我们在基于深度学习的语义相似度模型系列文章的开篇《深度学习语义相似度系列:概论》中介绍了两种语义相似度的学习范式,其中第一种范式的重点是表示学习,也就是为输入对象学习一个低维稠密的embedding向量,使得基于此embedding向量计算的相似度能够很好地反映原始对象之间的相似性。本文主要介绍一种在第一范式下的相似度学习模型的设计。
相似度度量建模
一般而言,相似度度量可以建模为回归问题,也可以建模为分类问题,甚至可以建模为排序问题。取决于我们有什么格式的标签数据。
回归相似性学习
给定一对输入 $(x_{i}^{1},x_{i}^{2})$ 以及它们的相似性度量值 $y_{i}\in R$. 回归相似性学习的目标是在三元组$(x_{i}^{1},x_{i}^{2},y_{i})$训练数据集上学习一个近似函数 $f(x_{i}^{1},x_{i}^{2})\sim y_{i}$。这通常通过最小化一个带正则项的损失函数来达成目标 $\min _{W}\sum _{i}loss(w;x_{i}^{1},x_{i}^{2},y_{i})+reg(w)$。
分类相似性学习
假设我们拥有的训练数据为一组成对的相似对象$(x_{i},x_{i}^{+})$集合和不相似对象$(x_{i},x_{i}^{-})$集合,训练数据可以等价地描述为对于每一个成对的输入对象$(x_{i}^{1},x_{i}^{2})$,关联一个二值标签$y_{i}\in \{0,1\}$,标签表示输入的两个对象是否相似。分类相似性学习的目标是学习一个分类器来预测相似度。
排序相似性学习
相似度度量建模为回归或者分类问题虽然简单,但很多时候我们没有合适的带有标签的监督数据可用,而且人工标注的代价又很高。这时我们可以考虑把相似性度量问题建模为排序问题。
具体地,假设我们有一个由三元组$(x_{i},x_{i}^{+},x_{i}^{-})$构成的数据集,其中每个三元组代表了一个预先定义好的偏序关系:$x_{i}$与$x_{i}^{+}$的相似度大于于$x_{i}^{-}$的相似度。排序相似性学习的目标是学习一个相似性度量函数$f$,使得对于一个新的三元组有$f(x,x^{+})>f(x,x^{-})$成立。
排序相似性学习相比回归相似性学习和分类相似性学习而言,其对监督信号的假设更弱。通常,我们可以更容易地获得偏序关系,比如很多电商平台会在商品详情页页面推荐一些与当前被浏览的商品相似的商品,这这些推荐商品列表中有些会被用户点击,另一些却不会,那么这些被点击的商品相对于没有被点击的商品就构成了很多组偏序关系:当前浏览商品与被点击的商品之间的相似度大于与没有被点击商品之间的相似性。
当然,无论采用哪一种建模方法,在深度模型学习到决策函数的同时,我们都可以同时得到输入对象的表示向量。
无监督学习偏序关系,构建模型训练数据
假设在电商业务场景中,我们的目标是要判断任意两个商品的相似度。首先,我们需要构建训练数据。假设我们决定把相似度判定问题建模为上述排序相似性学习问题,则我们需要有一批商品相似度偏序关系数据。
在推荐系统中,早有人研究过如何度量商品之间的相似性,比如基于商品点击二部图数据,通过余弦相似度、SimRank++算法、Swing算法等无监督方法计算。
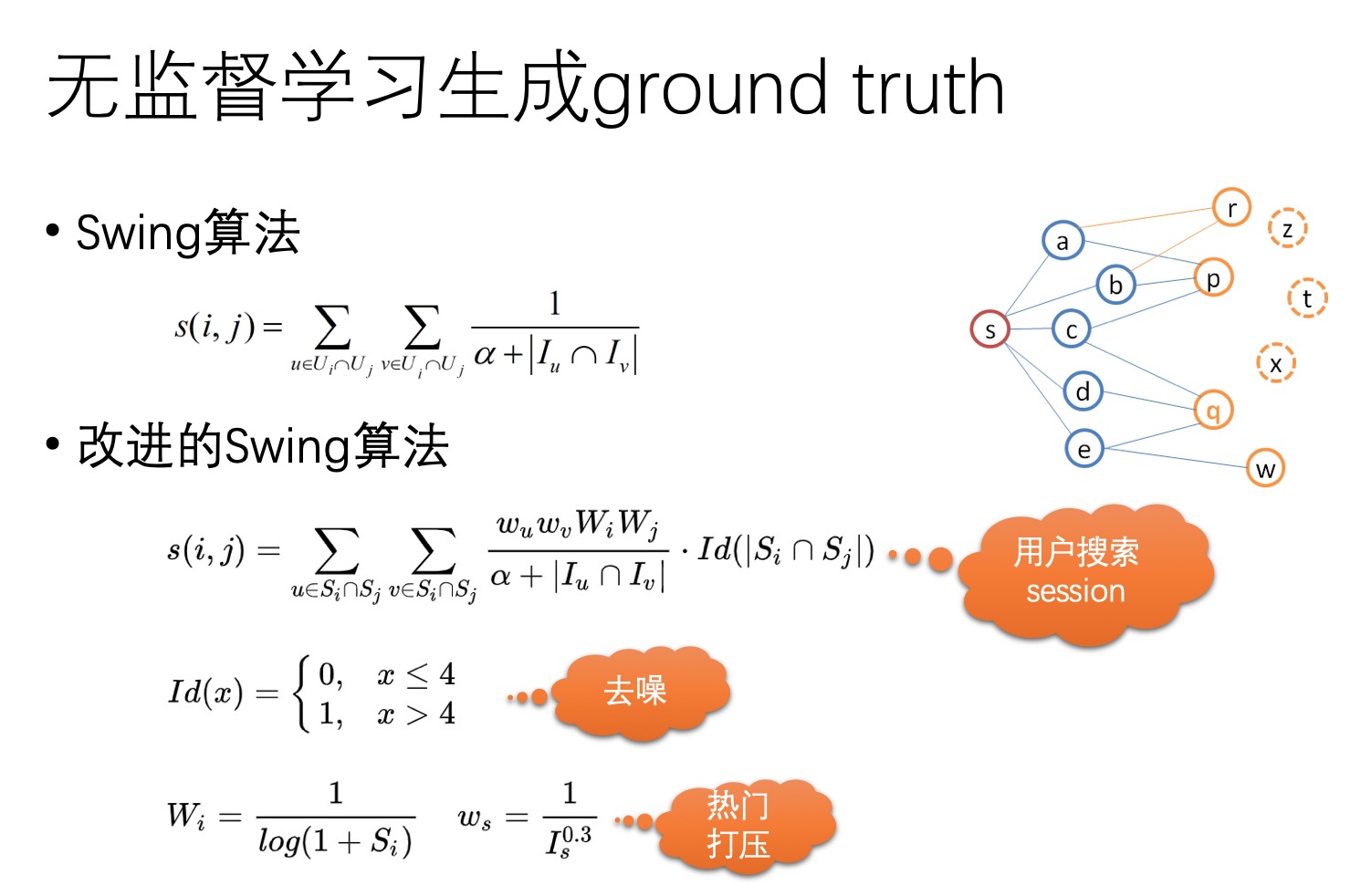
既然我们可以通过无监督算法计算商品相似度,为什么还需要一个相似性度量模型?本质原因是基于点击二部图计算的商品相似度覆盖率不足,即我们只能计算曝光率较高的热门商品之间的相似度。由于马太效应,电商平台上通常还存在大量的长尾商品未能得到充分的曝光,因而这些商品也未能积累到充分的用户行为数据。对于这些商品,我们无法通过无监督的方式计算其相似度,因而需要一个模型能够把相似度度量推广到任意两个商品上。
在热门商品上通过无监督方式计算的商品相似性数据可以用来构建相似度模型的训练数据。有了训练数据,我们就可以学习相似性模型了。
排序相似性模型
下面我们通过对DSSM模型做一些改造来显式建模相似度偏序关系。
DSSM模型是微软与2013年提出来的深度语义匹配模型,最初是在检索系统中用来计算查询与文档之间的相关性。模型结构如下图所示:

DSSM模型的输入由一个查询$Q$,一个相关文档$D^+$,若干个不相关文档$\{D_i^-\}$组成,其中相关文档来自于查询$Q$下被点击的文档,不相关文档采样自查询$Q$的展示文档列表中没有被点击的文档。
DSSM模型是一个多塔结构,每个塔的结构都相同,参数也共享,是一个典型的孪生网络。每个子网络负责把输入文本转换为特定大小的语义向量,具体子网络的结构有很多变种,有MLP,也有CNN或者RNN等结构。在得到输入文本的语义向量后,模型计算Query和各个Doc之间的语义相似性:
接着,通过softmax函数可以把Query与正样本$D^+$的语义相似性转化为一个后验概率:
在训练阶段,通过极大似然估计,我们最小化损失函数:
这样的损失函数是在要求模型学会一个知识,就是Query与正样本$D^+$的语义相似性大于Query与任意负样本$D_i^-$的语义相似性,即 $similarity(Q,D^+)>similarity(Q,D_i^-)$。
个人觉得DSSM模型能否成功应用于其他业务场景,跟负样本的选择有很大的关系。随机采样负样本通常不是一个好的策略,是因为随机采样的负样本与Query之间的相似度通常很低,因而要让模型学会$similarity(Q,D^+)>similarity(Q,D_i^-)$就很容易。如果模型在训练阶段只见过比较容易的样本,那么在应用阶段就很难正确预测比较难的样本。然而,在实际业务场景中,我们通常需要模型能够正确预测比较困难的样本,比如在检索系统的排序阶段,我们已经通过相关性模型在召回阶段过滤掉了大量不相关的文档,剩下需要排序的文档与Query都有某种程度的相关性,这时候我们希望模型能够区分哪些文档与Query更相关。这就是为什么DSSM模型的每个训练样本中若干个不相关文档$\{D_i^-\}$采样自查询$Q$的展示文档列表中没有被点击的文档,而不是随机采样一批文档。
当我们用DSSM模型来训练商品语义相似度时,该如何构建训练样本呢?通过无监督的方法我们已经有了一批商品相似数据。针对一个锚定的商品Anchor,通过相似数据可以找到一个相似的正样本,记为Positive,如果再随机采样若干个商品作为负样本,记为{Negative},那么我们就构建了形如DSSM模型的训练样本,是否可以开始训练模型了呢?
通常情况下,这样构建的训练样本用来训练模型,效果都不能让人满意,原因正如我上面分析的那样,就是在训练阶段,正负样本太容易区分,也就是说偏序关系$similarity(Anchor,Positive)>similarity(Anchor,Negative)$很容易被模型学会。然而,在应用阶段,需要计算相似度的商品分布跟训练时的分布明显不同,我们希望模型能够在一堆都比较相似的商品中识别出谁与目标商品更相似,而不是从一堆大多数商品都与目标商品不相似的商品中识别出哪几个商品是相似的。上升到理论角度,通过上述方式构建的训练样本分布与应用阶段的样本分布是不一致的,违背了机器学习的独立同分布假设,因而效果不佳就是很自然的事情了。
那么该如何构建有效是训练样本呢?所幸的是,通过无监督方法我们不仅仅学习到了商品对之间的相似度,我们还得到了与一个目标商品相似的商品列表,列表中的每个商品都可以度量其与目标商品的相似度。我们可以从相似商品列表中采样训练样本: $\langle A,H,L,N_1,N_2,N_3,\cdots \rangle$,其中$A$表示目标商品;$H$表示与目标商品有较高相似度的商品;$L$表示与目标商品也相似,但是相似程度不如$H$的商品;$N_i$是随机参样的商品,作为负样本。相似度偏序关系$similarity(A,H)>similarity(A,L)$,建模了较困难的相似关系;$similarity(A,H)>similarity(A,N_i)$建模了较容易的相似关系,这样构建的样本是无偏的。
改造之后的模型结构如下图所示:![]()
损失函数
我们当然还是可以继续使用公式$\eqref{eq:loss}$定义的损失函数,只需要让训练样本中的商品L也当成是其中一个负样本即可。商品L只是起到了增加样本困难度的作用。
当然有很多基于softmax函数的魔改loss函数,我们都可以拿过来用。这里介绍一个基于支持向量的间隔softmax损失函数(Support vector guided margin softmax loss),定义如下图所示:

出发点是要使得商品$A$与商品$H$之间的相似性至少比商品$A$与商品$L$之间的相似性高出至少$m$,即$similarity(A,H)>similarity(A,L)+m$;同时商品$A$与商品$H$之间的相似性至少比商品A与商品$N_i$的相似性高出至少$m+m_2$,即$similarity(A,H)>similarity(A,N_i)+m+m2$。
另外,该损失函数同样要求商品H与目标商品之间的相似度比其他所有商品跟目标商品的相似度都要高,当这一要求未能被满足时,该损失函数通过一个额外的惩罚系数$t$迫使模型更加关注相似度关系未能被满足的样本。具体原理,可参看论文《Support Vector Guided Softmax Loss for Face Recognition》。
当样本、模型、损失函数都合理定义好之后,就可以开始训练模型了。
关注微信公众号“算法工程师的进阶之路”,后台回复“语义相似度”获取完整源代码。 如果觉得本文对您有帮助,请帮忙点个赞!
参考资料
- Similarity_learning
- Support Vector Guided Softmax Loss for Face Recognition

