一、背景概述
合规服务业务是基于法律法规建立的信息安全保障机制,保障电商平台的合规经营。商品合规风险指商家未能遵循国家有关法律法规、监管要求或平台制定的经营规则,在平台发布了禁止或限制销售的商品或服务。从发布内容的维度看,违规风险内容主要分为危害国家安全、民生安全、公共安全和市场秩序四大块内容。其中,危害国家安全的违规商品内容包括非法政治、枪支弹药、管制器具、军警用品、暴恐分裂渗透等;危害民生安全的违规商品内容包括毒品、危险化学品、管制药品、管制医疗器械、保护动植物等;危害公共安全的违规商品内容包括色情、低俗、赌博、个人隐私、作弊造假等;违反市场秩序的违规商品内容包括诚信交易类、公序良俗类等。大类的风险类别共计30余种。

坚守风险底线,为用户服务提供良好的制度保障,助力平台提供更简单、更友好的经营环境,保护消费者权益是商品合规业务的主要目标。在商品合规场景,内容维度的风险中文本违规占比约80%。通过商品标题文本的相似检索是发现新风险的有效手段之一。
二、问题与挑战
1. 审核标准复杂
大多数风险内容的判定需要专业的领域知识。比如,对保护动植物的判定就比较难,同样是鹦鹉或者乌龟,有些品种可能是保护动物,有些又可能不是。另外,国际法律、国家法律和省级法律对于保护动植物的范围圈定以及保护等级的规定都不尽相同。同时,虽然有些动植物被国家农业部列在保护动植物名录里,但出于商业目的,并未在平台保护,比如虫草、松茸等。保护动植物难以判定的另一关键原因是有很多我们日常生活中很难接触到的动植物,比如“砗磲”、“玳瑁”等,有很多动植物我们之前都没有听说过,对于它们是否属于保护动植物就更加缺乏认知了。其他的风险类目也有同样的问题,比如有些具有一定保健或治疗效果的化妆品、保健品、“卫消字号”的产品就很难从名称上判定是否属于管制药品。比如“众妥宝儿康霜剂乳膏软膏蚊虫叮咬皮肤止痒膏宝宝婴儿红屁屁婴幼儿”这款产品虽然药店也有卖,但是专业鉴定结果并不是管制药品,而是“卫消字号”的产品。
另外一方面,监管标准也在不断发生变化。每年均会有新的各类敏感事件发生,导致不同时期的标准会发生变化,比如,去年双11之前电子烟是可以在网络上销售的,但后来有个叫罗永浩的胖子大张旗鼓地说要在双11大卖电子烟,于是后来国家相关部门规定电子烟和香烟一样都不可以通过电商渠道销售。
同时,监管粒度也会细化或者抽象,与之相应地风险类目也会出现拆分或合并的情况。比如色情低俗会被拆分成两个类目,暴恐分裂渗透会从非法政治里独立出来作为一个新的管控风险类目,就像爆炸物会从危险化学品里拆分出来一样。监管标准或粒度的变化会导致与之相关的样本数目不足,会变成one-shot甚至zero-shot learning的问题。
2. 对抗变异严重
风险内容鉴定困难的另一原因是商家会隐晦地描述自己的产品或服务,试图把真实的信息隐藏起来,骗过机器审核算法。比如商品标题“中国剧院节目【崔凤鸣:岳府就亲、岳芝荆投水、进锣汉衣】”描述的商品实际上是在卖“催情水”(管制药品);“g 他最新手工打造方式 a5 无风率 线上无后顾之忧 详情咨询”表达的实际内容是“gta5”(一种被管制的暴力血腥游戏);“加我vxin fc2265 天然红高端吊坠 私人订制18k金镶嵌手链”描述的实际内容是“天然红珊瑚手链”(红珊瑚是保护动植物);“景点避暑山庄收藏挂历 LED显示屏白荷画 烟墨画作烟灰色背景挂历”是在卖“荷花牌香烟”(香烟禁止在网络上销售);再看“手机挂九游挂饰吊坠微信玉石玛瑙指环扣女款创意炸金花链短吊环”,真实意图隐藏得很好有没有?你能猜到这是在发布哪种类型的违规信息吗?(答案请继续往下看)
很显然,没有黑商家会毫不避讳直截了当地发布自己的违规信息,卖毒品的不会光明正大地说自己在卖毒品,发布色情内容的商家也不会开门见山地说自己在散播小黄片,也不会有人单刀直入地说自己在贩卖枪支弹药,更不可能有人会斩钉截铁地说要分裂国家主权(我感觉这句话可能会被机器算法识别为“非法政治”违规)。他们一定会绞尽脑汁 拐弯抹角 迂回曲折 闪烁其辞 旁敲侧击 指桑骂槐地搞出新花招来绕过现有的机器识别算法。这对审核算法的时效性提出了很高的要求,一般的分类模型很难主动识别出新的变异,模型重新训练升级部署的周期又比较长,在这方便会比较被动。而基于相似检索的算法方案则可以快速捕捉到新的变异内容。
对抗变异是黑内容试图“洗白”自己,与之相反的是平台上也存在一定比例的白内容试图“描黑”自己。这么做的动机当然是为了跟黑灰产抢流量了,黑灰产之所以存在是因为真实世界里存在这样的需求,有需求就会有流量。“描黑”自己其实跟标题党没什么区别,就是为了吸引眼球,获得更多的曝光机会。比如,有些卖内衣的商家会使用一些特别露骨的低俗词;更常见的是随意堆砌一些不相关的词汇。不管是“洗白”还是“描黑”,都给风险鉴定增加了很大的难度。
3. 数据噪声大
标签数据对于相似模型至关重要,因为我们要的相似模型并不是常规意义上的语义相似度模型,而是能够判别风险类型的相似模型。通过前面的例子,我们可以看到一段商品文本可能会同时描述多重语义,而其中违规的语义通常比较隐晦,因此我们需要让模型能够关注违规语义,而忽略正常语义。从这个意义上讲,干净的标签信息是必不可少的。
缺乏干净的标签数据这个问题产生的原因就非常多了,列举一二如下:
- 业务的违规风险类目标签是打在商品这个实体上的,而不是算法需要的商品标题这一维度上的。违规商品的违规内容可能出现在标题、副标题、详情、图片、视频、SKU等任意属性上,因此我们不知道在一个商品违规的前提下,商品标题本身是否违规。
- 商品被处罚可能仅仅是因为发布这个商品的商家的某些行为,而不是商品内容本身。经常发布违规内容的恶意商家发布的所有商品都有可能被判定违规,哪怕实际内容是正常的,比如,积分消耗完,被全店删除。我们发现了很多黑灰产借正常商品的壳发布违规商品的案例。
- 由于审核人员的失误,商品审核时被张冠李戴地打上了错误的风险标签。
- 管控标准发生了变化,比如19年双11前电子烟还不在管控范围内,现在已经全面禁售了。
- 标签本身的变化。风险类目体系存在拆分、合并和迁移的可能,但是历史被处罚商品不会重新关联上新的风险类目。我们还发现因为种种原因,不同层级的风险类目之间还存在重叠的现象,即不同类目都可以包含相同内容的商品。
4. 样本空间大且开放
样本空间大很好理解。近亿级别的处罚商品,几十亿的在线商品。大数据带来工程实现的复杂性和较长的迭代周期。同时,因为样本空间是开放的,用户随时可能发布任意内容的商品,这对算法的鲁棒性提出了很高的要求。
三、技术方案
1. 整体框架
整体思路是根据新商品与已有违规商品的相似程度来判定新商品是否违规。所以要训练一个商品文本相似度模型。目前,学习相似度的深度学习范式主要有两种,如下图所示。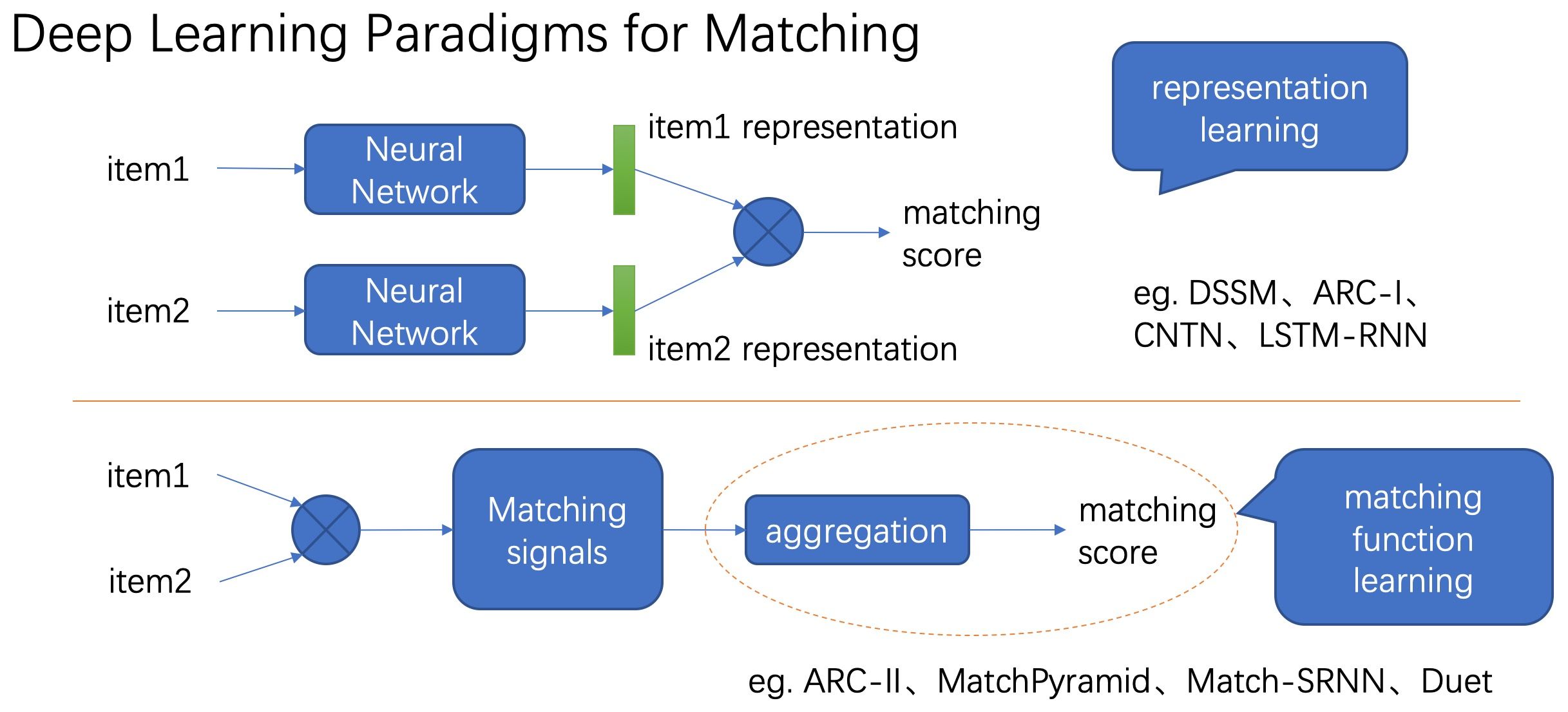
第一种范式是首先通过深度神经网络模型提取输入的表示向量,再通过表示向量的简单距离函数(eg. inner product)计算两者的相似度。这种方式在提取表示向量的过程中只考虑当前输入,不考虑要与之计算相似度的另一个输入的信息,通常用孪生网络来实现。第二种范式是通过深度模型提取两个输入的交叉特征,得到匹配信号张量再聚合为匹配分数,该方式同时考虑两个输入的信息,因而一般情况下效果要更好,不足之处在于预测阶段需要两两计算相似度,复杂度较高。
由于新商品与已有违规商品的数量级都巨大,因此我们不可能全部两两组成对输入给模型预测是否相似,因此第二种范式并不适合用在风险召回阶段。本文主要关注第一种范式的建模,既模型单独提取各个输入的表示向量,这样已有违规商品的表示向量可以提前离线提取好,在线服务只需要提取输入新商品的表示向量,然后通过向量检索引擎查询top K个最相似的邻居,再跟进KNN算法判定分类结果即可。整体的框架概述如下。
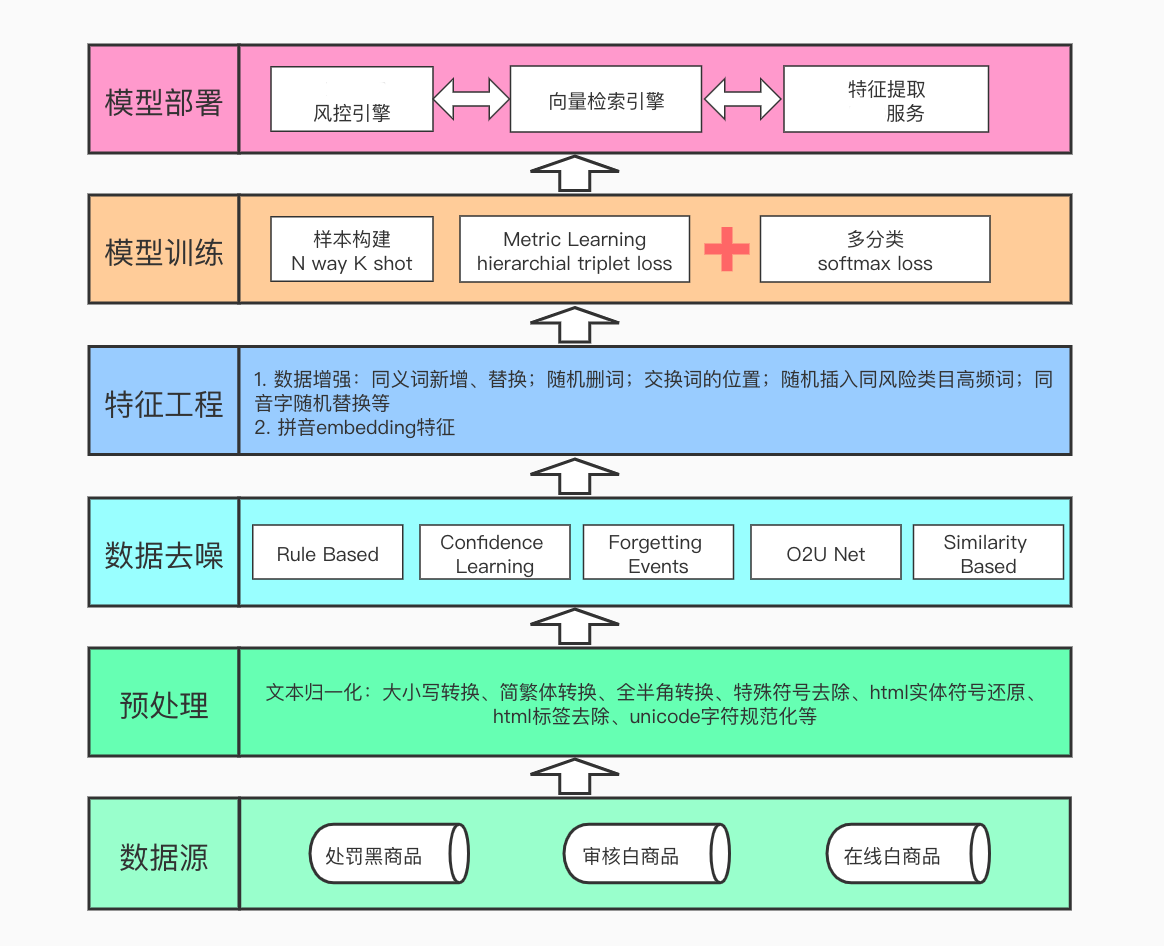
2. 噪音标签数据清洗
初略估计,噪音标签的比例高达44%(和外包人工审核不一致的比率),严重影响算法的效果。数据质量决定了业务效果的上限,而算法只能决定多大程度上逼近这个上限。因此,第一步需要清洗脏数据。
目前基于带噪标签数据的学习方法主要有两大类,一类是直接训练对噪声鲁棒的模型(noise-robust models),另一类方法首先识别出噪声数据,然后基于清洗后的数据训练模型。我们主要关注第二类方法,因为我们的目标是挖掘关键词规则集,由规则集构成的风险识别模型并不具备对噪声鲁棒的能力。尝试过的去噪方法简单介绍如下。
a. 基于Confidence Learning识别错误标签
Confidence Learning是一种弱监督学习方法,它能够识别错误标签。Confidence Learning基于分类噪声过程假设(classification noise process ),认为噪声标签是以类别为条件的,仅仅依赖于潜在的正确类别,而不依赖与数据。通过估计给定带噪标签与潜在正确标签之间的条件概率分别来识别错误标签。
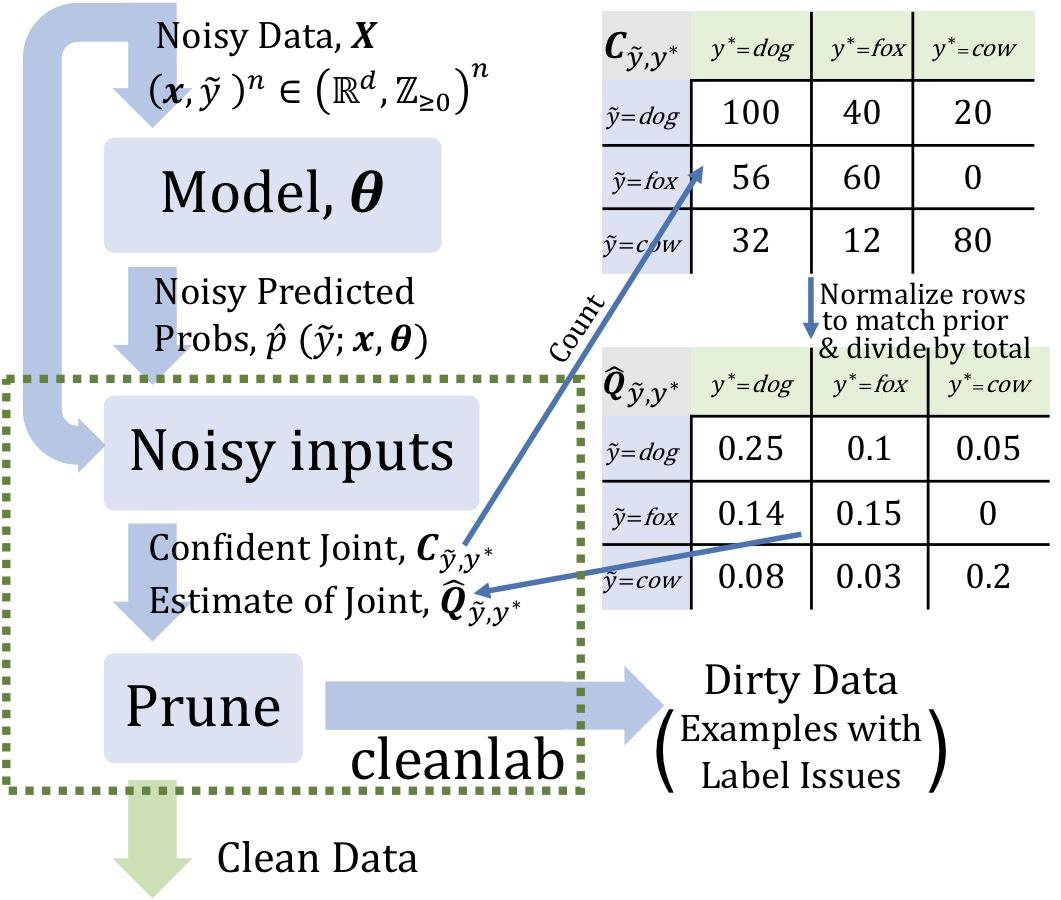
Confidence Learning只依赖两个输入:模型的样本外预测概率和带噪标签。学习过程首先通过预测标签与标注标签的计数矩阵估计带噪标签与潜在正确标签之间的条件概率分布,然后根据该条件概率分布和样本预测概率来识别噪声标签。
b. 基于Forgetting Events识别错误标签
在模型训练过程中,某个样本已经被模型正确分类,随着模型参数的更新,该样本又被错误分类,这一过程被称之为该样本的一次遗忘事件(forgetting event)。根据论文《AN EMPIRICAL STUDY OF EXAMPLE FORGETTING DURING DEEP NEURAL NETWORK LEARNING》的研究,在模型训练过程中噪声样本往往会比正常样本经历更多的遗忘事件。基于这一启发式规则,我们可以记录下每个样本经历的遗忘事件总次数,进一步辨别出可能的噪声标签数据。
c. 基于训练过程的样本loss值识别错误标签
基于训练过程中样本的loss值的相对大小来识别错误标签,这一方法是淘系技术部的同学在ICCV2019的论文《O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks》中提出的。
大致思路基于以下逻辑:在一次训练中,随着迭代轮次增加,网络逐渐从欠拟合逐渐过渡到过拟合状态,在训练的初期,模型精度的提升是非常明显的,因为网络很快学会了那部分“简单的”样本,因此这类样本的loss比较小,与之相反,那些“困难的”样本通常在训练的后期才逐渐被学会。观察训练过程发现,噪声样本通常是在训练的后期才被学会,因而在训练的早期,噪声样本的平均loss是远大于干净样本的,而在训练的后期,因为网络逐渐学会了所有样本,两类样本的loss区别不大。纵观整个训练过程,从欠拟合到过拟合,噪声样本loss的均值和方差都比干净样本要大。通过循环学习率策略,使网络在欠拟合和过拟合之间多次切换,并追踪不同阶段不同参数的模型对样本的loss,通过在时间维度上捕获多样性足够丰富的模型(类似集成学习,对满足多样性和准确性的多个模型进行ensemble),统计各个样本loss的均值和方差,均值和方差越大,样本属于噪声样本的概率也就越大。
d. 基于样本相似度识别错误标签
基于样本相似度识别错误标签的思路也很简单,首先要训练一个样本相似度模型,然后采样一批置信度较高的白样本,计算白样本与黑样本之间的相似度。识别出与白样本相似度大于阈值,且能多次匹配上白样本的黑样本集合。这些黑样本集合很可能就是噪声标签数据。
e. 基于业务理解及人工规则识别错误标签
通过数据分析,我们发现部分噪声标签的来源具有一定的规律,通过这些规律可以提取出一些简单有效的过滤规则,可以直接清除掉一定数量的噪声标签数据。
例如,一些黑灰产商家主要通过图片来传递违规内容信息,为了规避审查他们发布的商品标题可能是一些无意义的字母和数字,或者是伪装成正常的商品描述。其中,无意义的字母和数字可以通过简单的字符类型识别来定位,我们总共检测出十万量级的无意义标题。另外,通过查看各个风险类目下风险点的定义和数据样本,提炼出一些系统性标签错误的规律,比如“军警用品”违规类目下不当使用国旗、国徽、党旗、党徽的风险点下标题不含“国旗、国徽、党旗、党徽”文字的商品一般是图片违规;图片类“暴力血腥”风险点下标题文本一般没有问题;保护动植物“情节特别严重”风险点下有很多恶意会员店铺正常商品连带处罚;以及不规范展示类“管制刀具”和摄影录像设备(涉嫌“个人隐私”违规)等。这些风险类目下是黑样本商品通常可以直接过滤,或者添加关键词匹配约束后过滤。
f. 实践及思考
观察并分析数据,从数据中总结规律,通常是每个项目首先应该做的事情,并且值得投资更多时间和精力。然而,由于该过程比较繁琐,且显得没有技术含量,所以经常被我们忽略或轻视,最终导致事倍功半。回头总结数据清洗的实践,我们发现基于业务理解及人工规则识别错误标签是非常有效,能够过滤掉几十万到百万量级的噪声样本,并且能够修正部分错误标签,同时也能够给后续的学习过程提供不错的启发。
我们的实验结果表明基于Confidence Learning识别错误标签的方法,以及基于Forgetting Events识别错误标签的方法,还有基于训练过程的样本loss值识别错误标签的方法,在单独使用的时候效果均不是十分令人满意。虽然他们都能够识别出一定量的错误标签,但同时也会把一部分比较难学的黑样本错误地当成噪声标签,这部分的比例取决于阈值的设定。个人觉得这三种方法的前提假设都不是必然成立,仅仅是基于经验的总结,它们的实际效果一定程度上收到训练样本分布的影响。比如,有黑灰产大量借助“儿童文具”这个类目下的正常商品的“壳”发布违规内容,并且我们在采样白样本时“儿童文具”这个类目下的白样本采样数量刚好较少时,上述三种方法均有很大可能会把该类目下的正常白样本识别为噪声,同时不能够识别出伪装的黑样本,产生本末倒置的错误效果。毕竟,谁黑谁白(label的正确与否)对模型来说本来就分不清,最终的结果取决于谁占了更大的比例。这也正是黑灰产厉害的地方,通过样本数量来混淆模型视听的做法有点类似于DDos攻击。最终,我们把三种方法集成在一起使用,是集成学习的一种思路,三个臭皮匠,顶个诸葛亮。
基于样本相似度识别错误标签的方法,虽然想法比较原始,但实际效果还是不错的,噪声标签的检测比较准确。当然,识别效果很依赖于相似度模型本身的性能。
3. 类别相似度模型
首先要解释一下类别相似度与语义相似度的区别。假设每段文本都表达了多重语义,那么语义相似度模型会判定两段语义重合度较高的文本是相似的,而类别相似度模型则要关注两段文本是否都提及了某种特定类型的语义,而不在乎这两段文本整体的语义重合度。举例说明如下:
- 手机挂九游挂饰吊坠微信玉石玛瑙指环扣女款创意炸金花链短吊环
- 玉石菩提手机扣指环挂绳短款手机挂饰挂件吊坠手机链短男女指环扣
- 炸金花透视辅助 详情私聊
- c 美诗美童田慧新款炸金花背心透视成人男款拉丁练习舞服 zq n01
语义相似度模型可能会判定文本1与文本2更相似,而类别相似度模型则会判定文本1与文本3更相似,因为它们有相同的风险标签:作弊造假。同样,类别相似度模型也会判定文本1和文本4是相似的,而语义相似度模型则可能会判定它俩不相似。
我们最终的目标是学习一个能够表示文本标签信息的embedding向量。学习到的向量空间需要能够很好地区分不同的风险类别,也就是说,相同类别的风险文本映射到向量空间中相近的位置,不同类别的风险在向量空间中的距离较远。
语义相似度关注整体语义,要求学习到的embedding向量能够尽可能还原原始输入;而类别相似度仅关注局部语义,既是否在预定义的标签维度上相似。定位不同,则解题思路也不同。语义相似度对应representation learning,而标签相似度对应的解决方案是metric learning。虽然两种技术思路有很大比例的交叉重叠,但是细微的不同可能会对业务效果产生蝴蝶效应般的影响。在风控领域,我们通常不管监管对象表达了多少正常的语义,我们只对监管对象是否触发了某种类型的违规敏感。我们的模型需要识别出隐藏在多种正常语义之下的违规风险语义。
3.1 文本Encoder
模型的设计借鉴了深度度量学习(Deep Metric Learning)的思想,目标是学习一个映射函数$f(x, \theta)$,该函数能够把输入映射到一个固定维度的embedding空间,使得输入在该embedding空间中的距离由彼此之间的标签相似度决定。函数$f(x, \theta)$可以是任意结构的深度神经网络。具体地,我们希望相同类的输入映射到embedding空间中距离较近的位置,不同类的输入在embedding空间中的距离也较远。

模型结构的选择需要考虑两方面的因素:
• 足够强大的特征提取能力,能够学习到较好的representation
• 速度足够快,在inference阶段Response Time足够短
基于此,对NLP领域的3大特征提取器(CNN、RNN、Transformer)逐一分析后选择了Transformer作为模型的building block。单层CNN缺乏长距离特征依赖的建模能力,而在商品合规领域长距离组合特征依赖是一类较常见的问题。例如:“v 美洲象皮 鞋子内翻式皮鞋n休闲翻低帮帆美国鞋n男鞋”,需要提取“vpn美国”这样的特征;“【崔凤鸣:岳府就亲、岳芝荆投水、进锣汉衣】”,需要提取出“崔亲水(催情水)”这样的特征。RNN由于顺序依赖的问题不能很好地并行计算,速度比较慢;同时商品标题文本是由高度SEO优化的关键词堆砌组成的,整体上也不具备自然语言的顺序特性。Transformer的self-attention机制能够较好地解决长距离依赖的问题,可以提取不受位置约束的组合特征,同时可以很好的并行计算,速度也较快。
综上,最终选择了小尺寸的Albert模型作为文本特征提取器。使用小尺寸的albert是出于效果和计算性能的考虑,希望模型在线使用时inference时间足够短,经测试速度比bert_base快4倍。
3.2 Softmax loss vs Triplet loss
损失函数指导模型如何学习。Triplet loss是Metric Learning领域经典的损失函数,最初用在人脸识别领域。该loss函数要求样本由三元组(anchor, positive, negative)组成,其中positive的样本与anchor样本有相同的类标签,且与negative的样本有不同的类标签。如下图所示: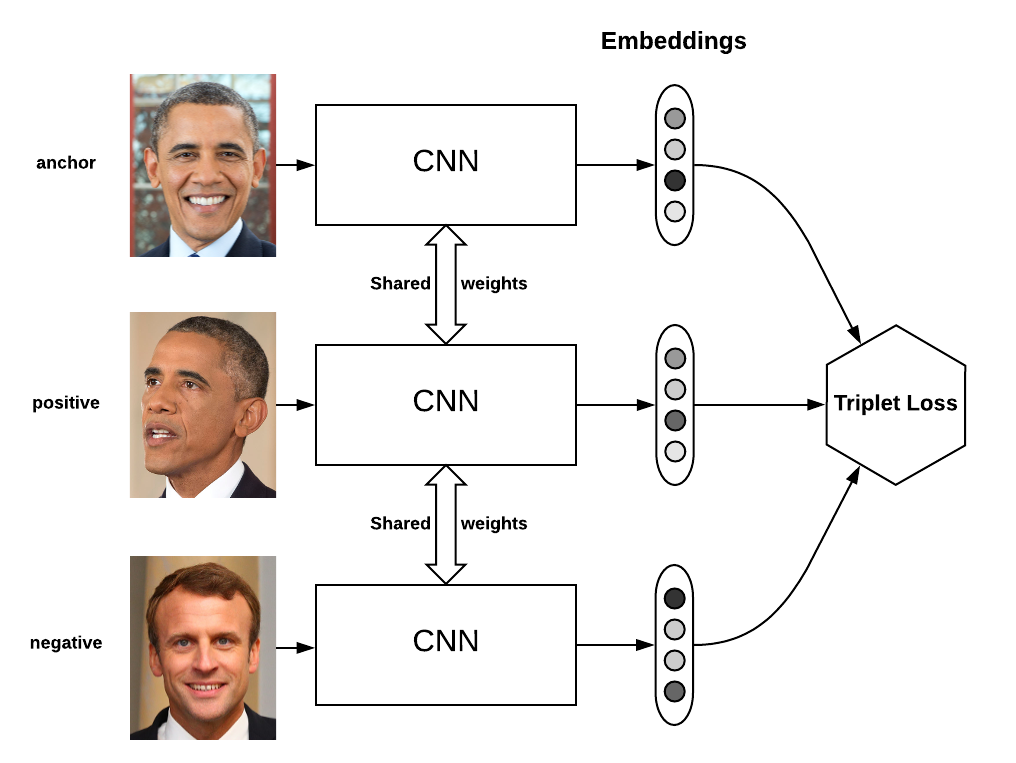
Triplet loss要求negative样本与anchor样本之间的距离比positive样本与anchor之间的距离至少大margin,定义如下:
最近的研究表明,通过为分类设计的softmax loss训练得到的embedding向量在需要计算样本距离的任务中表现也很好,例如可以用大规模softmax分类来训练人脸识别模型。进一步的研究表明,softmax loss与平滑版的triplet loss是等价的[5]。网络最后一个全连接层的权重为每个类赋予了一个类中心embedding向量,而网络最后一个隐层的值即为样本的embedding向量。Softmax loss相当于是定义在(原始样本,样本类中心,另一个类的类中兴)三元组上的triplet loss,因此要求原始样本与其对应的类中心的距离比与另外任意一个类中心的距离都要小。要得到好的embedding表示,我的观察是softmax loss适用于类内方差较小且有大量类别的场景,比如人脸识别。然而,大规模softmax分类(如千万量级的类别)在工程实现上是非常困难的,受制于gpu显存大小的限制,需要实现数据并行加模型并行的分布式训练模型,可能在国内只有阿里这样为数不多的大公司才有能力实现这样的训练平台吧。相比softmax loss,triplet loss可以方便地训练大规模数据集,不受显存大小的限制;triplet loss的缺点是过于关注局部,导致对样本的构建要求很高且收敛时间长。
3.3 Hierarchical Triplet Loss
在实际业务场景中,层次类目结构是很常见的,比如商品类目体系和风险类目体系都是层级的树状结构。标签的层级结构反应了数据的内在分布,充分利用标签的结构信息可以改进模型的效果,也可以改善triplet loss在挖掘困难样本时的盲目性。
我们使用商品类目作为白样本的标签,使用风险类目作为黑样本的标签,为了方便商品类目和风险类目都抽象成3层,商品类目取一级类目、二级类目和末级类目三个层级,同样地风险类目取三级类目、映射类目(介于三级和末级之间)、末级类目三个层级,如下图所示。

层级triplet loss的定义如下:
其中,$M$是mini batch内的所有样本,$T^z=(x_a^z,x_p^z,x_n^z)$是从mini batch构建的一个三元组,$T^M$是mini batch构成的所有三元组的集合。Hierarchical triplet loss中的margin不是一个固定的值,而是根据正负样本的层级差异构建出的动态的值,具体地,
要使用triplet loss,在构建训练样本时,mini batch要遵循“C way K shot”的方式,确保同一mini batch内的样本能够构建出数量足够多的有效triplet。具体地,我们在构建训练样本时,由64个实例组成一组,每组实例仅包含两个一级层级标签,其中一个白样本一级层级,一个黑样本一级层级。每个一级层级标签下包含2个二级层级标签,每个二级层级标签下包含4个三级层级标签,每个三级层级标签下包含4个随机挑选的实例。一个mini batch通常需要有几组这样的样本包构成,我们在训练模型时使用8组构建成一个mini batch,也就是每个mini batch包含512个样本。
3.4 模型结构

参考文献
- 【1】Confident Learning: Estimating Uncertainty in Dataset Labels
- 【2】AN EMPIRICAL STUDY OF EXAMPLE FORGETTING DURING DEEP NEURAL NETWORK LEARNING
- 【3】O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks
- 【4】A Lite Bert For Self-Supervised Learning Language Representations
- 【5】SoftTriple Loss: Deep Metric Learning Without Triplet Sampling
- 【6】Deep Metric Learning with Hierarchical Triplet Loss
- 【7】HIERARCHY-AWARE LOSS FUNCTION ON A TREE STRUCTURED LABEL SPACE FOR AUDIO EVENT DETECTION

