推荐系统学习用户与物品的交互模式,并据此给用户推荐物品。 然而,用户与物品的交互行为数据是很稀疏的,也就是说,观察到的”用户-物品”交互往往只占可能的互动的5%以下(User-Item矩阵的稀疏度)。缓解数据稀疏的一个有希望的方向是利用辅助信息,这些信息可能编码了关于用户如何与物品交互的额外线索。这类数据(被称为模态)的例子有:社交网络、物品的描述性文本、物品的图像、视频等。那么如何利用这些额外的数据为推荐系统提供更好的性能呢?多模态推荐模型提供了一个有希望的方向。
推荐系统通常还会面临冷启动问题的挑战,比如新发布的物品该如何推荐给用户。物品的内容信息,尤其是图片、视频这些视觉信息为缓解物品冷启动问题提供了一个可行的思路。关于推荐冷启动问题的更多解决方案请查看《冷启动推荐模型DropoutNet深度解析与改进》。那么该如何利用物品的视觉信息来构建推荐算法模型呢?
文本总结了一些常用的视觉多模态推荐模型的大致思路,在此之前,让我们先来了解一些基础的推荐算法。
一、基础推荐算法
通常,推荐系统会收集用户的显式反馈和隐式反馈数据,作为输入给推荐算法的“原料”。推荐算法会基于这些数据构建模型学习用户与物品的交互模式,从而在未观察的数据上做出预测来完成后续物品的推荐。显式反馈包括评分、点赞、不喜欢等;隐式反馈是用户在系统上的其他行为,如点击、浏览时长、收藏、分享等。

推荐问题通常被建模为两大类问题:
- Rating Prediction:算法预测给定的用户对给定的物品的偏好分,系统给用户推荐预测偏好分高的物品集;
- Ranking:给定用户的情况下,算法预测用户对不同物品偏好程度的偏序关系,根据偏序关系排列后续物品,推荐列表的Top K 物品集。

推荐算法通常可以分为三大类:
- 协同过滤
- 基于内容的推荐
- 基于模型的推荐(混合推荐)
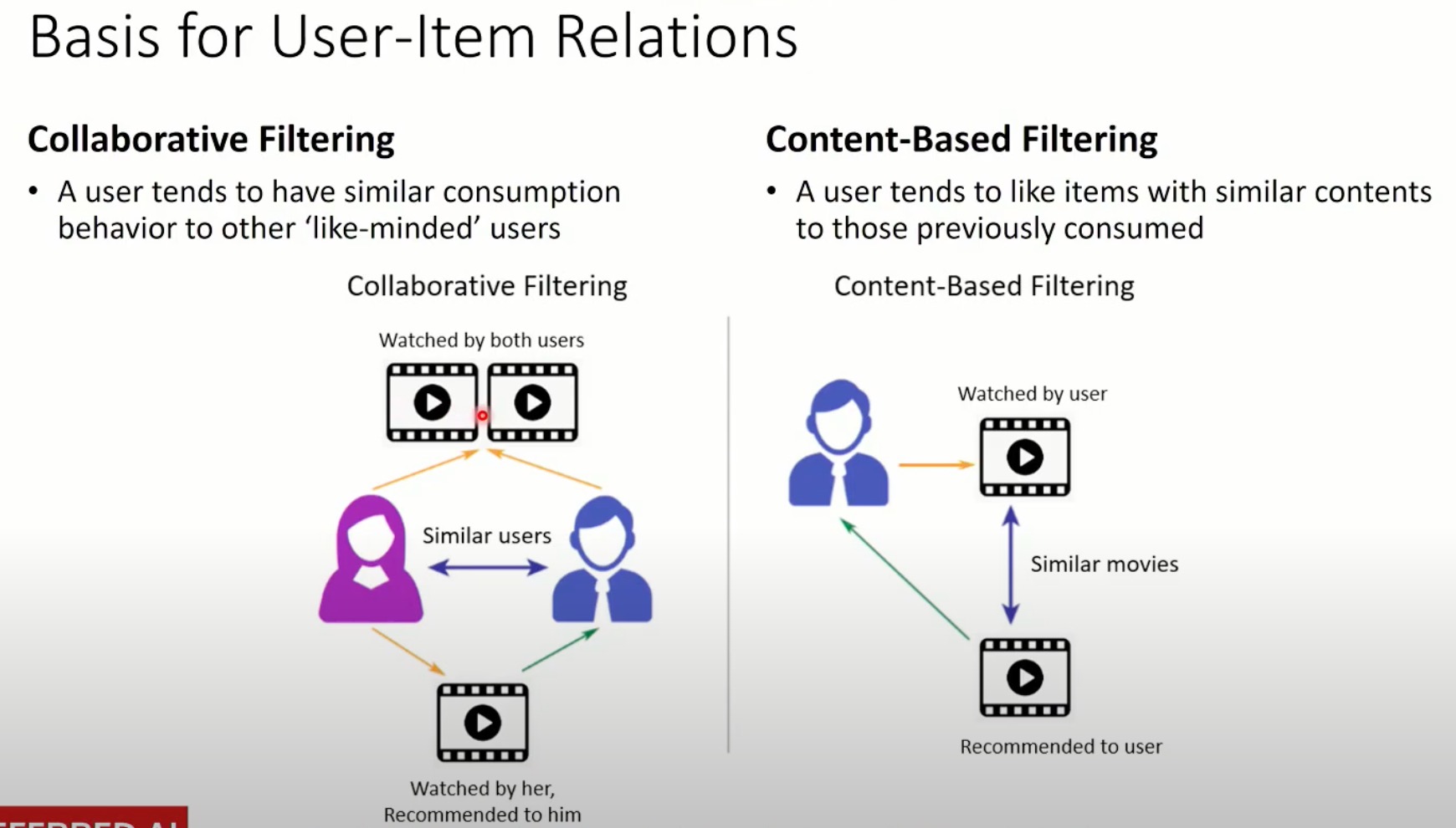
矩阵分解是一种常用的协同过滤推荐算法。偏好数据被表示为一个用户-项目矩阵,然后被分解为一组K维的用户和项目潜在因素(latent factors)。对用户u和项目i的预测是根据u和i的潜在因素的内积来估计的。这种表达方法(formulation)由于不同的损失函数而产生了一些变体。基于显性反馈的模型通常寻求最小化观察和预测评级之间的误差,如PMF。隐性反馈模型可以将观察结果解释为置信信号(confidence signal)(如WMF)或相对比较(relative comparisons)(如BPR)。
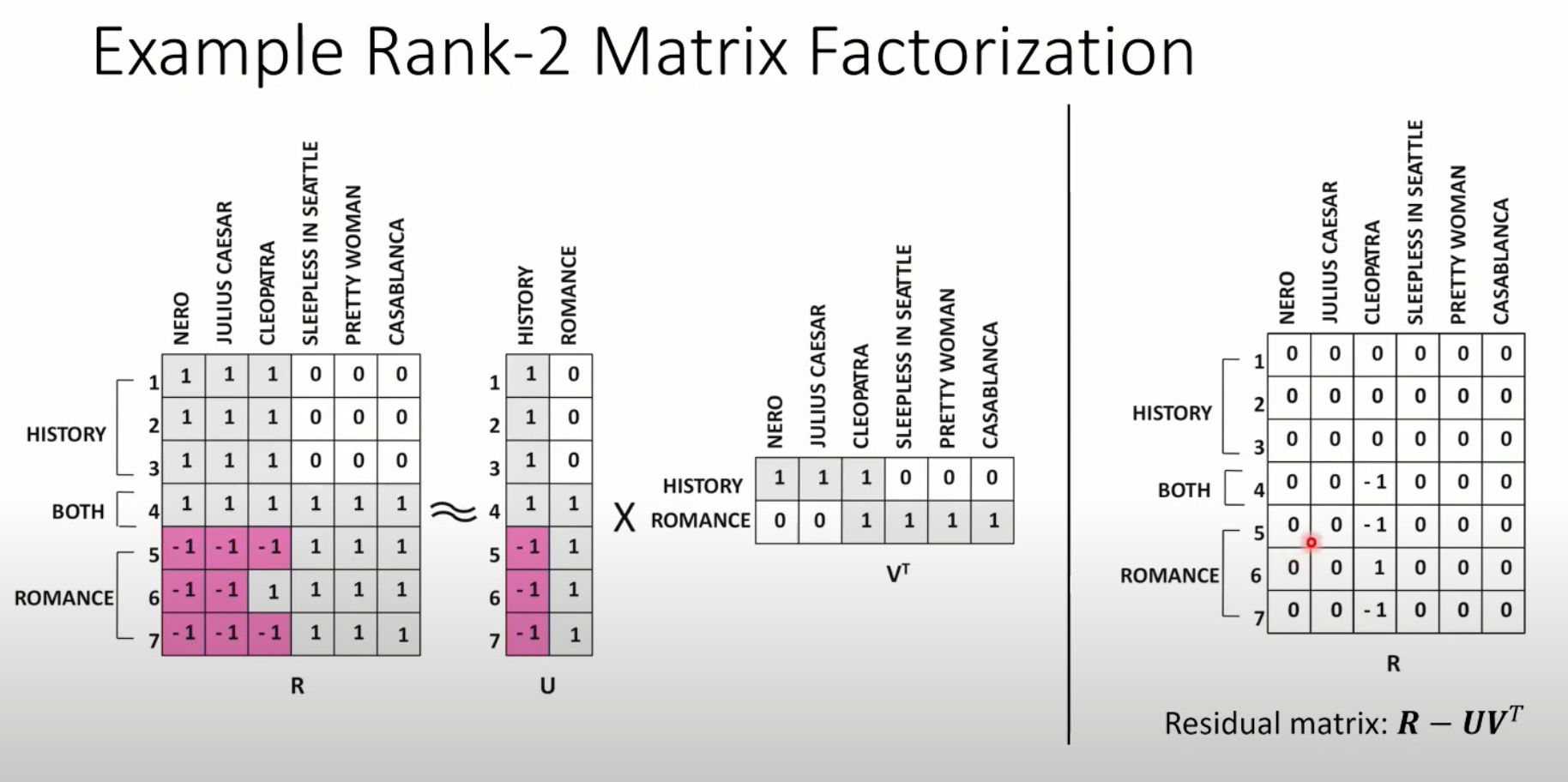
在矩阵分解方法中预估潜在因子通过在观察到的评分数据(或隐式反馈数据)上最小化loss function来完成,如下图所示。
由于数据稀疏性的问题,以及防止过拟合的需要,我们通常还会在损失函数上添加正则项。
通常我们还需要考虑用户和物品的偏置,这是因为:
- 用户有不同的评分标准(或活跃程度),有些人倾向于给高评分,有些人则对评分比较保守;另外,活跃用户的隐式反馈行为较多,不太活跃的用户(或者目的明确的用户)隐式反馈行为较少。
- 物品的受欢迎程度也不同,有一些物品主要为高评分,另一些主要为低评分;“哈利波特”效应很好地说明了这一问题。

由于隐式反馈数据有一定的不置信问题,比如未观察到的数据不能认为就一定是负样本,观察到的数据也可能是噪音数据。因此,带有权重的矩阵分解方法被提出,如下:
建模为Ranking问题并学习偏序关系的一个典型算法是贝叶斯个性化排序(BPR),如下:
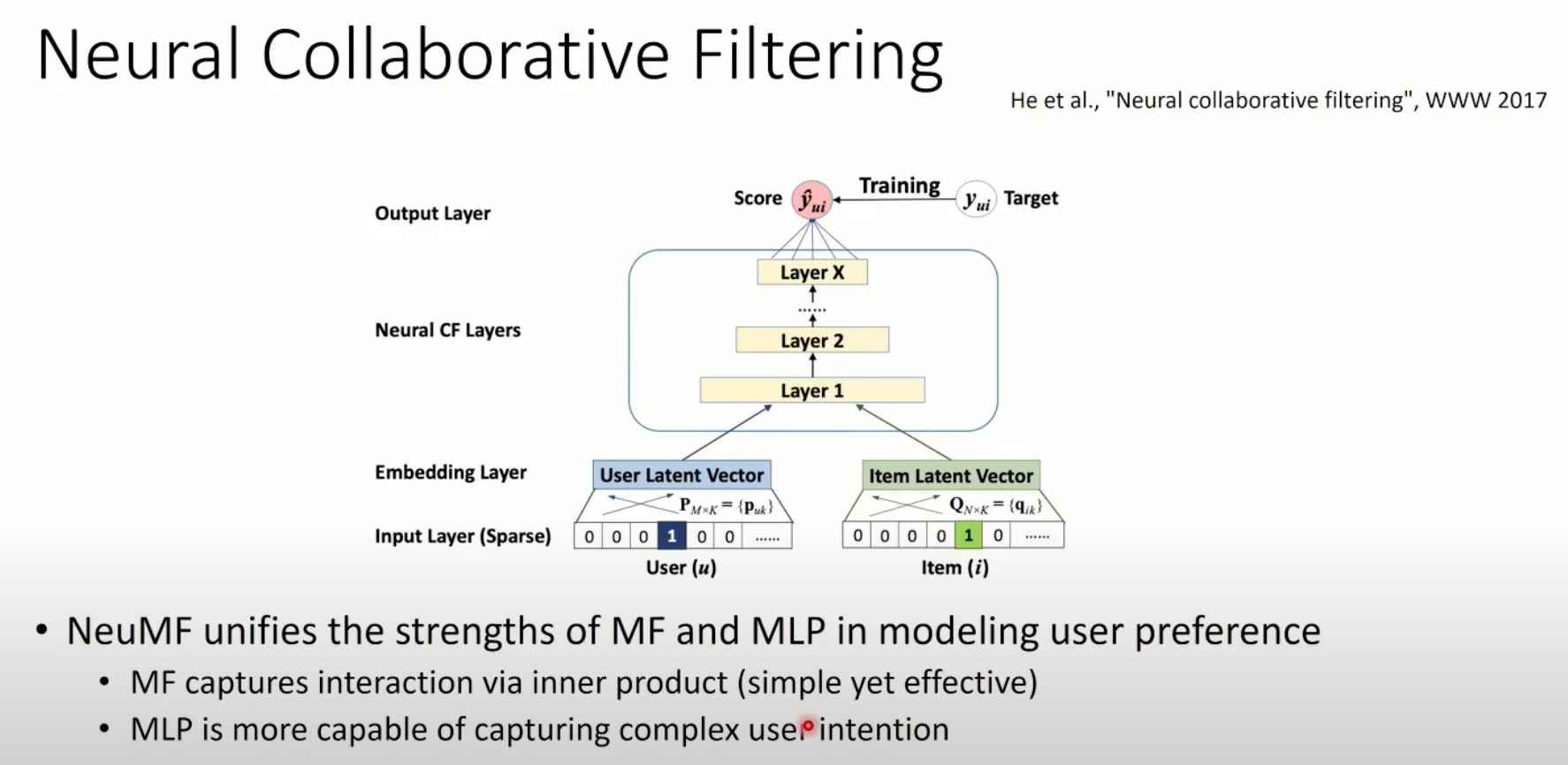
神经协同过滤 NeuMF统一了MF和MLP在模拟用户偏好方面的优势
- MF通过内积(简单而有效)捕获了交互;
- MLP更有能力捕捉到复杂的用户意图。
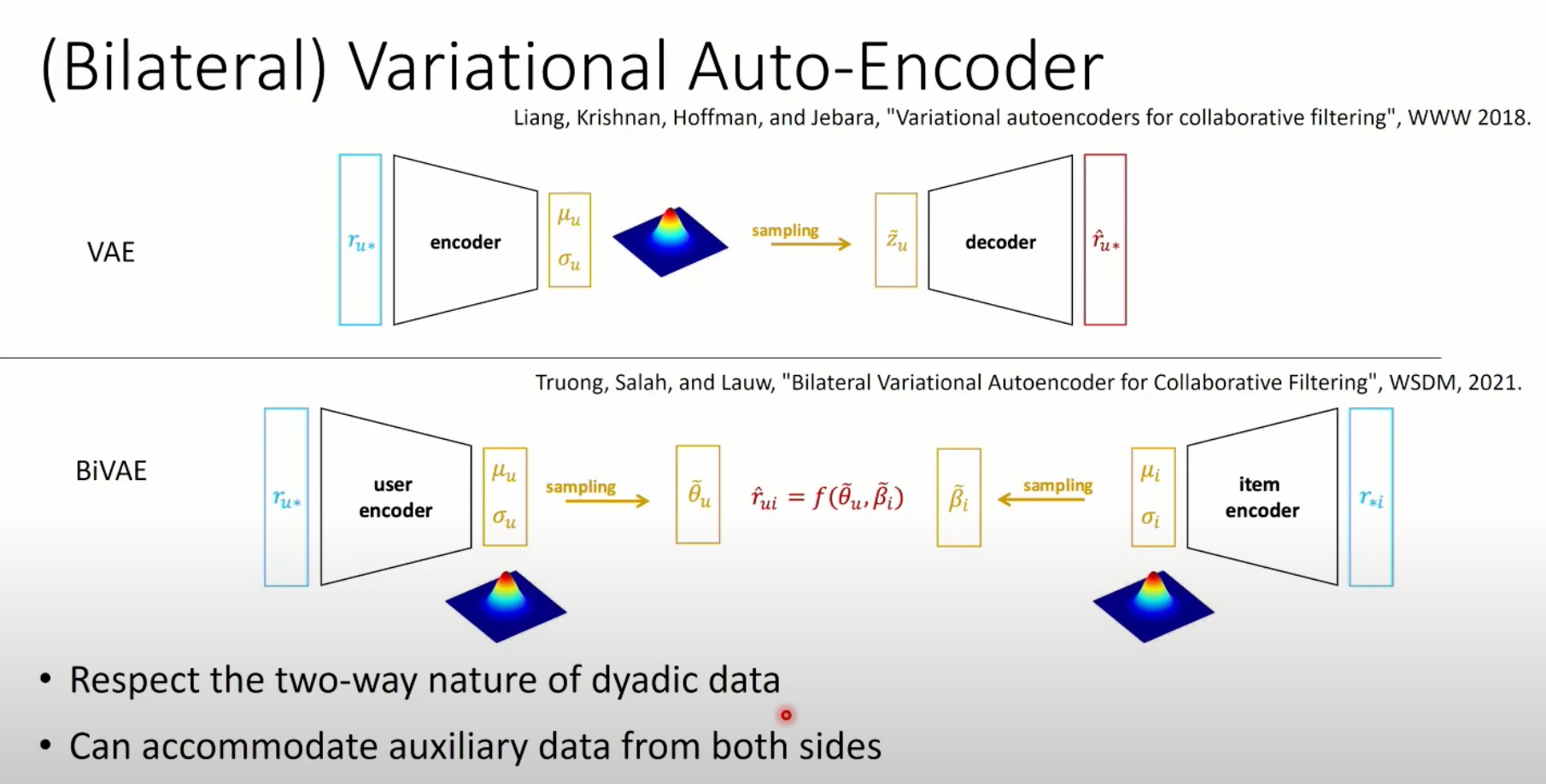
(双边)变量自编码器 VAE/BiVAE
- 尊重动态数据的双向性质
- 可以容纳双方的辅助数据
二、多模态推荐模型
| Image Modeling | Explicit(MF or PMF) | Implicit |
|---|---|---|
| Pre-trained Embedding | VMF, VPOI | VBPR, ACF, NPR |
| Convolutional Neural Nets | DVBPR, CKE, CDL,JRL |
1. Visual Bayesian Personalized Ranking (VBPR)
VBPR是BPR算法的扩展,相对于BPR算法增加了图像特征。BPR是一种基于建模用户对物品的偏序关系的矩阵分解方法。
定义用户 $i$ 对物品 $j$ 的偏好分如下:
其中,
- $\alpha, b_i, b_j$ 为全局偏置,用户偏置和物品偏置;
- $\mathbf{u}_i \in \mathbb{R}^K$ 为用户隐向量;$\mathbf{v}_j \in \mathbb{R}^K$ 为物品隐向量;
- $\mathbf{f}_j \in \mathbb{R}^D$ 为物品的图像特征向量;
- $\mathbf{p}_i \in \mathbb{R}^Q$ 为用户的视觉偏好特征向量;$(\mathbf{E} \times \mathbf{f}_j) \in \mathbb{R}^Q$ 为物品的视觉表示向量,通过 $\mathbf{E} \in \mathbb{R}^{K \times D}$ 从特征空间投影到偏好空间(这里可以简单理解为维度调整);
- $\mathbf{\Theta} \in \mathbb{R}^D$ 为全局视觉偏置向量;
学习过程通过最小化负对数似然函数来完成:
备注:全局偏置 $\alpha$ 和 用户偏置 $b_i$ 不影响物品的排序,所以从损失函数中移除。
2. Deep Visual Bayesian Personalized Ranking (DVBPR)
paper: Visually-Aware Fashion Recommendation and Design with Generative Image Models
定义用户 $i$ 对物品 $j$ 的偏好分如下:
其中,$\Phi(\cdot)$ 表示提取图像特征的深度神经网络模型。相比于VBPR,商品偏置 $b_j$ 和 非视觉的隐向量被省略,因为作者通过实验发现这么做效果更好。
损失函数:
备注:全局偏置 $\alpha$ 和 用户偏置 $b_i$ 不影响物品的排序,所以从损失函数中移除。
3. DeepStyle
paper: DeepStyle: Learning User Preferences for Visual Recommendation (SIGIR’17)
定义用户 $i$ 对物品 $j$ 的偏好分如下:
其中,$c_i$ 表示物品图像的类目信息,从图像特性中减去该项的目的是为了提取到更重要的风格信息。
相比于VBPR,DeepStyle使用相同的用户隐向量来与图像特征和物品隐向量交互。
4. Visual Matrix Factorization (VMF)
paper: Do “Also-Viewed” Products Help User Rating Prediction? (WWW’17)
类似于VBPR,VMF定义用户 $i$ 对物品 $j$ 的偏好分如下:
不同的是,学习通过最小化 MSE 而不是 BPR criteria:
损失函数:
5. Attentive Collaborative Filtering (ACF)
ACF在建模用户的表示向量时,使用attention机制额外编码了用户的行为序列,其定义的用户 $i$ 对物品 $j$ 的偏好分如下:
其中,$u_i$和$v_j$分别是用户$i$和物品$j$的隐向量,${\mathcal R}(i)$是用户$i$交互过的物品集合,$p_l$是历史交互物品的隐向量,$\alpha(i,l)$是attention的权重。
上述公式可以改写为:
ACF模型的网络结构如下: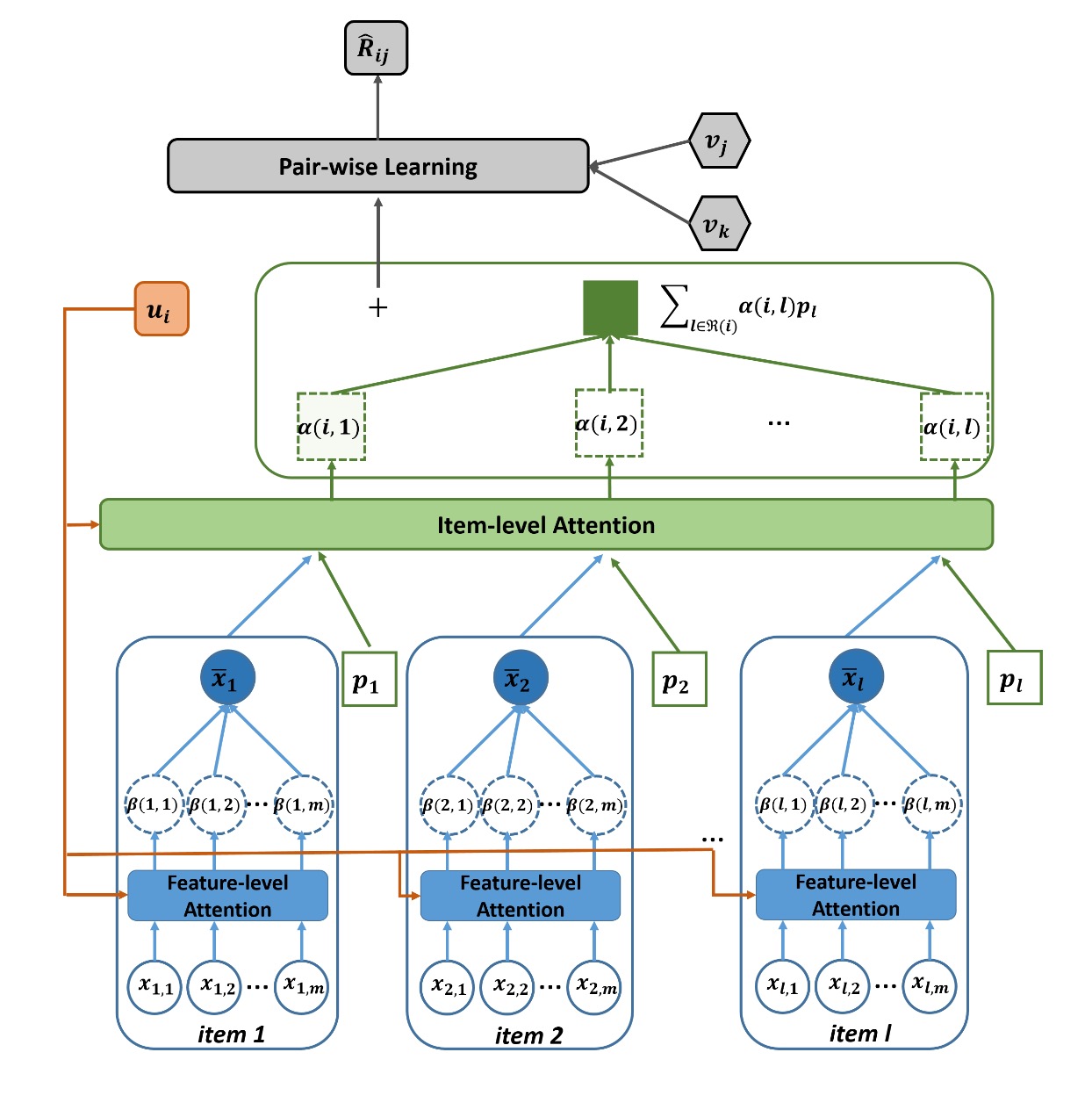
ACF模型使用了两个层级的Attention机制来编码用户的向量表示,分别是component-level和item-level。使用component-level的注意力机制的动机是认为用户对物品的不同component的兴趣度是不一样的,我们需要找出用户真正感兴趣的组件。item-level的注意力机制编码了用户对历史交互过的物品不同的兴趣程度。注意力权重的计算使用了2层的MLP,公式如下:
其中,$\phi(x)=max(0,x)$为ReLU激活函数,$\bar{x}$是使用component-level的注意力机制得到的物品内容表示,编码了物品的视觉信息(如图像特征)。
作者提出的物品的视觉组件主要有两种类型:
- 图像的空间区域
- 视频的帧
6. PinSage
paper: Graph Convolutional Neural Networks for Web-Scale Recommender Systems (KDD’18)
PinSage是基于随机游走的图卷积神经网络模型,它能够学习大规模图的节点embedding(稠密向量表示),这些节点embedding包含了物品的视觉特征。推荐结果可以通过在embedding空间中查找目标节点的近邻获得。
关键创新点:
- 即时更新的卷积操作(On-the-fly convolutions)
传统的图卷积算法需要计算特征矩阵与全图Laplacian矩阵的幂,当图的规模非常巨大时该操作将变得不可行。PinSage通过从邻居采样并动态构建计算图的方法,可以高效地、局部地执行卷积操作。
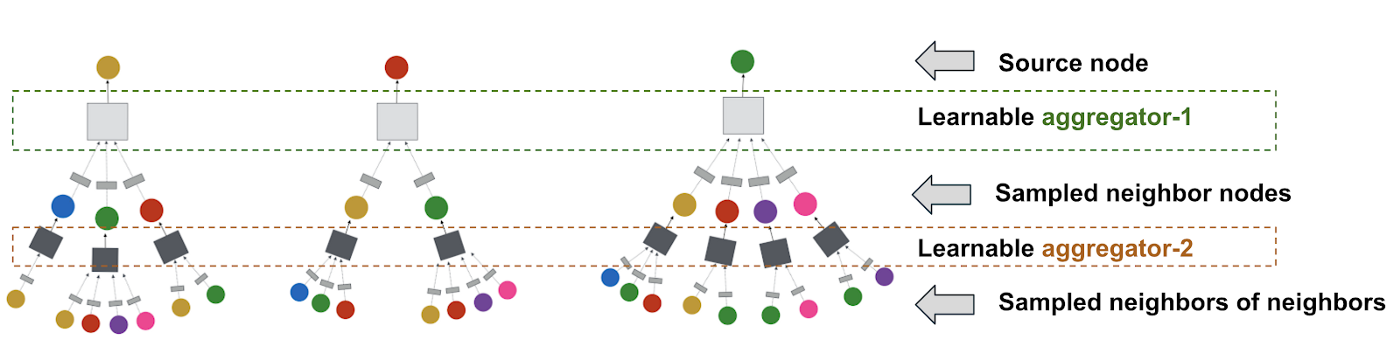
Example of computation graphs we dynamically construct for performing localized graph convolutions. Here we show three source nodes (at the top) for which we are generating embeddings. For each source node, we sample its neighbor nodes and we further sample neighbor nodes of each neighbor, i.e., here depth is 2. Between the layers are learnable aggregators parameterized by neural networks. Aggregators are shared across different computation graphs.
- 通过随机游走构建卷积操作
为了避免在所有邻居上执行卷积操作,PinSage通过采样的方法获取固定数量的邻居,在采样的过程中会考虑邻居的重要度(importance pooling)。
- 基于MapReduce的高效推理
通过上图的层次结构来设计“map-join-reduce”操作,避免重复计算。
- 离线评估
Pinterest data: Pin-board的二部图。
输入特征包括:
- 图像embedding: 通过state-of-the-art的CNN模型得到
- 文本标注的embedding: 类Word2Vec模型获得
评估指标:Recall、MRR(Mean Reciprocal Rank)
7. AMR
paper: Adversarial Training Towards Robust Multimedia Recommender System (IEEE’2020)
作者提出现有的视觉多模态推荐模型不够鲁棒,在输入图像上添加一个小的人为噪音扰动(对抗样本)后,推荐列表的排序可能发生较大的改变,如下图所示。
因此,作者借鉴视觉安全领域的思路提出了一种对抗训练的方式,来得到更加鲁棒和高效的推荐模型,并通过实验证明了对抗训练确实能够提高模型的效果。我们可以简单地认为对抗训练是一种特殊的数据增强方法。
总体思路:AMR模型的训练过程可以理解为一个玩 minimax 游戏的过程,扰动噪音通过最大化VBPR的损失函数得到,而模型的参数通过最小化VBPR损失函数和对抗损失函数获得。类似于GAN模型的思路,通过这种方式强迫模型变得更加健壮。
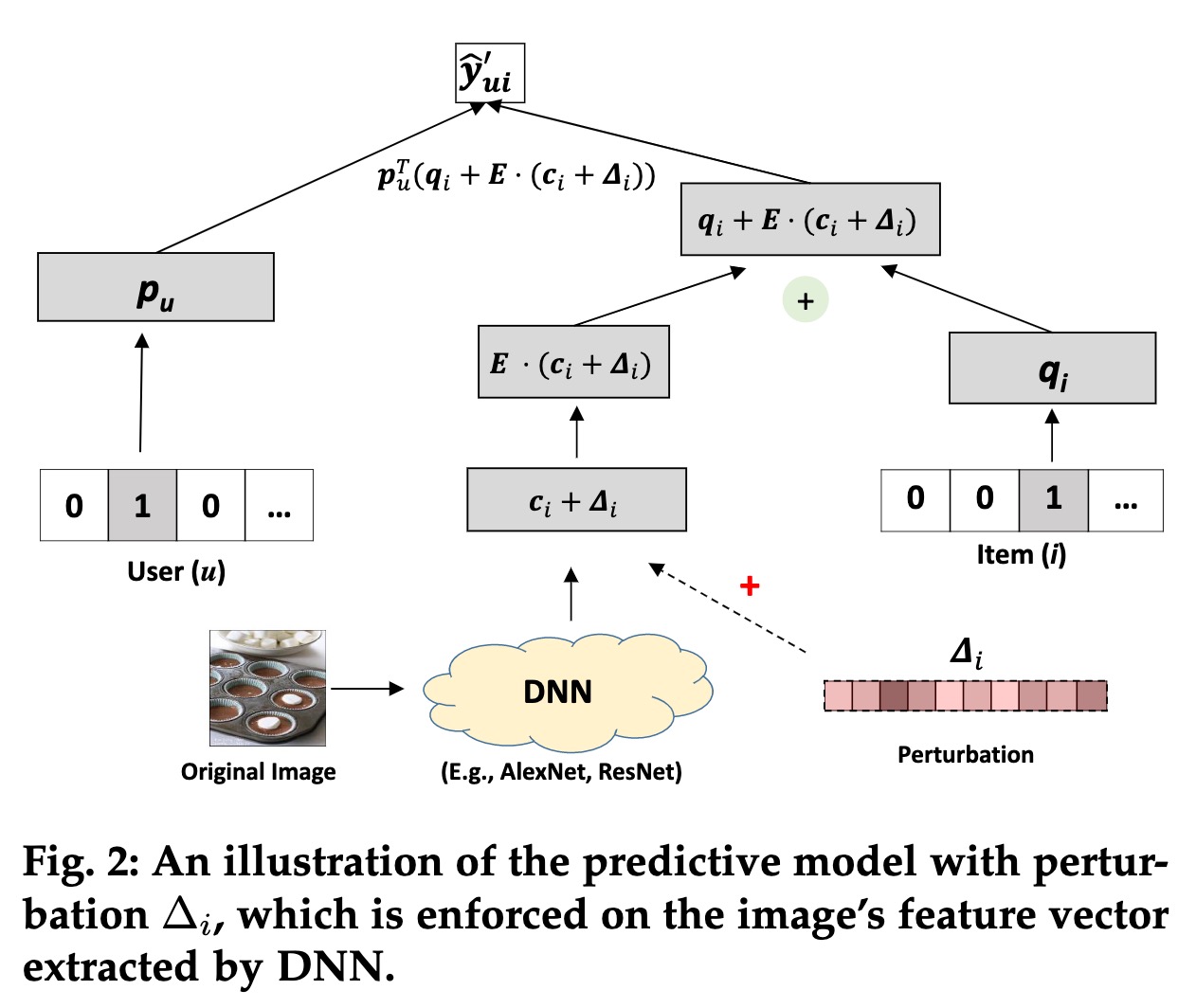
由于图像特征提取的模型通常与推荐模型是分开训练的,因此作者提出对抗扰动直接添加在提取出的图像表示(embedding)上。推荐模型的训练还是采用了VBPR的框架。
定义用户 $u$ 对物品 $i$ 的偏好分如下:
其中,$\Delta_i$ 表示添加到图像embedding上的扰动噪音,其通过最大化BPR损失函数获得,如下:
其中,$||\Delta_i|| \le \epsilon$,$\epsilon$ 是控制扰动量级的超参数。
模型的参数通过优化下面的损失函数获得:
其中,$\hat{y}_{ui}=p_u^T (q_i+E\cdot c_i)$ 为不加扰动噪音时用户对物品的偏好分;$\lambda$ 为控制对抗训练强度的超参数,当 $\lambda=0$ 时,AMR降级为VBPR;对抗损失 $L_{BPR}’$ 可以看作是一种特殊的正则项(adversarial regularizer)。
源代码:https://github.com/duxy-me/AMR
8. CausalRec
paper: CausalRec: Causal Inference for Visual Debiasing in Visually-Aware Recommendation (ACM MM’21)
视觉偏差(visual bias):用户对于视觉特征的注意力并不总是反映用户的真实偏好,用户可能会因为视觉满意而浏览某物品,但可能因其他关键属性不满足用户的真实需求而拒绝购买。
在推荐系统中,视觉偏差与其他偏差,如位置偏差、选择偏差、热度偏差等,一同呼吁纠偏方法的应用。最近的研究显示,因果推断(causal inference)在移除嵌入在数据中的偏差方面展现出了很大的潜力。
因果推断在移除视觉偏差上的原理和公式推导比较复杂,这里省略不表,直接给出CausalRec模型的学习过程。
其中,$\circ$ 表示Hadamard积,即element-wise的向量乘法;$\gamma_u,\gamma_i$ 分别表示用户、物品的隐向量;$\theta_u$ 是用户的视觉偏好向量,可以与$\gamma_u$相同;$V_i$为视觉特征向量;$\sigma$ 为sigmoid函数。
采用多任务学习范式来训练模型,损失函数为:
其中,$l_{rec}$为BPR损失函数:
9. CMBF
paper: CMBF: Cross-Modal-Based Fusion Recommendation Algorithm
CMBF是一个能够捕获多个模态之间的交叉信息的模型,它能够缓解数据稀疏的问题,对冷启动物品比较友好。CMBF的模型的框架如下:
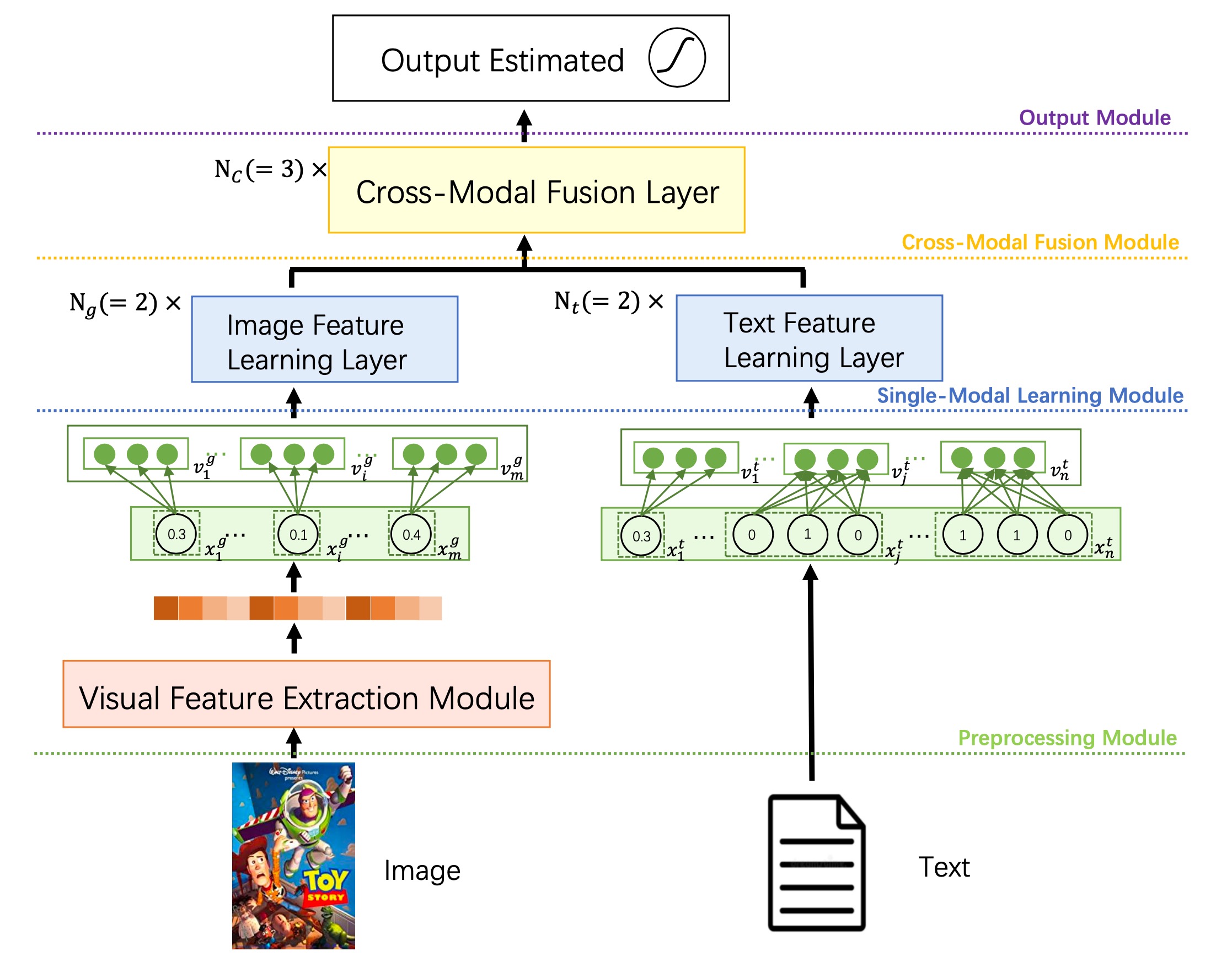
CMBF主要有4个模块:
- 预处理模块:提取图片和文本特征
- 单模态学习模块:基于Transformer学习图像、文本的语义特征
- 跨模态融合模块:学习两个模态之间的交叉特性
- 输出模块:获取高阶特征并预测结果
视觉特征提取模块通常是一个CNN-based的模型,它获取到图像的CNN Layer之后的特征,保留多个CNN filter的结果,以便后续接入transformer模块。
文本特征为多个其他常用特征的拼接,包括数组特征、单值类别特征、多值类别特征,每个特征需要转换为相同维度的embedding,以便接入后续的transformer模块,具体操作如下:
单模块学习模块采用标准的transformer结构,如下: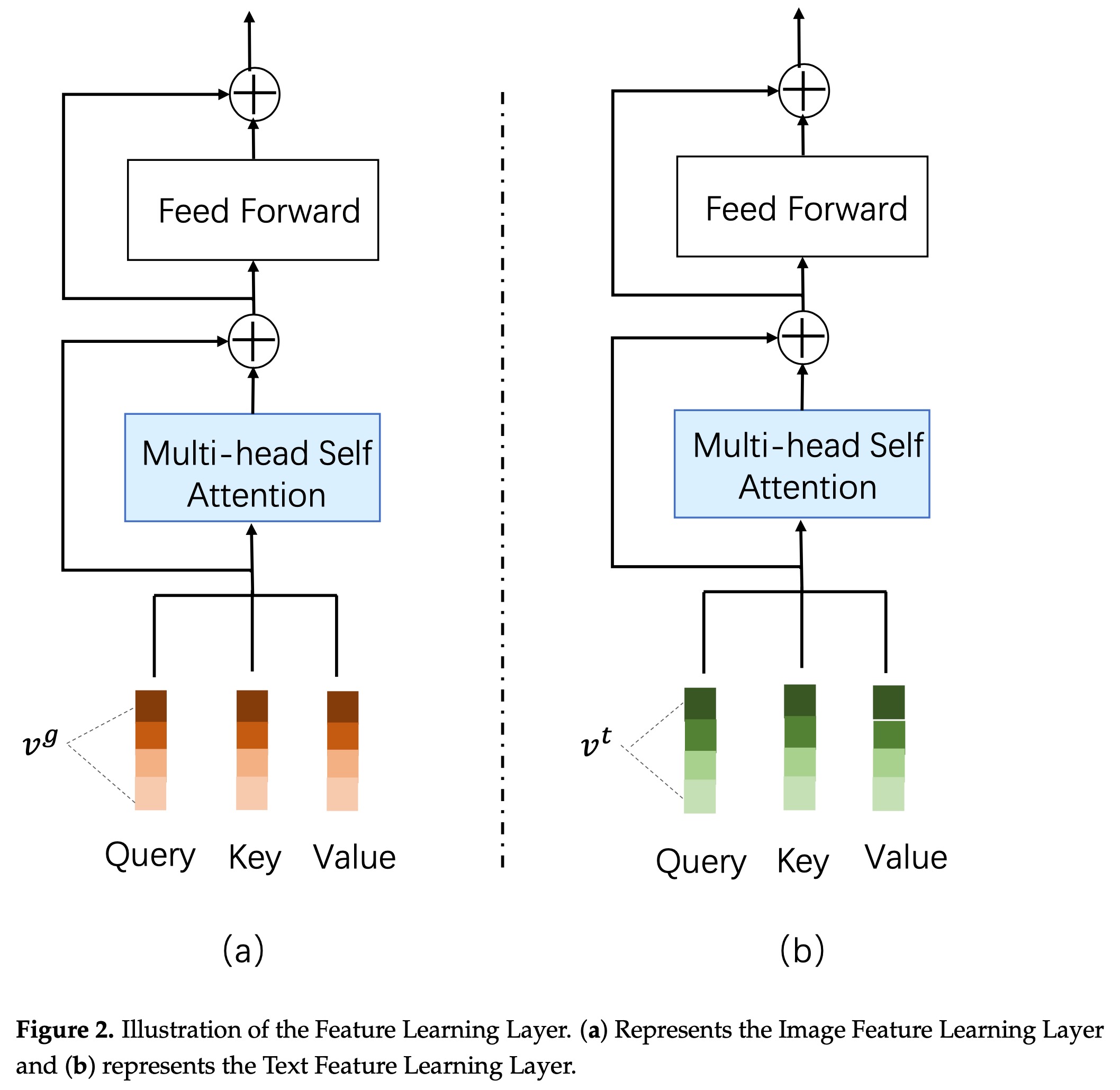
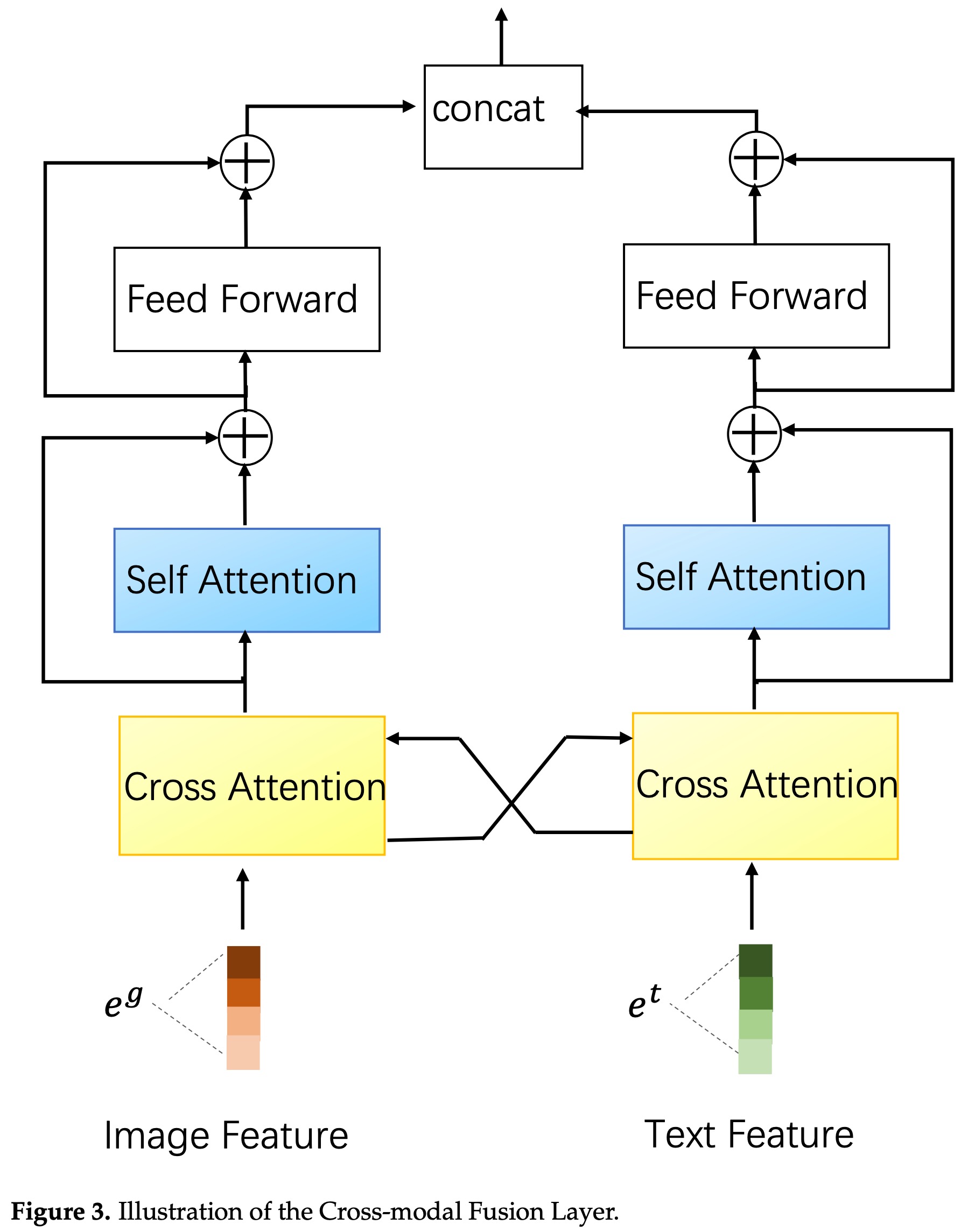
跨模态融合模块使用了一个交叉attention的结构,如下:
10. MM-Rec
paper: MM-Rec: Multimodal News Recommendation
有些业务场景物品的图像和文本信息彼此之间有较强的关联性,比如,新闻的标题和封面图、商品的标题和图片等。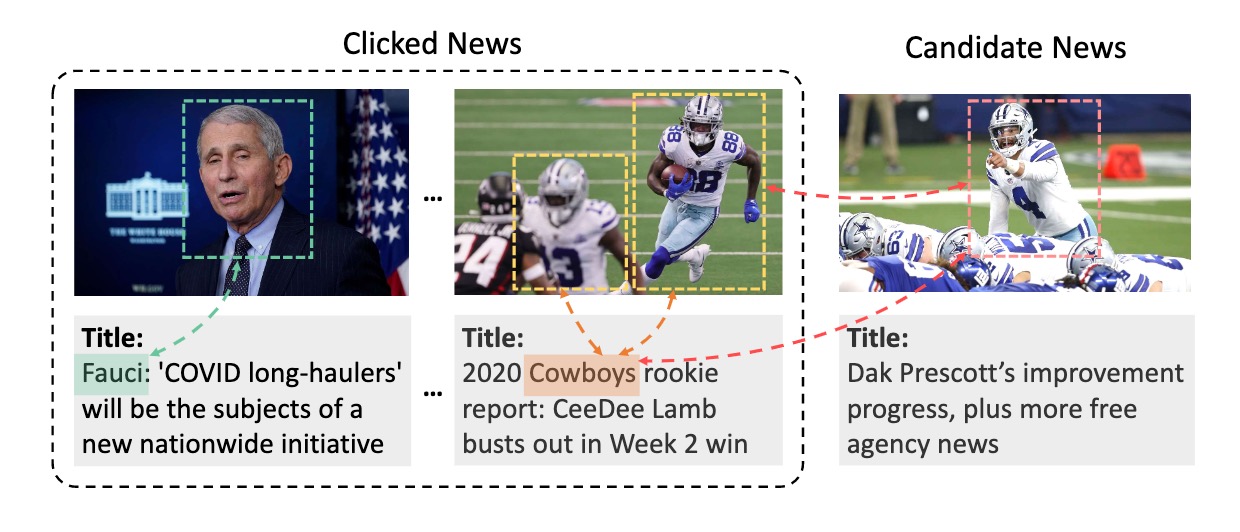
用户点击查看物品不仅仅因为对物品的文本描述信息(标题等)感兴趣,也可能是被物品的图像所吸引,因此显式建模图像和文本,可以得到更好的图像特征表示和文本特征表示。MM-Rec模型就是一种这样的模型。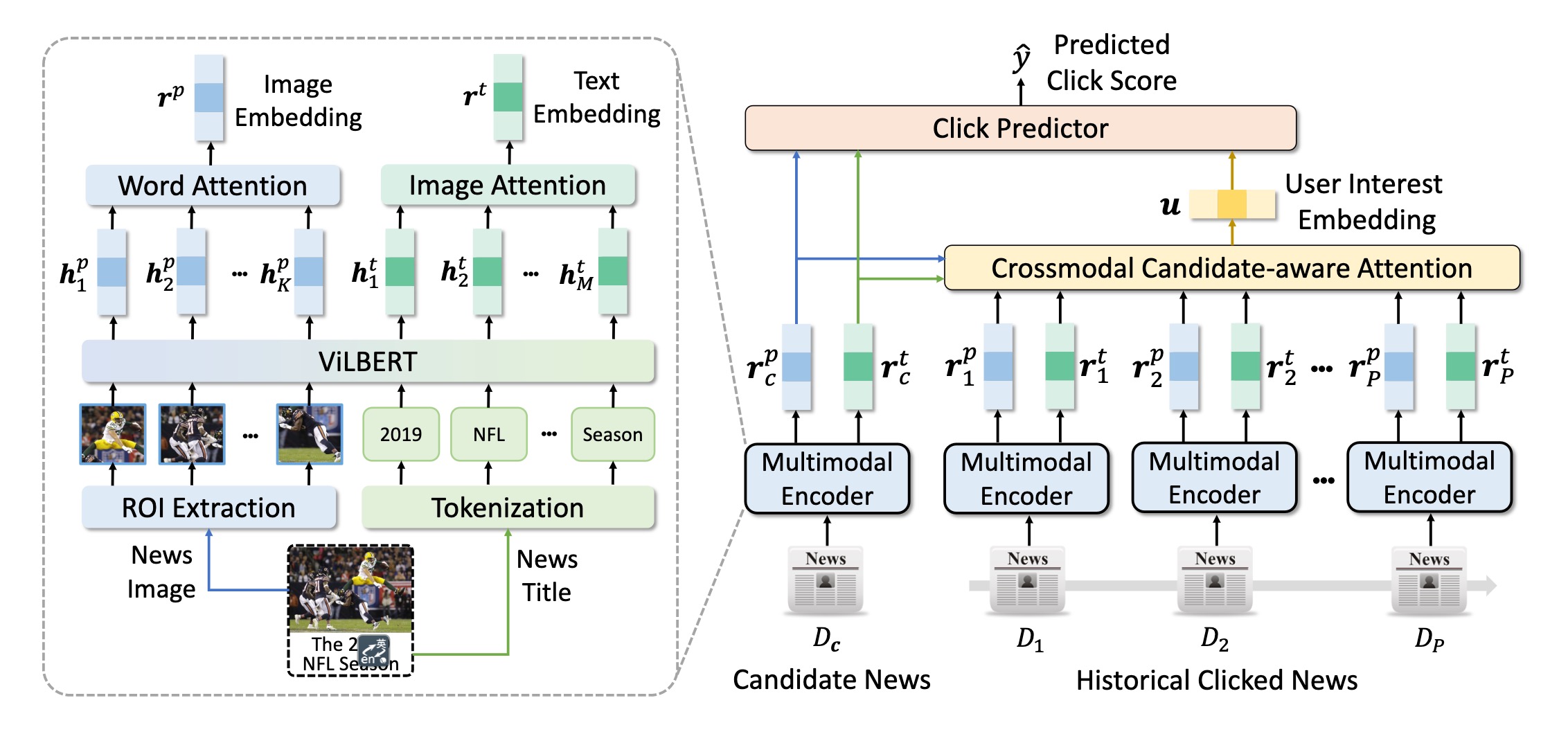
MM-Rec的模型结构主要包括三个重要组件: 多模态编码器(Multimodal Encoder)、基于候选感知跨模态注意力机制的用户表示生成模块、目标预测模块。
a) 多模态编码器(Multimodal Encoder)
由于图像的不同区域有不同的信息量,MM-Rec首先使用目标检测的预训练模型(Mask-RCNN)从原始图像中提取兴趣区域(ROI, region of interest)序列,然后使用ResNet-50模型提取每个POI的特征向量,得到图像特征序列:$[e_1^p,e_2^p,\cdots,e_K^p]$。文本通过分词得到token序列。
使用预训练的视觉语言模型ViLBERT来捕捉文本与图像之间的相关关系,从而得到ROI与token的特征表示向量。接着,使用注意力机制把POI特征序列聚合为图像embedding($r^p$);同样使用注意力机制把token的特征序列聚合为文本的embedding($r^t$)。
b) 基于候选感知跨模态注意力机制的用户表示生成模块
这里的思路类似于推荐的DIN模型,用户的特征表示基于用户的历史点击行为得到。在候选物品给定的情况下,不是每一个用户历史点击过的物品都对当前候选物品是否可能被点击有相同的贡献,因此,MM-Rec采样了Candidate-aware Attention的方式来聚合用户的历史行为物品的图像特征和文本特征,并且使用了跨模态的attention方式,包括文本到文本、文本到图像、图像到图像、图像到文本四个维度的attention。最后,通过聚合4个层面的attention结果得到用户的表示向量。
c) 目标预测模块
常规的负采样和交叉熵损失函数。

