一、推荐算法为何要精做特征工程
机器学习工作流就好比是一个厨师做菜的过程,简单来说,清洗食材对应了清洗数据,食材的去皮、切片和搭配就对于了特征工程的过程,食物的烹饪对应了模型训练的过程。如果你觉得数据清洗和特征工程不重要,莫非是你想吃一份没有经过清洗、去皮、切片、调料,而直接把原始的带着泥沙的蔬菜瓜果放在大锅里乱炖出来的“菜”? 先不说卫生的问题,能不能弄熟了都是个问题。
在完整的机器学习流水线中,特征工程通常占据了数据科学家很大一部分的精力,是因为特征工程能够显著提升模型性能,高质量的特征能够大大简化模型复杂度,让模型变得高效且易理解、易维护。在机器学习领域,“Garbage In, Garbage Out”是业界的共识,对于一个机器学习问题,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
与计算机视觉、语音、NLP等领域不同,推荐算法模型很大程度上依赖人工特征工程为其提供输入数据,这是因为推荐算法需要处理的通常是结构化的关系型数据,这些原始数据一般需要经过清洗、采样、变换、统计、编码等方式生成最终的特征数据,模型本身无法直接完成所有这些加工逻辑。关于工业级推荐系统中如何做特征工程,请参考这篇文章《工业级推荐系统中的特征工程》。
上面这篇文章从一个较概括和抽象的角度详细介绍了工业级推荐系统中如何做特征工程,但并未提及代码实现方面的内容。本文的目标就是帮助读者理解并掌握这些特征工程方法在真实的生成环境中是如何实现的。本文从一个公开数据集出发,详细讲解一个工业级推荐系统的特征工程代码是如何一步一步开发出来的。开发语言为MaxCompute SQL,非常类似于Hive/Spark SQL。
查看本文完整代码:Github
二、数据集简介
本文使用的训练、评估、测试数据集来自REES46 Marketing Platform的多类目电商平台的行为数据。该数据集包含了电商平台从2019年10月到2020年4月的28.5亿条用户行为记录。
数据集中的每一行表示一个用户对一个商品行为事件。数据集的Schema如下:
| Property | Description |
|---|---|
| event_time | Time when event happened at (in UTC). |
| event_type | one kind of event: view, cart, purchase. |
| product_id | ID of a product |
| category_id | Product’s category ID |
| category_code | Product’s category taxonomy (code name) if it was possible to make it. Usually present for meaningful categories and skipped for different kinds of accessories. |
| brand | Downcased string of brand name. Can be missed. |
| price | Float price of a product. Present. |
| user_id | Permanent user ID. |
| user_session | Temporary user’s session ID. Same for each user’s session. Is changed every time user come back to online store from a long pause. |
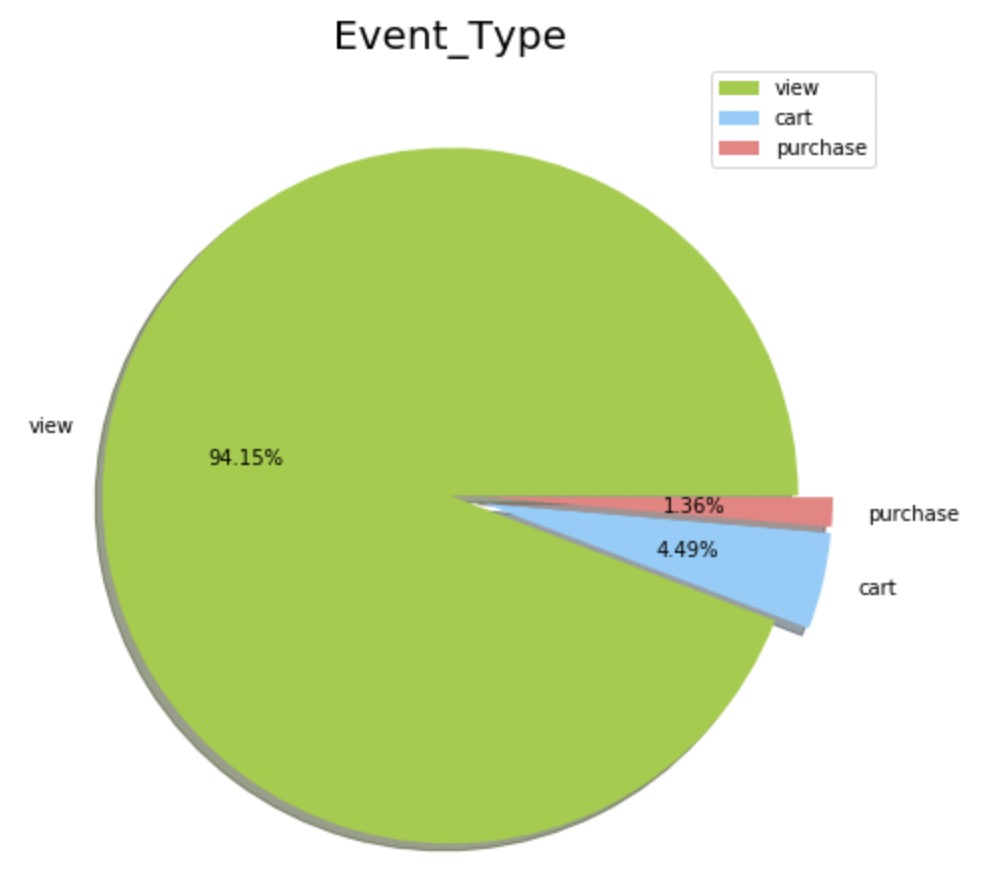
Event types
事件类型包括:
- view - 用户浏览了某个商品
- cart - 用户把某个商品加入了购物车
- purchase - 用户购买了某个商品
User Session
用户会话:
- 一次会话中可能包含了多个用户行为,甚至多个购买行为。
数据探查
示例数据:
| event_time | event_type | product_id | category_id | category_code | brand | price | user_id | user_session |
|---|---|---|---|---|---|---|---|---|
| 2019-11-01 00:00:00 UTC | view | 1003461 | 2053013555631882655 | electronics.smartphone | xiaomi | 489.07 | 520088904 | 4d3b30da-a5e4-49df-b1a8-ba5943f1dd33 |
| 2019-11-01 00:00:00 UTC | view | 5000088 | 2053013566100866035 | appliances.sewing_machine | janome | 293.65 | 530496790 | 8e5f4f83-366c-4f70-860e-ca7417414283 |
| 2019-11-01 00:00:01 UTC | view | 1004775 | 2053013555631882655 | electronics.smartphone | xiaomi | 183.27 | 558856683 | 313628f1-68b8-460d-84f6-cec7a8796ef2 |
| 2019-11-01 00:01:04 UTC | purchase | 1005161 | 2053013555631882655 | electronics.smartphone | xiaomi | 211.92 | 513351129 | e6b7ce9b-1938-4e20-976c-8b4163aea11d |
| 2019-11-01 00:06:33 UTC | purchase | 1801881 | 2053013554415534427 | electronics.video.tv | samsung | 488.80 | 557746614 | 4d76d6d3-fff5-4880-8327-e9e57b618e0e |
| 2019-11-01 00:07:38 UTC | purchase | 30000218 | 2127425436764865054 | construction.tools.welding | magnetta | 254.78 | 515240495 | 0253151d-5c84-4809-ba02-38ac405494e1 |
以2019年十一月的数据为例,展示一些统计数据。
- 记录数:67501979
- category_code
- [null]: 32%
- lectronics.smartphone: 24%
- other: 43%
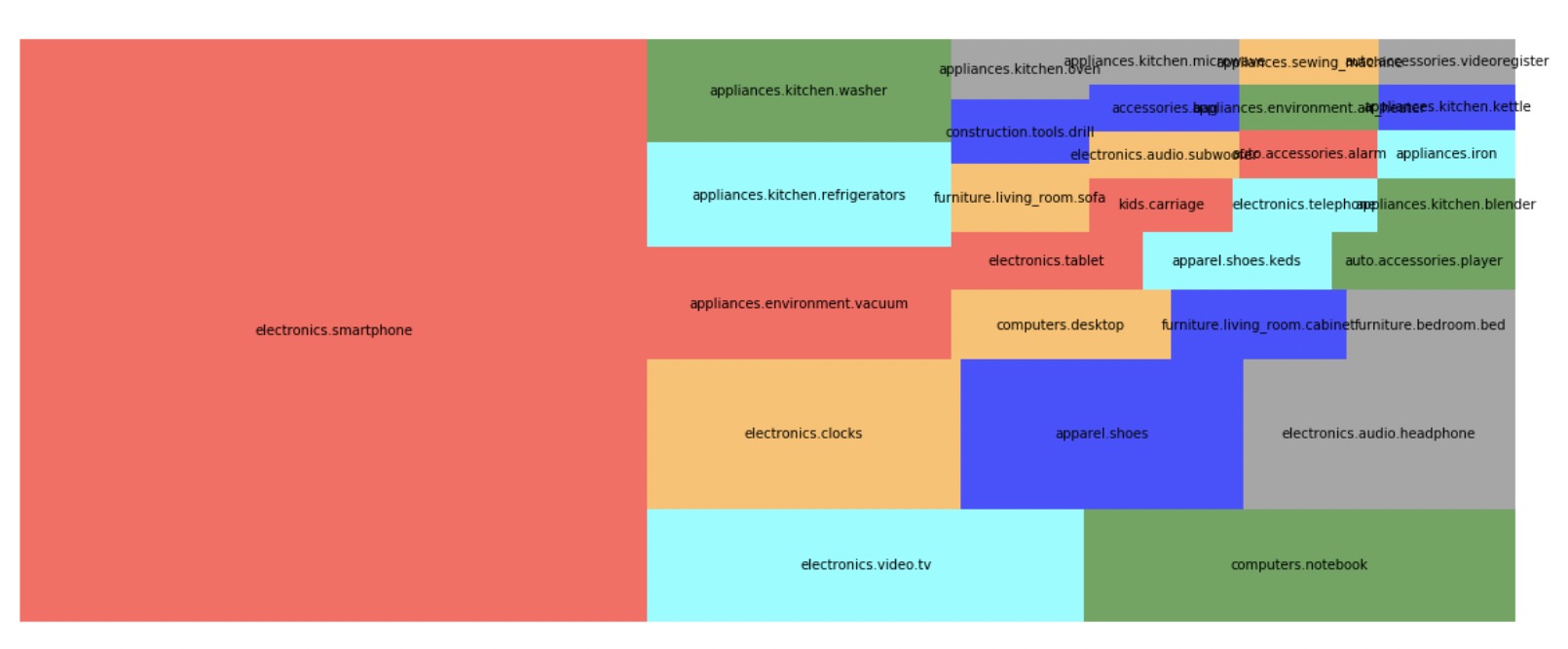
- brand
- [null]: 14%
- samsung: 12%
- other: 75%
- Top Brands
| brand | count |
|---|---|
| samsung | 198670 |
| apple | 165681 |
| xiaomi | 57909 |
| huawei | 23466 |
| oppo | 15080 |
| lg | 11828 |
- user_session
- 唯一值个数:13776051
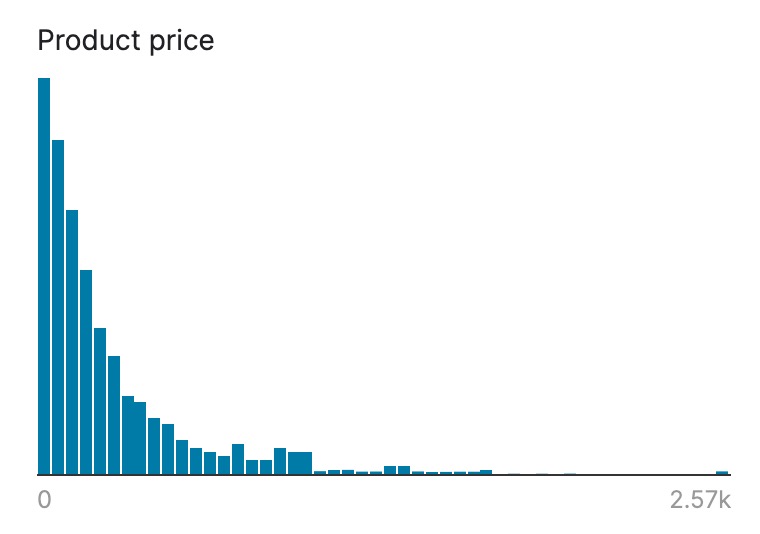
- price
- mean: 292
- std. Deviation: 356
- min: 0
- max: 2.57k
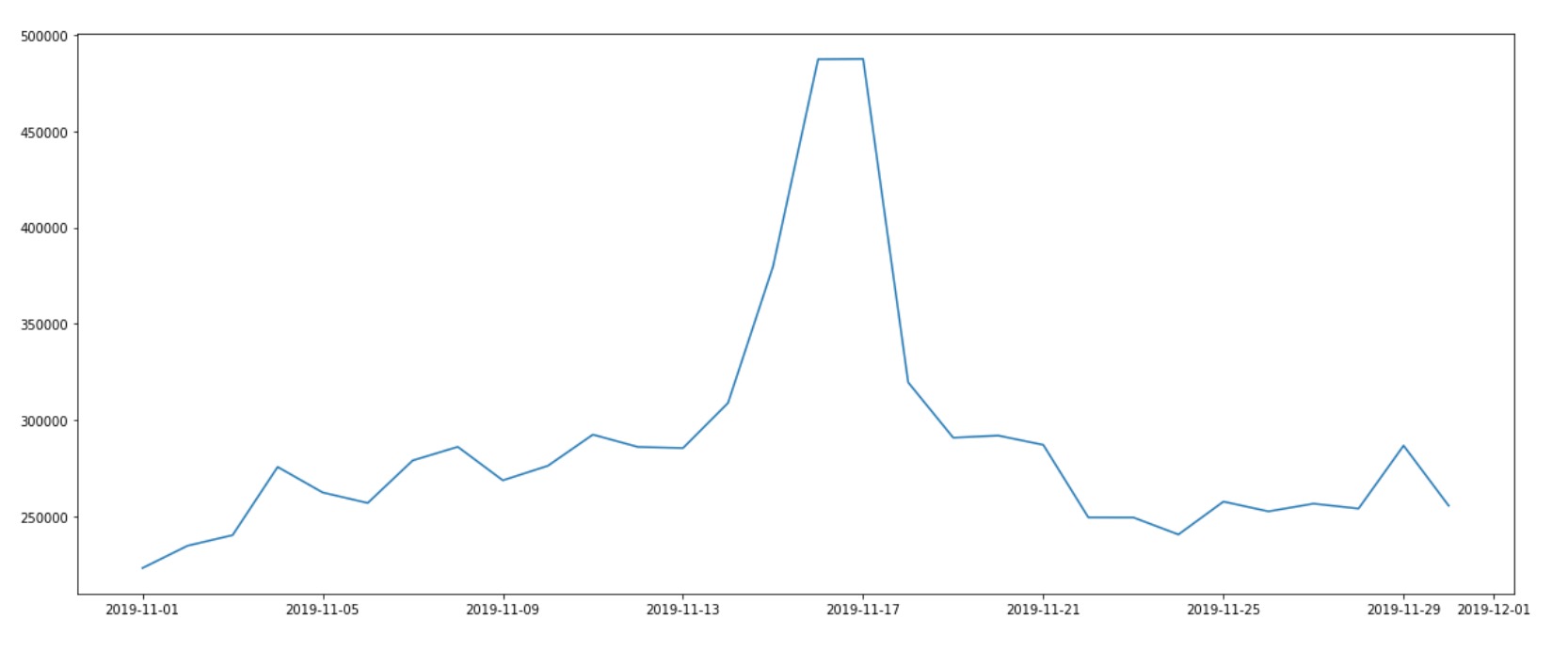
- event_time (Vistors Daily Trend)
- Does traffic flunctuate by date?
三、任务目标
建立模型预测用户在加购某商品后,最终是否会购买。
根据上述学习目标,通过下列准则构建样本标签:
- 正样本:用户购买了某商品
- 负样本:用户把某商品加入购物车,但之后并没有购买(在同一session内)
- 浏览行为不用来构建样本(但可以用来做特征)
数据集的划分方法如下:
- 训练集:19年11月-20年2月
- 验证集:20年3月
- 测试集:20年4月
其中,19年10月的数据不用来做训练,是因为特征构建时最长的统计周期是30天,10月份的数据在一些统计值上会发生统计不完全的问题。
四、特征工程
限于篇幅的原因,我们在文章中只展示部分代码,完整的代码请查看Github。
首先,我们创建一个和原始数据对应schema的MaxCompute Table ecommerce_behavior,并把从Kaggle下载的数据集通过 odpscmd 的 tunnel 命令上传至 MaxCompute平台。举例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18CREATE TABLE IF NOT EXISTS ecommerce_behavior
(
event_time STRING,
event_type STRING,
product_id BIGINT,
category_id BIGINT,
category_code STRING,
brand STRING,
price DOUBLE,
user_id BIGINT,
user_session STRING
)
PARTITIONED BY
(
dt STRING
);
odpscmd -e "tunnel u -cf true -h true -acp true 2020-Apr.csv ecommerce_behavior/dt=202004;"
在预处理阶段,category_code(类目路径)被分裂为cat_0,cat_1,cat_2三个字段,分别表示一级类目、二级类目、三级类目;根据event_time生成两个新的特征:ts_weekday(value: 0-7),ts_hour(value: 0-23),分别表示星期几和几点钟。代码如下:
1 | INSERT OVERWRITE TABLE ecommerce_behavior_table PARTITION(dt) |
1. 缺失值填充
通过数据分析发现,类目和品牌字段存在一些缺失值,由于类目和品牌都属于类别型特征,在其他处理之前我们用一个固定值“UNKNOWN”填充缺失值。
2. 生成价格档位 & 价格环比Diff Ratio
电商场景下,购买需求很大程度上受到价格因素的影响,因此价格是一个很重要的特征。然而,由于商品价格的跨度非常大,从前面数据探查的结果可以看出,该数据集上价格基本上遵循幂律分布。我们需要一个特征来度量该商品是“贵”还是“便宜”,以及“贵”或“便宜”的程度是多少,然而不同类目的商品价格区间是不一样的,如果不考虑商品的品类,那么价格的绝对值是无法度量商品是“贵”还是“便宜”的。通常我们会认为200块钱买一部手机是便宜的,但是100块钱买一瓶饮料却非常贵。
我们可以对商品价格做z-score标准化来生成输入给模型的特征。
其中,$mean_c(price)$表示类目$c$的商品的平均价格,$std_c(price)$表示类目$c$的商品价格的标准差。
1 | CREATE TABLE IF NOT EXISTS category_price_info |
转换后的$norm_price$服从标准的正态分布,对于大多数模型,尤其是深度神经网络这样的模型,是非常友好的;这点可以从深度学习常用的batch normalization技术上得到验证。
好了,现在我们有一个可以度量商品“贵”或“便宜”的程度特征了。然而,现实中有很多用户对不同品类的商品的价格敏感度是不一样的,比如某用户可能喜欢买贵的电子产品,同时也偏好便宜的日用品。如果我们还需要度量某用户对不同品类的价格的偏好程度,那么仅仅有$norm_price$还是不够的,因为$norm_price$是一个连续值,没法直接和其他特征做交叉统计。进一步,我们可以对价格做档位划分,比如可以在每个类目下把商品按照价格从低到高排序,然后通过分位点划分为10个宽度相等的区间,把区间的编号作为商品的价格档位。SQL代码如下:
1 | CREATE VIEW IF NOT EXISTS price_level_lookup_table AS |
上述步骤得到的price_level是一个值域为[0, 10)的离散值,可以和类目、用户组合成新特征,以及在新的组合特征的基础上生成新的统计特征。
在经济学中,价格是影响供给和需求的重要因素。价格的变化会显著影响需求量,因此把价格的变化建模到特征中会是一个不错的选择。我们构建了当前商品价格与前一天的最小价格之间的差异变化率作为特征。
3. Categorifying
对于类别型特征,如商品的类目、品牌等,推荐首先做Categorifying,即把类别型特征转换为该特征值的列表的索引位置(index),得到一个从0到$|C|$的非负整数,这里$|C|$表示该特征唯一值的个数。
Categorifying操作的好处是可以节省在线feature store的存储空间,因为原来的字符串值都被转换成了数字。同时,Categorifying的结果可以更方便地输入给深度神经网络模型的Embedding Layers,反之,如果不做Categorifying那么就需要的对原始类别型特征做hash之后,再去查Embedding Lookup Table,为了防止hash冲突,通常Embedding Lookup Table的长度都设置得比实际需要的更大,这样就会让模型多了很多不必要的参数,给模型的存储和分发都带来了额外的负担。
Categorifying的代码如下:
1 | CREATE VIEW IF NOT EXISTS category_lookup_table AS |
4. 分箱 & 组合
之前提到的价格档位就是一种分箱操作,除此之外,我们还可以自定义分箱的边界。比如,对于时间ts_hour字段我们可以根据统计数据分析自定义如下分箱边界,生成新的特征hour_bin。
- 0-3 Night: 较低的购买概率
- 4-7 Early morning: 中等的购买概率
- 8-14 Morning/Lunch: 较高的购买概率
- 15-20 Afternoon: 较低的购买概率
- 21-23: Evening: 高购买概率
组合特征是一个常用的特征转换操作。有时候单个独立的类别型特征对于目标的预测帮助不大,但把两个或多个特征组合起来时就能够很好地帮助模型预测目标。比如,我们可以把weekday和hour_bin组合起来。
1 | -- 完整代码请查看 `ecommerce_behavior_view` 试图的生成代码 |
5. 样本去重和标签生成
我们把同一用户在同一session中对同一商品的多个相同类型的行为事件判定为重复样本,再接下来的生成统计特征之前,我们先执行样本去重,SQL的主要逻辑如下。
1 | -- 完整代码请查看 `ecommerce_behavior_view` 试图的生成代码 |
下一小节要介绍的上下文特征需要依赖样本去重逻辑的执行才能正确计算出来。
根据学习任务的目标,定义用户在同一session中购买了某商品后,该session中当前用户对目标商品的所有行为事件都关联正样本的标签,否则关联负样本的标签。代码如下:
1 | CREATE VIEW IF NOT EXISTS ecommerce_session_purchase(@bizdate STRING) |
后续介绍的统计特征都需要依赖标签来做Target Encoding相关的操作。
6. 上下文特征
由于数据集提供的字段比较少,因此我们能够利用的上下文特征比较有限。我们构建的一个比较重要的上下文特征为 activity_count, 即当前session中到目前为止的行为次数。我们使用窗口函数SUM的累积求和功能来计算activity_count的值,代码如下。
1 | INSERT OVERWRITE TABLE ecommerce_behavior_wide_table PARTITION(dt) |
7. 特征值统计
在搜索、推荐、广告场景下,基于类别型特征生成新的统计特征是常规做法。个人认为,成功的特征工程要达成的目标就是降低使用复杂的模型的必要性。好的特征本身应该具有很好的信息量和区分度,不再需要模型本身的有很强的建模能力。那么,如何才能构建既有信息量又有区分度的特征呢?
在推荐场景下,对类别型特征或者执行分箱操作之后的数值型特征进行统计编码是常见套路,这一过程称之为bin-counting,详情请查看《工业级推荐系统中的特征工程》。
首先,我们需要一些基础的计数统计值,以CTR预估为例,目标是预测用户是否回点击某Item,那么我们需要如下统计计数值:
| User | Number of clicks | Number of non-clicks |
|---|---|---|
| Alice | 27 | 534 |
| Bob | 96 | 235 |
| … | … | … |
| Joe | 9 | 374 |
我们还需要对特征之间的交叉组合做正负样本的统计,如用户对不同商品类目的行为计数:
| User,Category | Number of clicks | Number of non-clicks |
|---|---|---|
| Alice,1001 | 7 | 134 |
| Bob,1002 | 17 | 235 |
| … | … | … |
| Joe,1101 | 2 | 274 |
在实际的应该过程中,我们需要统计不同时间周期、不同行为类型以及不同组合特征下正、负样本的计数值,并基于这些统计值做特征编码。
首先,按业务日期统计商品、以及商品属性(看成是一种binning的结果)不同行为类型下的正、负样本数量:
1 | CREATE TABLE IF NOT EXISTS ecommerce_item_count_daily |
然后,按照最近1天、3天、7天、30天的时间滑动窗口,统计不同field的不同bin在不同行为类型下的正负样本数量,以及当前field在不同类型的行为下全局正负样本数量。
1 | INSERT OVERWRITE TABLE ecommerce_item_cumulate_count PARTITION(field, dt) |
8. 统计特征变换
对应统计得到的数值型特征,通常有两种特征变换方法:缩放(scaling)和分箱(binning)。
推荐系统的统计特征推荐使用 gauss rank 的特征缩放方法或者基于分位点的分箱方法(等频分箱)。
![]()
gauss rank 特征缩放的过程如上图所示,首先对特征值进行排序,然后缩放到 (-1,1) 的区间,最后调用一个逆误差函数 erfinv 得到高斯分布的特征值。
9. 统计特征编码
下面介绍几种常用的特征编码方法。
a) Count Encoding
统计该类别型特征不同行为类型、不同时间周期内的发生的频次。直接用统计值作为特征,需要先做特征缩放(e.g. gauss rank)或分箱。
b) Target Encoding
统计该类别型特征不同行为类型、不同时间周期内的目标转化率(如目标是点击则为点击率,如目标是成交则为购买率)。
目标转化率需要考虑置信度的问题,当置信度不够的时候,需要做平滑,拿全局或者分组的平均转化率当当前特征的转化率做一个平滑,公式如下。
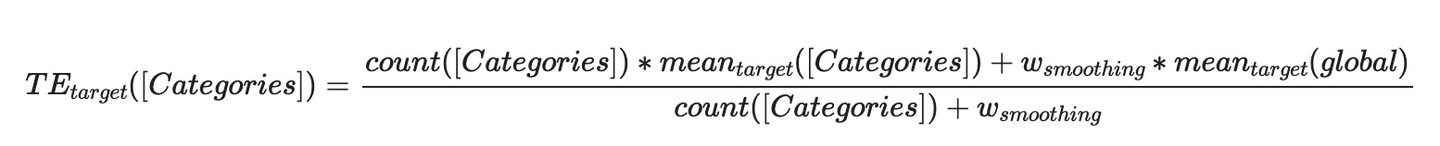
c) 优势比(Odds Ratio)
优势比告诉我们某种推测的概率比其反向推测的概率大多少,公式如下。
例:用户Alice的点击事件
| Click | Non-Click | Total | |
|---|---|---|---|
| Alice | 5 | 120 | 125 |
| Not Alice | 995 | 18880 | 19875 |
| Total | 1000 | 19000 | 20000 |
在我们的例子中,优势比意味着“爱丽丝点击相对于不点击的可能性”和“其他人点击相对于不点击的可能性“相比有多大。在这种情况下,计算出的数字是:
优势比的值有可能会非常小或非常大(例如,可能会有几乎不会点击的用户),因此我们可以对其进行简化,并加一个log转换使得除法变成减法:$log(N^+)-log(N^-)$。
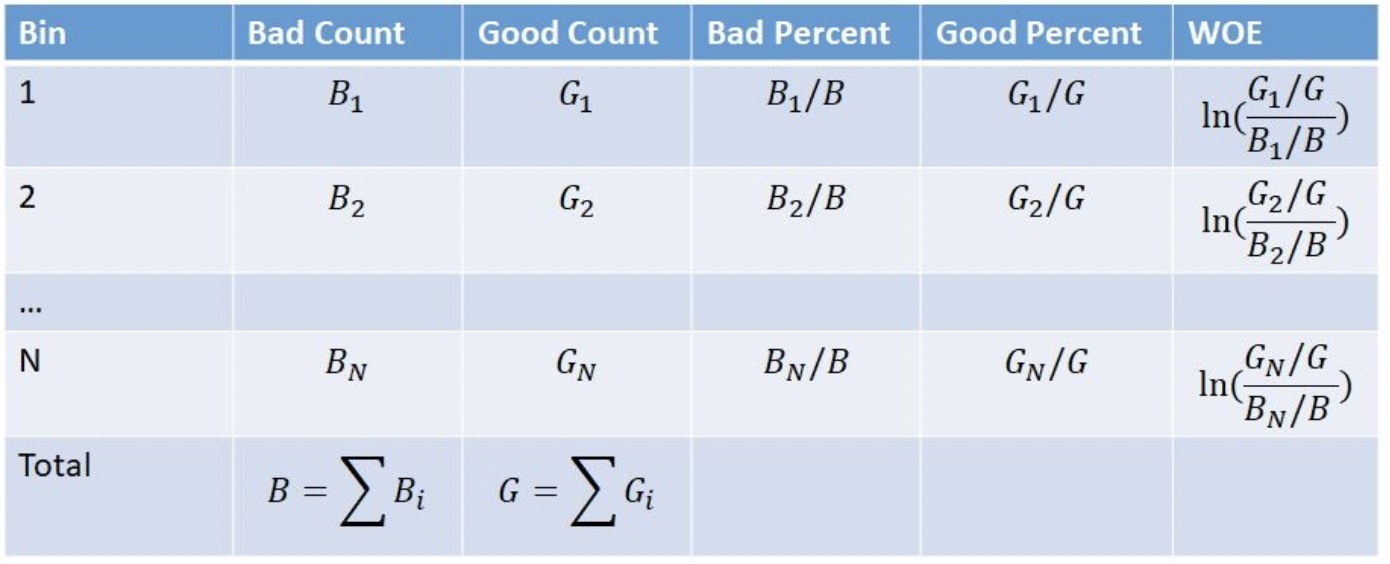
d) 证据权重(Weight Of Evidence)
Weight of evidence (WOE) 和 Information value (IV) 是简单有效的变量变换和选择方法,在二分类问题中也是很好的特征。
1 | INSERT OVERWRITE TABLE ecommerce_user_bin_count_v2 PARTITION(field, dt) |
10. 整体流程
详情请查看《工业级推荐系统中的特征工程》。
模型训练的代码请查看GitHub。
五、实验结果
| 模型 | AUC | GAUC | Recall | Precision | F1 Score | remark |
|---|---|---|---|---|---|---|
| MLP-gauss | 0.633 | 0.476 | 0.393 | 0.579 | 0.46825 | odds+woe/item |
| MLP-ntile | 0.642 | 0.474 | 0.400 | 0.584 | 0.474727 | - |
| GBDT v2 | 0.558 | 0.562 | 0.681 | 0.444 | 0.537114 | - |
| GBDT on od | 0.549 | 0.539 | 0.867 | 0.439 | 0.58277 | - |
| GBDT on ow | 0.585 | 0.594 | 0.815 | 0.447 | 0.57738 | - |
| LR | 0.649 | 0.583 | 0.370 | 0.592 | 0.455 | - |
六、特征重要度分析
根据GBDT算法中特征带来的信息增益计算出特征重要度如下(截取了Top N个):
| name | importance |
|---|---|
| user_cat_0_cart_odds_ratio_30d | 0.06663279235363007 |
| weekday_hour | 0.05106705102843989 |
| user_cat_2_purchase_gauss_rank_7d | 0.04943003132939339 |
| cat_2_cart_odds_ratio_1d | 0.042615607380867004 |
| user_cat_0_view_gini_30d | 0.0248174536973238 |
| brand_cart_gini_7d | 0.023471875116229057 |
| cat_1_view_gini_7d | 0.021432124078273773 |
| category_cart_odds_ratio_1d | 0.017213333398103714 |
| cate_hour_cart_woe_30d | 0.016498396173119545 |
| code_view_gini_1d | 0.015937425196170807 |
| cat_0_cart_info_value_30d | 0.01512192189693451 |
| price_level_view_chi_square_1d | 0.014924108050763607 |
| cate_price_level_cart_woe_3d | 0.013924989849328995 |
| cat_2_view_gini_7d | 0.01232975721359253 |
| user_cat_2_cart_odds_ratio_30d | 0.012204065918922424 |

