本文是“基于Tensorflow高阶API构建大规模分布式深度学习模型系列”的第五篇,旨在通过一个完整的案例巩固一下前面几篇文章中提到的各类高阶API的使用方法,同时演示一下用tensorflow高阶API构建一个比较复杂的分布式深度学习模型的完整过程。
文本要实现的深度学习模式是阿里巴巴的算法工程师18年刚发表的论文《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》中提出的ESMM模型,关于该模型的详细介绍可以参考我之前的一篇文章:《CVR预估的新思路:完整空间多任务模型》。
ESMM模型是一个多任务学习(Multi-Task Learning)模型,它同时学习学习点击率和转化率两个目标,即模型直接预测展现转换率(pCTCVR):单位流量获得成交的概率。模型的结构如图1所示。
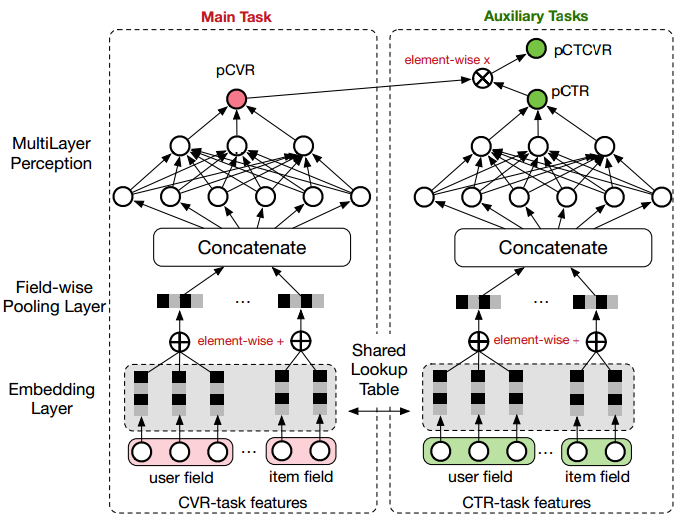
ESMM模型有两个主要的特点:
- 在整个样本空间建模。区别与传统的CVR预估方法通常使用“点击->成交”事情的日志来构建训练样本,ESMM模型使用“展现->点击->成交”事情的日志来构建训练样本。
- 共享特征表示。两个子任务(CTR预估和CVR预估)之间共享各类实体(产品、品牌、类目、商家等)ID的embedding向量表示。
ESMM模型的损失函数由两部分组成,对应于pCTR 和pCTCVR 两个子任务,其形式如下:
\begin{align}
L(\theta_{cvr},\theta_{ctr}) &=\sum_{i=1}^N l(y_i, f(x_i; \theta_{ctr}))\\
&= \sum_{i=1}^N l(y_i\&z_i, f(x_i; \theta_{ctr}) \times f(x_i; \theta_{cvr}))
\end{align}
其中,$\theta_{ctr}$和$\theta_{cvr}$分别是CTR网络和CVR网络的参数,$l(\cdot)$是交叉熵损失函数。在CTR任务中,有点击行为的展现事件构成的样本标记为正样本,没有点击行为发生的展现事件标记为负样本;在CTCVR任务中,同时有点击和购买行为的展现事件标记为正样本,否则标记为负样本。
ESMM模型由两个结构完全相同的子网络连接而成,我们把子网络对应的模型称之为Base模型。接下来,我们先介绍下如何用tensorflow实现Base模型。
Base模型的实现
在Base模型的网络输入包括user field和item field两部分。user field主要由用户的历史行为序列构成,具体地说,包含了用户浏览的产品ID列表,以及用户浏览的品牌ID列表、类目ID列表等;不同的实体ID列表构成不同的field。网络的Embedding层,把这些实体ID都映射为固定长度的低维实数向量;接着之后的Field-wise Pooling层把同一个Field的所有实体embedding向量求和得到对应于当前Field的一个唯一的向量;之后所有Field的向量拼接(concat)在一起构成一个大的隐层向量;接着大的隐层向量之上再接入诺干全连接层,最后再连接到只有一个神经元的输出层。
Feature Column构建序列embedding和pooling
具体到tensorflow里,如何实现embedding layer以及field-wise pooling layer呢?
其实,用tensorflow的Feature Column API可以非常容易地实现。在详细介绍之前,建议读者先阅读一下该系列文章的上一篇:《构建分布式Tensorflow模型系列:特征工程》。
实现embedding layer需要用到tf.feature_column.embedding_column或者tf.feature_column.shared_embedding_columns,这里因为我们希望user field和item field的同一类型的实体共享相同的embedding映射空间,所有选用tf.feature_column.shared_embedding_columns。由于shared_embedding_columns函数只接受categorical_column列表作为参数,因此需要为原始特征数据先创建categorical_columns。
来看下具体的例子,假设在原始特征数据中,behaviorPids表示用户历史浏览过的产品ID列表;productId表示当前的候选产品ID;则构建embedding layer的代码如下:
1 | from tensorflow import feature_column as fc |
需要说明的是,在构建训练样本时要特别注意,behaviorPids列表必须是固定长度的,否则在使用dataset的batch方法时会报tensor shape不一致的错。然而,现实中每个用户浏览过的产品个数肯定会不一样,这时可以截取用户的最近N个浏览行为,当某些用户的浏览商品数不足N个时填充默认值-1(如果ID是用字符串表示的时候,填充空字符串)。那么为什么填充的默认值必须是-1呢?这时因为categorical_column*函数用默认值-1表示样本数据中未登录的值,-1表示的categorical_column经过embedding_column之后被映射到零向量,而零向量在后面的求和pooling操作中不影响结果。
那么,如何实现field-wise pooling layer呢?其实,在用tf.feature_column.embedding_column或者tf.feature_column.shared_embedding_columnsAPI时不需要另外实现pooling layer,因为这2个函数同时实现了embedding向量映射和field-wise pooling。大家可能已经主要到了shared_embedding_columns函数的combiner=’sum’参数,这个参数就指明了当该field有多个embedding向量时融合为唯一一个向量的操作,’sum’操作即element-wise add。
上面的代码示例,仅针对产品这一实体特征进行了embedding和pooling操作,当有多个不同的实体特征时,仅需要采用相同的方法即可。
实现weighted sum pooling操作
上面的操作实现了行为序列特征的embedding和pooling,但有一个问题就是序列中的每个行为被同等对待了;某些情况下,我们可能希望行为序列中不同的实体ID在做sum pooling时有不同的权重。比如说,我们可能希望行为时间越近的产品的权重越高,或者与候选产品有相同属性(类目、品牌、商家等)的产品有更高的权重。
那么如何实现weighted sum pooling操作呢?答案就是使用weighted_categorical_column函数。我们必须在构建样本时添加一个额外的权重特征,权重特征表示行为序列中每个产品的权重,因此权重特征是一个与行为序列平行的列表(向量),两者的维度必须相同。另外,如果行为序列中有填充的默认值-1,那么权重特征中这些默认值对应的权重必须为0。代码示例如下:
1 | from tensorflow import feature_column as fc |
模型函数
Base模型的其他组件就不过多介绍了,模型函数的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def my_model(features, labels, mode, params):
net = fc.input_layer(features, params['feature_columns'])
# Build the hidden layers, sized according to the 'hidden_units' param.
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
if 'dropout_rate' in params and params['dropout_rate'] > 0.0:
net = tf.layers.dropout(net, params['dropout_rate'], training=(mode == tf.estimator.ModeKeys.TRAIN))
my_head = tf.contrib.estimator.binary_classification_head(thresholds=[0.5])
# Compute logits (1 per class).
logits = tf.layers.dense(net, my_head.logits_dimension, activation=None, name="my_model_output_logits")
optimizer = tf.train.AdagradOptimizer(learning_rate=params['learning_rate'])
def _train_op_fn(loss):
return optimizer.minimize(loss, global_step=tf.train.get_global_step())
return my_head.create_estimator_spec(
features=features,
mode=mode,
labels=labels,
logits=logits,
train_op_fn=_train_op_fn
)
ESMM模型的实现
有了Base模型之后,ESMM模型的实现就已经成功了一大半。剩下的工作就是把两个子模型连接在一块,同时定义好整个模型的损失函数和优化操作即可。
在前面的文章中,我们分享过为tensorflow estimator定义模型函数时,需要为不同mode(训练、评估、预测)下定义构建计算graph的所有操作,并返回想要的tf.estimator.EstimatorSpec。在前面的介绍中,我们使用了Head API来简化了创建EstimatorSpec的过程,但在实现ESMM模型时没有现成的Head可用,必须手动创建EstimatorSpec。
在不同的mode下,模型函数必须返回包含不同图操作(op)的EstimatorSpec,具体地:
- For mode == ModeKeys.TRAIN: required fields are
lossandtrain_op. - For mode == ModeKeys.EVAL: required field is
loss. - For mode == ModeKeys.PREDICT: required fields are
predictions.
另外,如果模型需要导出以便提供线上服务,这时必须在mode == ModeKeys.EVAL定义export_outputs操作,并添加到返回的EstimatorSpec中。
实现ESMM模型的关键点在于定义该模型独特的损失函数。上文也提到,ESMM模型的损失函数有2部分构成,一部分对应于CTR任务,另一部分对应于CTCVR任务。具体如何定义,请参考下面的代码:
1 | def build_mode(features, mode, params): |
至此,实现ESMM模型需要介绍的内容就结束了,完整的代码已经在github上共享了,欢迎大家下载试用。
关注微信公众号“算法工程师的进阶之路”,后台回复“ESMM“,获取完整源代码。

