为什么需要冷启动
通常推荐系统通过协同过滤、矩阵分解或是深度学习模型来生成推荐候选集,这些召回算法一般都依赖于用户-物品行为矩阵。在真实的推荐系统中,会有源源不断的新用户、新物品加入,这些新加入系统的用户和物品由于缺乏足够丰富的历史交互行为数据,常常不能获得准确的推荐内容,或被准确推荐给合适的用户。这就是所谓的推荐冷启动问题。冷启动对推荐系统来说是一个挑战,究其原因是因为现有的推荐算法,无论是召回、粗排还是精排模块,都对新用户、新物品不友好,它们往往过度依赖系统收集到的用户行为数据,而新用户和新物品的行为数据是很少的。这就导致新物品能够获得的展现机会是偏少的;新用户的兴趣也无法被准确建模。
对于某些业务来说,及时推荐新物品,让新物品获得足够的曝光量对于平台的生态建设和长期受益来说都是很重要的。比如,在新闻资讯的时效性很强,如不能及时获得展现机会其新闻价值就会大大降低;自媒体UGC平台如果不能让新发布的内容及时获得足够数量的展现就会影响内容创作者的积极性,从而影响平台在未来能够收纳的高质量内容的数量;相亲交友平台如果不能让新加入的用户获得足够多的关注,那么就可能不会有源源不断的新用户加入,从而让平台失去活跃性。
综上,冷启动问题在推荐系统中至关重要,那么如何解决冷启动问题呢?
如何解决冷启动问题
解决推荐系统的冷启动问题的算法(或策略)我总结为:“泛、快、迁、少” 四字口诀。
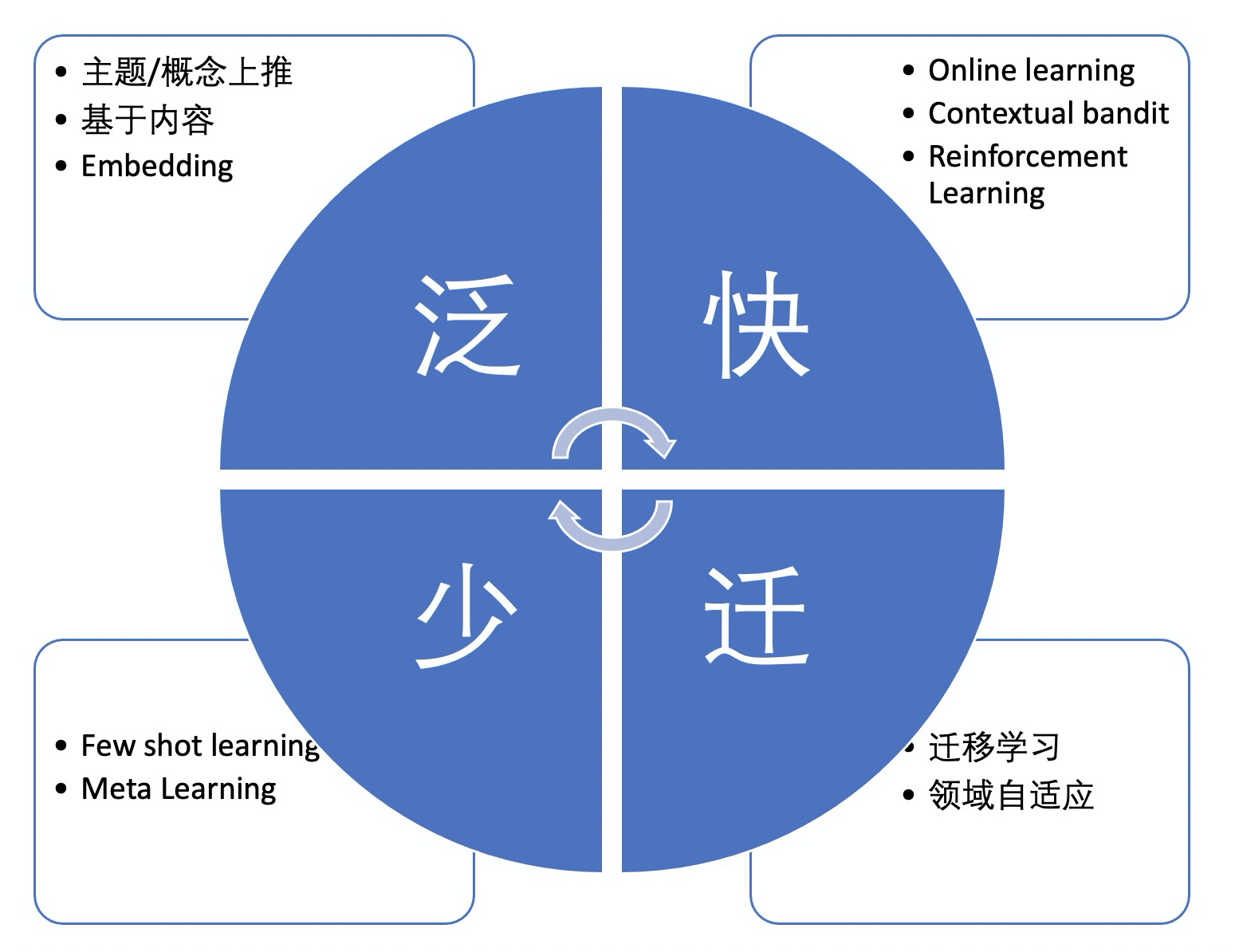
泛:即对新物品进行泛化,在属性或主题上往更宽泛的概念上靠。比如,新上架一个商品,可以推荐给以往喜欢同品类的用户,也就是从 ”商品“ 上推至 ”品类“; 新上线一个短视频,可以推荐给关注了该视频作者的用户,也就是从 ”短视频“ 上推至 ”作者“;新发布的一篇新闻资讯,可以推荐给喜欢同一主题用户,比如把介绍”歼20“的文章推荐给一个军事迷,也就是从”新闻资讯“ 上推至 ”主题“。 本质上,这是一种基于内容的推荐(Content Based Recommandation)。当然,为了更好的推荐效果,我们有时候需要同时上推至多个不同的 ”上位概念“,比如新商品除了 上推至 ”品类“,还可以上推至 ”品牌“、”店铺“、”款式“、”颜色“等。上推的概念有时候是新物品天然就具有的,这种情况比较简单,比如商品的各种属性一般在商品发布的时候商家就填好了;也有些概念并不是本来就有,比如文章的主题,这篇文章是属于”军事“、”体育“、”美妆“ 等哪个主题是需要另外的算法来挖掘的。
除了在标签或主题上的泛化,用某种算法得到用户和物品的embedding向量,再通过向量的距离/相似度来做用户和物品的兴趣匹配也是一种很常用的手段。矩阵分解、深度神经网络模型等算法都可以生成用户和物品的embedding向量,然而常规的模型还是需要依赖用户和物品的交互行为数据来建模,并不能很好地泛化到冷启动的用户和物品上。现在也有一些可以用来为冷启动用户和物品生成embedding向量的模型,比如下文要详细介绍的DropoutNet。
上推或者泛化这种方法,虽然听上去很简单,也很好理解,不过,要往深了挖,也还是有很多工作可以做的。本质上,这是在利用物品的内容(属性)信息来弥补该新物品缺少历史交互行为的问题。比如,可以使用物品的多模态信息,如图片、视频等来做相关的推荐。例如,在相亲平台,可以给新用户(这里看作被推荐的物品)的照片颜值打一个分,然后推荐给具有相关颜值偏好的用户(这里指浏览推荐列表的用户)。
快:天下武功,唯快不破。所谓的冷启动物品,也就是缺少历史用户交互行为的物品,那么一个很自然的思路就是更快地收集到新物品的交互行为,并在推荐系统里加以利用。常规的推荐算法模型和数据都是以天为单位来更新,基于实时处理系统可以做到分钟级、甚至秒级的数据及模型更新。这类的方法,通常是基于强化学习/contextual bandit 类的算法。这里给两篇参考文章,就不赘述了:《Contextual Bandit算法在推荐系统中的实现及应用》、《在生产环境的推荐系统中部署Contextual bandit算法的经验和陷阱》。
迁:迁移学习是一种通过调用不同场景中的数据来建立模型的方法。通过迁移学习可以将知识从源域迁移到目标域。比如,新开了某个业务,只有少量样本,需要用其他场景的数据来建模。此时其他场景为源域,新业务场景为目标域。再比如,有些跨境电商平台在不同的国家有不同的站点,有些站点是新开的,只有很少的用户交互行为数据,这个时候可以用其他比较成熟的其他国家的站点的交互行为数据来训练模型,并用当前国家站点的少量样本做fine-tune,也能起到不错的冷启动效果。
使用迁移学习技术要注意的是源领域与目标领域需要具体一定的相关性,比如刚说的不同国家的站点可能卖的商品有很大一部分是重叠的。
少:少样本学习(few-shot learning)技术顾名思义是只使用少量监督数据训练模型的技术。其中一直典型的少样本学习方法是元学习(meta learning)。鉴于本文的目的不是介绍这些学习技术,这样不再过多介绍,有兴趣的同学可以参考一下:《基于元学习(Meta-Learning)的冷启动推荐模型》。
本文主要介绍一种基于“泛化”的方法,具体地,我们会详细介绍一种能应用于完全冷启动场景的embedding学习模型:DropoutNet。原始的DropoutNet模型需要提供用户和物品的embedding向量作为输入监督信号,这些embedding向量通常来自其他的算法模型,如矩阵分解等;使得模型使用门槛增高。本文提出了一种端到端的训练方式,直接使用用户的交互行为作为训练目标,大大降低了模型的使用门槛。
另外,为了使模型的学习更加高效,本文在常规二分类预估模型的pointwise损失函数的基础上,增加了两种新的损失函数:一种是专注于提升AUC指标的rank loss;另一种是用于改进召回效果的Support Vector Guided Softmax Loss。后者创新性地采用了一种称之为“Negative Mining”的负采样技术,在训练过程中,自动从当前mini batch中采样负样本物品,从而扩大了样本空间,能达到更好的学习效果。
因此,本文的贡献主要有两点,总结如下:
- 本文对原始DropoutNet模型进行了改造,直接使用用户与物品的交互行为数据作为训练目标进行端到端训练,从而避免了需要使用其他模型提供用户和物品的embedding作为监督信号。
- 文本创新性地提出了一种采用多种类型的损失函数的多任务学习框架,并在训练过程中使用了Negative Mining的负采样技术,在训练过程中从当前mini batch中采样负样本,扩大了样本空间,使得学习更加高效,同时适用于训练数据量比较少的场景。
DropoutNet模型解析
NIPS 2017的文章《DropoutNet: Addressing Cold Start in Recommender Systems》介绍了一种既适用于头部用户和物品,也适用于中长尾的、甚至全新的用户和物品的召回模型。
DropoutNet是一个典型的双搭结构,用户tower用来学习用户的潜空间向量表示;对应地,物品tower用来学习物品的潜空间向量表示。当用户对当前物品具有某种交互行为,比如点击、购买时,模型的损失函数设计设定用户的向量表示与物品的向量表示距离尽可能近;当给用户展现了某物品,并且用户没有对该物品产生任何交互行为时,对应的用户、物品pair构成一条负样本,模型会尽量让对应样本中用户的向量表示与物品的向量表示距离尽可能远。
为了使模型适用于推荐系统的任何阶段,既能用来学习头部用户与物品的向量表示,又能用来学习中长尾、甚至全新的用户与物品的向量表示,DropoutNet把用户和物品的特征都分为两个部分:内容特征、偏好统计特征。内容特征相对比较稳定,不太会经常改变,并且一般在用户注册或者物品上线时就已经收集到对应的信息。另一方面偏好统计特征是基于交互行日志统计得到的特征,是动态的、会随着时间的变化而变化。全新的用户和物品由于没有对应的交互行为,因而不会有偏好统计特征。
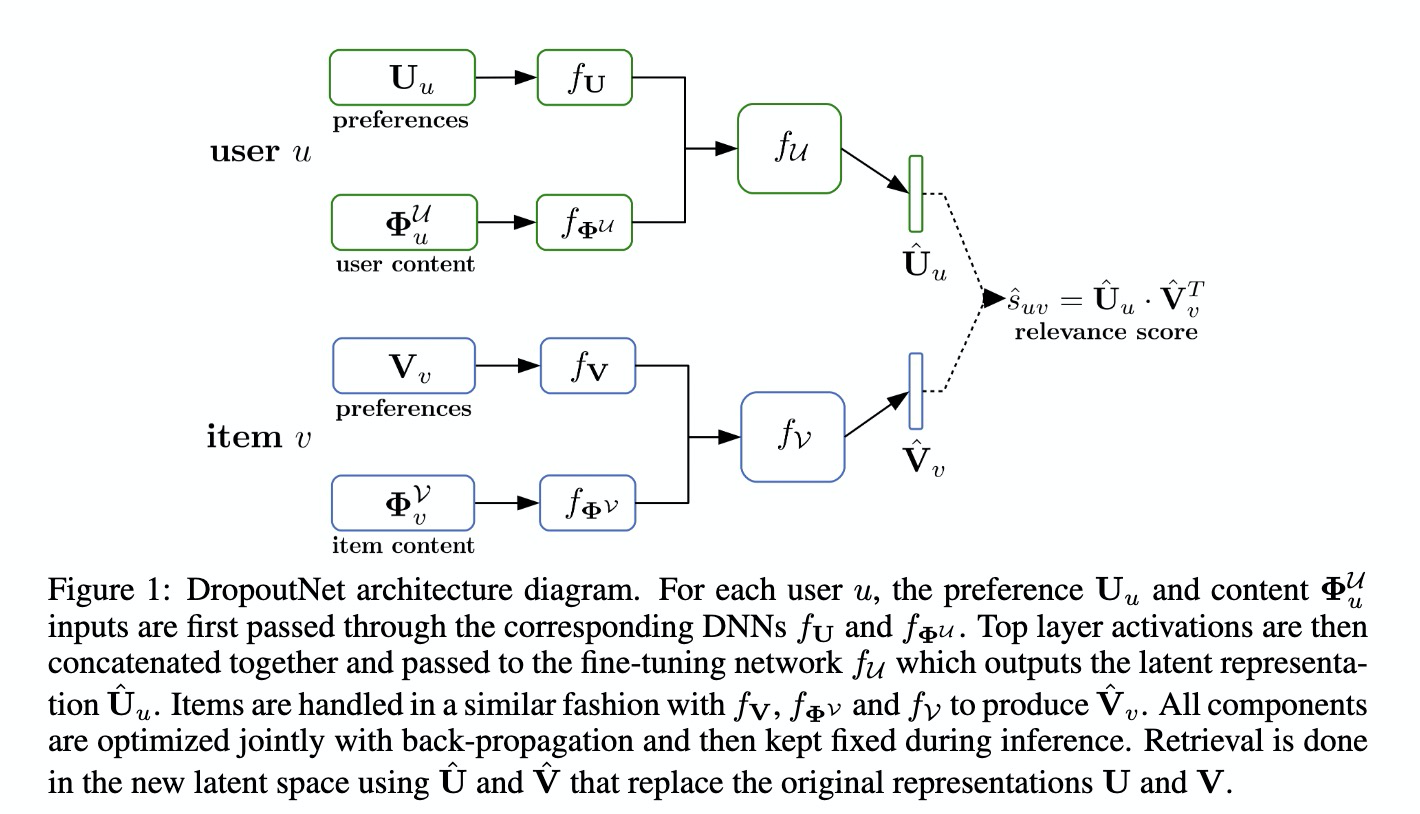
那么DropoutNet是如何使模型适用于学习全新的物品和用户向量表示的呢?其实思路非常简单,借鉴了深度学习中的dropout的思想,对输入的部分特征按照一定概率强行置为0,即所谓的input dropout。注意这里的dropout不是作用在神经网络模型的神经元上,而是直接作用在input节点上。具体地,用户和物品的偏好统计特征在学习过程中都有一定的概率被置0,而内容维度的特征则不会进行dropout操作。
根据论文的介绍,DropoutNet借鉴了降噪自动编码机(denoising autoencoder)的思想,即训练模型接受被corrupted的输入来重建原始的输入,也就是学习一个模型使其能够在部分输入特征缺失的情况下仍然能够得到比较精确的向量表示,具体地,模型是要使得在输入被corrupted的情况下学习到的用户向量与物品向量的相关性分尽可能接近输入在没有被corrupted的情况下学习到的用户向量与物品向量的相关性分。
目标函数为:
其中,$\hat{U}_u$是模型学到的用户向量表示, $\hat{V}_v$是模型学到的物品向量表示;$U_u$和$V_v$分别是外部输入的、作为监督信号的用户和物品向量表示,一般是通过其他模型学习得到。
为了使模型适用于用户冷启动场景,训练过程中对用户的偏好统计特征进行dropout:
为了使模型适用于物品冷启动场景,训练过程中对用户的偏好统计特征进行dropout:
DrouputNet模型的学习过程如算法1所示:

端到端训练改造
DropoutNet模型的一大弊端是需要提供用户和物品的embedding向量作为监督信号。模型通过dropout的方式mask掉一部分输入特征,并试图通过部分输入特征学习到能够重建用户与物品embedding向量相似度的向量表示,原理类似于降噪自动编码机。这就意味着我们需要另一个模型来学习用户与物品的embedding向量,从整个流程来看是需要分两阶段来完成学习目标,第一阶段训练一个模型得到用户与物品的embedding向量,第二阶段训练DropoutNet模型得到更加robust的向量表示,并且能够适用于全新的冷启动用户和物品。
为了简化训练流程,我们提出了一种端到端训练的方式,在新的训练方式下,不再需要提供用于和物品的embedding向量作为监督信号,取而代之,我们使用用户与物品的交互行为作为监督信号。比如,类似于点击率预估模型,如果用户点击了某物品,则该用户与物品构成正样本;那些展现给用户但却没有被点击的商品构建成负样本。通过损失函数的设计,可以使模型学习到正样本的用户与物品向量表示的相似度尽可能高,负样本的用户与物品的向量表示的相似度尽可能低。例如,可以使用如下的损失函数:
其中,$y \in \{0, 1\}$ 是模型拟合的目标;$v^+$表示与用户$u$有交互行为的物品;$v^-$表示与用户$u$没有交互行为的物品。
在线负采样 & 损失函数
作为一个推荐系统召回阶段的模型,如果只是使用曝光日志来构建训练样本是不够的,因为通常情况下用户只能被展现一小部分物品,平台上大部分物品可能从未对当前用户曝光过,如果这些未曝光的物品不与当前用户构建成样本,则模型的只能探索到潜在样本空间的很小一部分,使得模型的泛化性能较弱。
样本负采样是召回模型常用的技术,也是保证模型效果的关键。负采样有多种方法,可以参考Facebook的论文《Embedding-based Retrieval in Facebook Search》,这里不再赘述。下面仅从实现的角度来谈谈具体如何做样本负采样。
样本负采样通常有两种做法,如下表所示。
| 负采样方法 | 优点 | 缺点 |
|---|---|---|
| 离线负采样 | 实现简单 | 样本空间有限、训练速度较慢 |
| 在线负采样 | 训练时动态拓展样本空间,训练较快速 | 实现较复杂 |
在线样本负采样也有不同的实现方式。比如可以用一个全局共享内存来维护待采样的物品集,这种方式的一个缺点是实现起来比较复杂。一般情况下,我们都会收集汇聚多天的用户行为日志用来构建样本,样本的总量是很大的,无法全部放入内存中。同一个物品出现在多天的样本中时,对应的统计特征也是不同的,稍有处理不当就可能发生特征穿越的问题。
另一种更讨巧的实现方式是从当前mini-batch中采样。因为训练数据需要全局混洗(shuffle)之后再用来训练模型,这样每个mini-batch中的样本集都是随机采样得到的,当我们从mini-batch中采样负样本时,理论上相当于是对全局样本进行了负采样。这种方式实现起来比较简单,本文就是采用这种在线采样的方法。
具体地,训练过程中,用户、物品特征执行完网络的forward阶段后,得到了用户embedding、物品embedding,接下来我们通过对物品embedding矩阵(batch_size * embedding_size)做一个按行偏移操作(row-wise roll),把矩阵的行(对应物品embedding)整体向下移动 N 行,被移出矩阵的N行再重现插入到矩阵最前面的N行,相当于是在一个循环队列中依次往一个方向移动了N步。这样就得到了一个负样本的用户物品pair $< u, i_1^{-} >$,重复上述操作M次就得到了M个负样本pair。
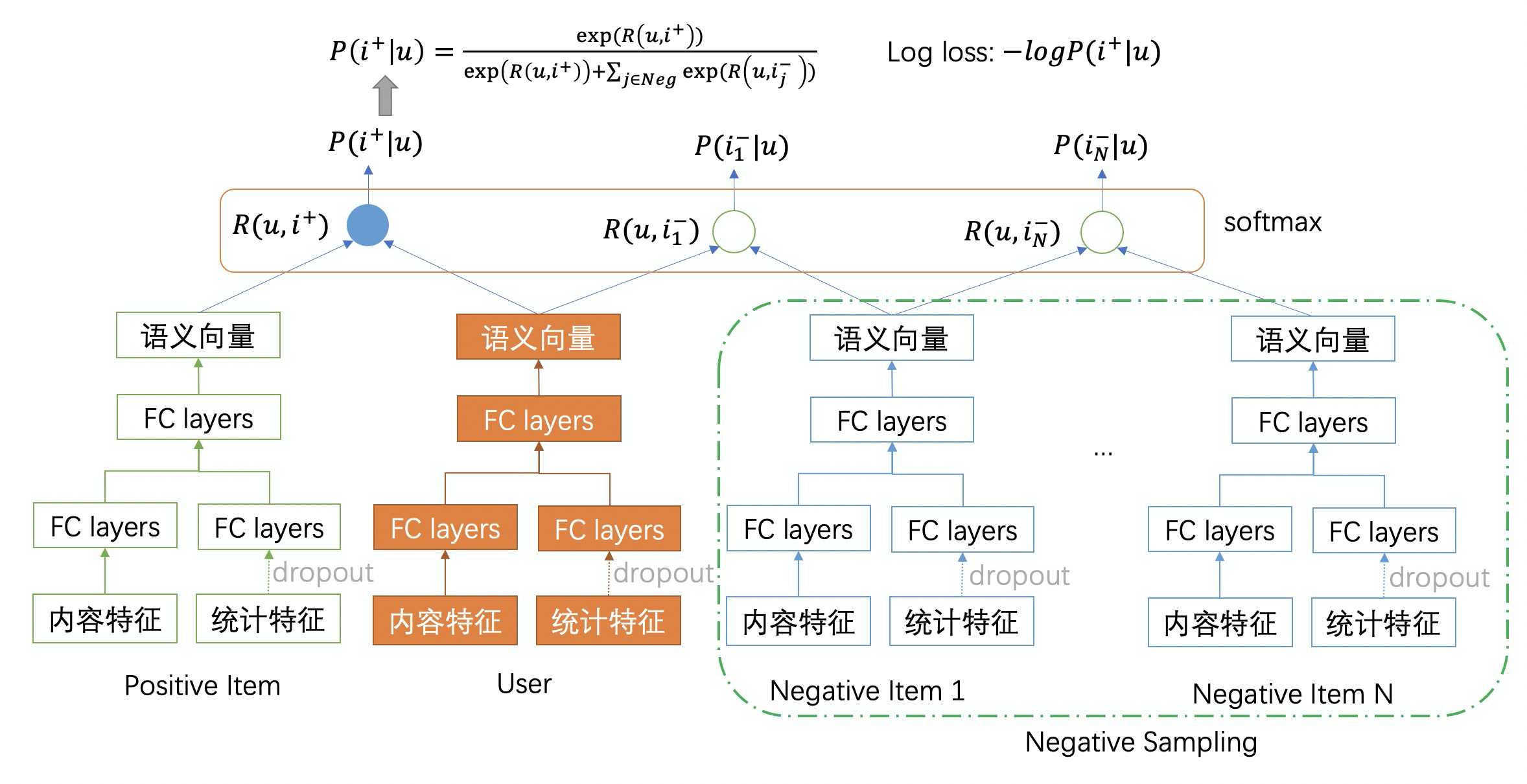
改造后的DropoutNet网络如上图所示。首先,计算用户语义向量与正样本物品的余弦相似度,记为 $R(u,i^+)$;然后计算用户语义向量与$N$个负样本物品的余弦相似度分别记为$R(u,i_1^-),\cdots,R(u,i_N^-)$,对这$N+1$个相似度分数做softmax变换,得到用户对物品的偏好概率;最后损失函数为用户对正样本物品的偏好概率的负对数,如下:
更进一步,我们参考了论文《Support Vector Guided Softmax Loss for Face Recognition》的思路,在实现softmax损失函数过程中引入了最大间隔和支持向量的做法,通过在训练过程中使用“削弱正确”和“放大错误”的方式,强迫模型在训练时挑战更加困难的任务,使得模型更高鲁棒,在预测阶段可以轻松做出正确判断。
基于负采样的support vector guided softmax loss的tensorflow实现代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86def softmax_loss_with_negative_mining(user_emb,
item_emb,
labels,
num_negative_samples=4,
embed_normed=False,
weights=1.0,
gamma=1.0,
margin=0,
t=1):
"""Compute the softmax loss based on the cosine distance explained below.
Given mini batches for `user_emb` and `item_emb`, this function computes for each element in `user_emb`
the cosine distance between it and the corresponding `item_emb`,
and additionally the cosine distance between `user_emb` and some other elements of `item_emb`
(referred to a negative samples).
The negative samples are formed on the fly by shifting the right side (`item_emb`).
Then the softmax loss will be computed based on these cosine distance.
Args:
user_emb: A `Tensor` with shape [batch_size, embedding_size]. The embedding of user.
item_emb: A `Tensor` with shape [batch_size, embedding_size]. The embedding of item.
labels: a `Tensor` with shape [batch_size]. e.g. click or not click in the session. It's values must be 0 or 1.
num_negative_samples: the num of negative samples, should be in range [1, batch_size).
embed_normed: bool, whether input embeddings l2 normalized
weights: `weights` acts as a coefficient for the loss. If a scalar is provided,
then the loss is simply scaled by the given value. If `weights` is a
tensor of shape `[batch_size]`, then the loss weights apply to each corresponding sample.
gamma: smooth coefficient of softmax
margin: the margin between positive pair and negative pair
t: coefficient of support vector guided softmax loss
Return:
support vector guided softmax loss of positive labels
"""
batch_size = get_shape_list(item_emb)[0]
assert 0 < num_negative_samples < batch_size, '`num_negative_samples` should be in range [1, batch_size)'
if not embed_normed:
user_emb = tf.nn.l2_normalize(user_emb, axis=-1)
item_emb = tf.nn.l2_normalize(item_emb, axis=-1)
vectors = [item_emb]
for i in range(num_negative_samples):
shift = tf.random_uniform([], 1, batch_size, dtype=tf.int32)
neg_item_emb = tf.roll(item_emb, shift, axis=0)
vectors.append(neg_item_emb)
# all_embeddings's shape: (batch_size, num_negative_samples + 1, vec_dim)
all_embeddings = tf.stack(vectors, axis=1)
mask = tf.greater(labels, 0)
mask_user_emb = tf.boolean_mask(user_emb, mask)
mask_item_emb = tf.boolean_mask(all_embeddings, mask)
if isinstance(weights, tf.Tensor):
weights = tf.boolean_mask(weights, mask)
# sim_scores's shape: (num_of_pos_label_in_batch_size, num_negative_samples + 1)
sim_scores = tf.keras.backend.batch_dot(
mask_user_emb, mask_item_emb, axes=(1, 2))
pos_score = tf.slice(sim_scores, [0, 0], [-1, 1])
neg_scores = tf.slice(sim_scores, [0, 1], [-1, -1])
loss = support_vector_guided_softmax_loss(
pos_score, neg_scores, margin=margin, t=t, smooth=gamma, weights=weights)
return loss
def support_vector_guided_softmax_loss(pos_score,
neg_scores,
margin=0,
t=1,
smooth=1.0,
threshold=0,
weights=1.0):
"""Refer paper: Support Vector Guided Softmax Loss for Face Recognition (https://128.84.21.199/abs/1812.11317)."""
new_pos_score = pos_score - margin
cond = tf.greater_equal(new_pos_score - neg_scores, threshold)
mask = tf.where(cond, tf.zeros_like(cond, tf.float32),
tf.ones_like(cond, tf.float32)) # I_k
new_neg_scores = mask * (neg_scores * t + t - 1) + (1 - mask) * neg_scores
logits = tf.concat([new_pos_score, new_neg_scores], axis=1)
if 1.0 != smooth:
logits *= smooth
loss = tf.losses.sparse_softmax_cross_entropy(
tf.zeros_like(pos_score, dtype=tf.int32), logits, weights=weights)
# set rank loss to zero if a batch has no positive sample.
loss = tf.where(tf.is_nan(loss), tf.zeros_like(loss), loss)
return loss
Pairwise Ranking
Pointwise, pairwise和listwise是LTR(Learning to Rank)领域为人熟知的三种优化目标,早在深度学习时代之前,做IR的研究者就已经发展了一系列基本方法,比较经典的工作可以参考 《Learning to Rank Using Gradient Descent》 和 《Learning to Rank- From Pairwise Approach to Listwise Approach》这两篇。
Pairwise的重要意义在于让模型的训练目标和模型实际的任务之间尽量统一。对于一个排序任务,真实的目标是让正样本的预估分数比负样本的高,对应了AUC这样的指标。在pairwise的经典论文RankNet中,pairwise的优化目标被写成了,
这里$P_{ij}$代表模型预估样本$i$比$j$更“相关”的概率,其中$f(x_i)-f(x_j)$是两条样本模型pointwise输出logit的差值;$y_{ij}=max(y_i-y_j,0), y_i \in \{0, 1\}, y_j \in \{0, 1\}$。直观上理解,优化$C_{ij}$就是在提高模型对于任意正样本分数比任意负样本分数高的概率,也即AUC, 所以这种形式的pairwise loss也被称为AUC loss。
同样,为了方便实现,以及减少离线构建pair样本的工作量,我们选择了In-batch Random Pairing的方式在训练过程中,从mini batch内构建pair来计算pairwise rank loss。具体实现代码如下:
1 | def pairwise_loss(labels, logits): |
源代码:https://github.com/alibaba/EasyRec/blob/master/easy_rec/python/loss/pairwise_loss.py
模型实现开源代码
我们在阿里云机器学习PAI团队开源的推荐算法框架EasyRec中发布了DropoutNet的源代码。使用文档请查看:https://easyrec.readthedocs.io/en/latest/models/dropoutnet.html。
EasyRec是一个易于使用的推荐算法模型训练框架,它内置了很多最先进的推荐算法模型,包括适用于推荐系统召回、排序和冷启动阶段的各种算法。可以跑在本地、DLC、MaxCompute、DataScience等多个平台上,支持从各种存储媒介(local、hdfs、maxcompute table、oss、kafka)中加载各种格式类型(text、csv、table、tfrecord)的训练和评估数据。EasyRec支持多种类型的特征,损失函数,优化器及评估指标,支持大规模并行训练。使用EasyRec,只需要配置config文件,通过命令调用的方式就可以实现训练、评估、导出、推理等功能,无需进行代码开发,帮您快速搭建推广搜算法。
欢迎加入【EasyRec推荐算法交流群】,钉钉群号 : 32260796。
EasyRec Github代码仓库:https://github.com/alibaba/EasyRec/
参考资料
- DropoutNet 论文
- Support Vector Guided Softmax Loss for Face Recognition
- Embedding-based Retrieval in Facebook Search
- Learning to Rank Using Gradient Descent
- Learning to Rank- From Pairwise Approach to Listwise Approach
- EasyRec DropoutNet 模型使用指南

