特征,否则就不需要机器学习算法,而只需要写if else语句就够了。Features capture different types of information。
假设一个特征的取值在二分类任务的正例和反例中各占大概一半的比例,那么这样的特征是没有用的,比如上面例子中的狗的眼睛颜色。无用的特征会降低分类器的准确率,特别是在样本数量较少的情况下。
由于不同类型的特征还应该包含不同类型的信息,这样才能够起到互相补充的作用。也就是说应该避免冗余的特征。比如“单位为英寸的身高”和“单位和厘米的身高”两个特征之间并不是相互独立的,只是同一个属性的2种不同维度的测试数据而已,因此这2个特征只要保留其中一个就可以了。应该删除与已有特征高度密切相关的特征。
最后,好的特征还应该是易于理解的。比如要预测从一个城市寄一封信去另一个城市需要多长时间可以到达,一个易于理解的特征的例子是这2座城市之间的距离;一个不易于理解的特征组合是这2个城市各种的经纬度信息。因为简单的关系更加易于学习,复杂的关系则需要更多的训练数据,因此更难被学习出来。
总结
- 避免无用的特征(avoid useless features)
- 避免冗余的特征(avoid redundant features)
- 使用易于理解的简单特征(good features should easy to understand)
好的特征具有如下的特点:
- 有区分性(Informative)
- 特征之间相互独立(Independent)
- 简单易于理解(Simple)

