一、背景概述
合规服务业务是基于法律法规建立的信息安全保障机制,保障电商平台的合规经营。商品合规风险指商家未能遵循国家有关法律法规、监管要求或平台制定的经营规则,在平台发布了禁止或限制销售的商品或服务。从发布内容的维度看,违规风险内容主要分为危害国家安全、民生安全、公共安全和市场秩序四大块内容。其中,危害国家安全的违规商品内容包括非法政治、枪支弹药、管制器具、军警用品、暴恐分裂渗透等;危害民生安全的违规商品内容包括毒品、危险化学品、管制药品、管制医疗器械、保护动植物等;危害公共安全的违规商品内容包括色情、低俗、赌博、个人隐私、作弊造假等;违反市场秩序的违规商品内容包括诚信交易类、公序良俗类等。大类的风险类别共计30余种。

坚守风险底线,为用户服务提供良好的制度保障,助力平台提供更简单、更友好的经营环境,保护消费者权益是商品合规业务的主要目标。在商品合规场景,内容维度的风险,文本违规占比约80%。文本违规的主要发现手段之一是关键词规则匹配策略。该策略具有简单、高召回、响应速度快等优点,是必不可少的的一种风险识别策略。
二、问题与挑战
长期以来,关键词规则由业务运营小二人工添加和维护,不同小二会独立构建不同的关键词规则集,规则集的日常迭代更新完全依赖人力,维护成本高,且相互之间难以有效形成合力。
由于 一词多义、主题漂移(topic drift)、对抗变异、敏感词滥用 等问题的存在,关键词规则匹配策略的准确率普遍较低。
【一词多义】带来的语义匹配错误问题,在信息检索领域很常见。比如:“奇彩炫” 既是一个美瞳(管制医疗器械)的品牌,也是和路雪旗下一个雪糕的品牌;“云南白药”不仅仅是(管制)药品的品牌,也可能是牙膏、纸巾、洗发水等产品的品牌;“天润”、“海昌”既是隐形眼镜(管制医疗器械)的品牌,也是很多地名、广场、商贸名;“中华”既可能指香烟(烟草违规),也可能指牙膏。
【主题漂移】在关键词规则匹配过程中也很常见,比如“芙蓉王”既可能匹配上香烟(烟草类目违规),也可能匹配上印有芙蓉王香烟图案的抱枕和手机壳;“m16枪”既可能匹配上自动步枪也可能匹配上玩具枪模型;“中华”除了作为香烟品牌外,也可能作为一个修饰词存在,如“中华沙棘籽油软胶囊”。还有一种情况需要特别说明一下,因为关键词规则匹配引擎是基于字符串多模匹配,而不是搜索引擎常用的倒排索引,不存在文本分词的过程,因此关键词可能会跨越分词边界匹配上文本,比如关键词“雅塑”(一个管制药品品牌)会命中“….优雅 塑料….”;“中保”会命中“日版CUREL珂润干燥浸润 集中 保湿 身体乳液”。
【对抗变异】是风控领域特有的现象,主要指违规内容发布者在感知到其发布的内容被平台拦截之后,会想方设法地通过音近、形近、暗喻等手段,发布与原有违规内容语义相同但描述不同的新内容,从而绕过系统的拦截。比如“香烟”变异为“香yan”;“催情水”会变异为“听话水”、“乖乖水”、“回春水”、“g水”等;某种毒品会被称之为“恰特草”(俗称阿拉伯茶)、“咔哇潮饮”、“咔哇水”、“小金丝”、“小金瓶”、“梦幻草”、“三口鲍”等;危化品液氮会变异为“冒烟冰淇淋”。对抗变异会导致关键词规则集上线之后的准确率逐渐降低。
另外一类导致规则匹配策略准确率较低的原因是【敏感词滥用】,指有些卖正常商品的商家为了吸引流量,会在商品标题里添加一些违规的敏感词,比如部分卖内衣的商家可能会使用“开档”、“露乳”等低俗词,但因种种原因这些滥用敏感词描述的商品并没有被业务判定为违规,也就是说部分关键词规则匹配上的商品既可能被判定为违规,也可能被判定为不违规(商品本身不违规)。
关键词规则缺少细粒度的效果跟踪和汰换机制。一方面由于关键词规则很少单独使用,一般会和其他限制条件一起使用,比如限定在特定类目或商家上,导致细粒度的关键词规则匹配效果难以准确统计;另一方面,由于之前系统没有关键词规则集的自动更新功能,手动汰换关键词规则操作繁琐易出错。因而,关键词规则集越积累越多,臃肿冗余且不强。
正是由于上述 _构建维护成本高、准确率低和难以跟踪与汰换_ 的问题,使用算法手段自动挖掘关键词规则集的需求应运而生,旨在自动挖掘 高准确率的关键词规则集,同时能够根据实际效果自动更新和汰换。
数据驱动的关键词规则自动挖掘面临的主要挑战,除了之前提到的一词多义、主题漂移、对抗变异、敏感词滥用等问题外,还面临样本空间巨大且开放、缺乏干净的标签数据的问题。
样本空间大很好理解。近亿级别的处罚商品,几十亿的在线商品。大数据带来工程实现的复杂性和较长的迭代周期。同时,因为样本空间是开放的,用户随时可能发布任意内容的商品,这对挖掘出的关键词规则的鲁棒性提出了很高的要求。目前的机器学习技术非常擅长挖掘与目标具有关联关系的特征,却难以挖掘特征与目标之间的因果关系。然而,因果关系才是稳定的,关联关系是脆弱的,随着时间变化的。这本质上是因为风控业务都在很大程度上违背了机器之所以能学习的前提条件:独立同分布。风控实际上就是一场猫捉老鼠的游戏。
缺乏干净的标签数据这个问题产生的原因就非常多了,列举一二如下:
- 业务的违规风险类目标签是打在商品这个实体上的,而不是算法需要的商品标题这一维度上的。违规商品的违规内容可能出现在标题、副标题、详情、图片、视频、SKU等任意属性上,因此我们不知道在一个商品违规的前提下,商品标题本身是否违规。
- 商品被处罚可能仅仅是因为发布这个商品的商家的某些行为,而不是商品内容本身。经常发布违规内容的恶意商家发布的所有商品都有可能被判定违规,哪怕实际内容是正常的,比如,积分消耗完,被全店删除。我们发现了很多黑灰产借正常商品的壳发布违规商品的案例。
- 由于审核人员的失误,商品审核时被张冠李戴地打上了错误的风险标签。
- 管控标准发生了变化,比如19年双11前电子烟还不在管控范围内,现在已经全面禁售了。
- 标签本身的变化。风险类目体系存在拆分、合并和迁移的可能,但是历史被处罚商品不会重新关联上新的风险类目。我们还发现因为种种原因,不同层级的风险类目之间还存在重叠的现象,即不同类目都可以包含相同内容的商品。
三、技术方案
1. 噪音标签数据清洗
初略估计,噪音标签的比例高达44%(和外包人工审核不一致的比率),严重影响算法的效果。数据质量决定了业务效果的上限,而算法只能决定多大程度上逼近这个上限。因此,第一步需要清洗脏数据。
目前基于带噪标签数据的学习方法主要有两大类,一类是直接训练对噪声鲁棒的模型(noise-robust models),另一类方法首先识别出噪声数据,然后基于清洗后的数据训练模型。我们主要关注第二类方法,因为我们的目标是挖掘关键词规则集,由规则集构成的风险识别模型并不具备对噪声鲁棒的能力。尝试过的去噪方法简单介绍如下。
a. 基于Confidence Learning识别错误标签
Confidence Learning是一种弱监督学习方法,它能够识别错误标签。Confidence Learning基于分类噪声过程假设(classification noise process ),认为噪声标签是以类别为条件的,仅仅依赖于潜在的正确类别,而不依赖与数据。通过估计给定带噪标签与潜在正确标签之间的条件概率分别来识别错误标签。
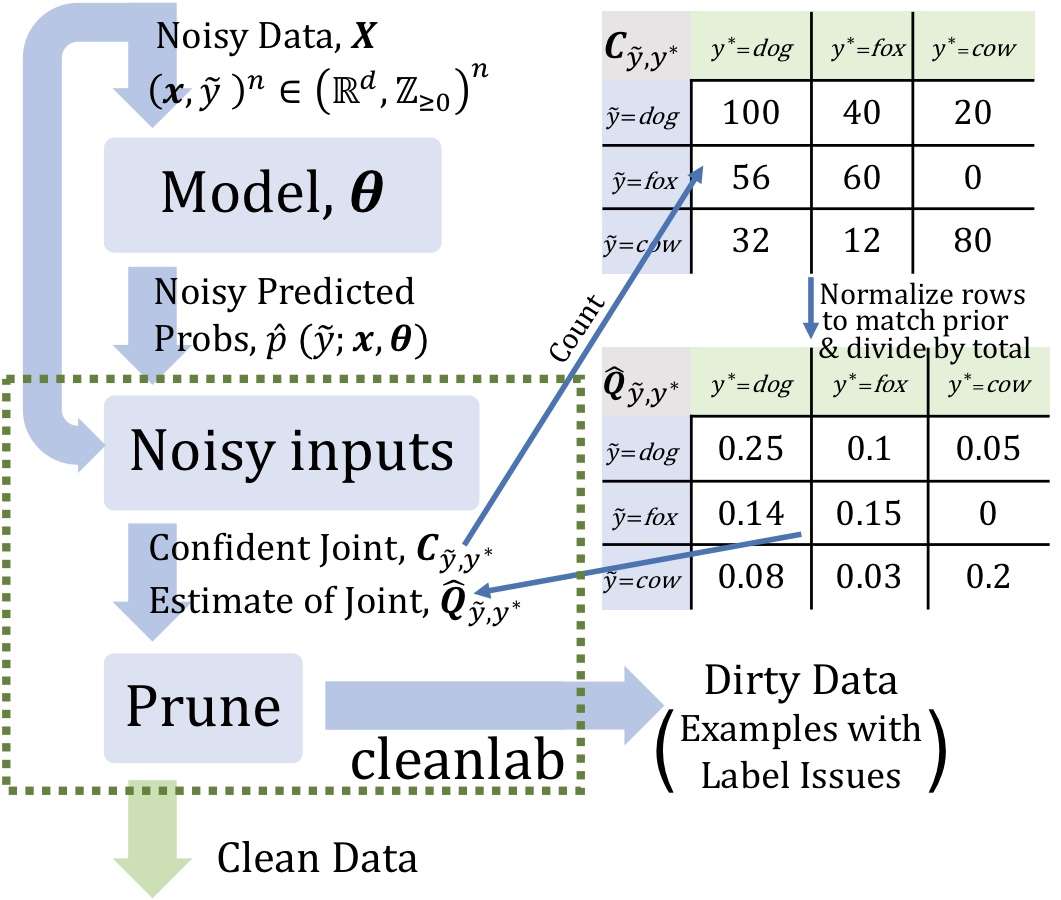
Confidence Learning只依赖两个输入:模型的样本外预测概率和带噪标签。学习过程首先通过预测标签与标注标签的计数矩阵估计带噪标签与潜在正确标签之间的条件概率分布,然后根据该条件概率分布和样本预测概率来识别噪声标签。
b. 基于Forgetting Events识别错误标签
在模型训练过程中,某个样本已经被模型正确分类,随着模型参数的更新,该样本又被错误分类,这一过程被称之为该样本的一次遗忘事件(forgetting event)。根据论文《AN EMPIRICAL STUDY OF EXAMPLE FORGETTING DURING DEEP NEURAL NETWORK LEARNING》的研究,在模型训练过程中噪声样本往往会比正常样本经历更多的遗忘事件。基于这一启发式规则,我们可以记录下每个样本经历的遗忘事件总次数,进一步辨别出可能的噪声标签数据。
c. 基于训练过程的样本loss值识别错误标签
基于训练过程中样本的loss值的相对大小来识别错误标签,这一方法是淘宝技术部的同学在ICCV2019的论文《O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks》中提出的。
大致思路基于以下逻辑:在一次训练中,随着迭代轮次增加,网络逐渐从欠拟合逐渐过渡到过拟合状态,在训练的初期,模型精度的提升是非常明显的,因为网络很快学会了那部分“简单的”样本,因此这类样本的loss比较小,与之相反,那些“困难的”样本通常在训练的后期才逐渐被学会。观察训练过程发现,噪声样本通常是在训练的后期才被学会,因而在训练的早期,噪声样本的平均loss是远大于干净样本的,而在训练的后期,因为网络逐渐学会了所有样本,两类样本的loss区别不大。纵观整个训练过程,从欠拟合到过拟合,噪声样本loss的均值和方差都比干净样本要大。通过循环学习率策略,使网络在欠拟合和过拟合之间多次切换,并追踪不同阶段不同参数的模型对样本的loss,通过在时间维度上捕获多样性足够丰富的模型(类似集成学习,对满足多样性和准确性的多个模型进行ensemble),统计各个样本loss的均值和方差,均值和方差越大,样本属于噪声样本的概率也就越大。
d. 基于样本相似度识别错误标签
基于样本相似度识别错误标签的思路也很简单,首先要训练一个样本相似度模型,然后采样一批置信度较高的白样本,计算白样本与黑样本之间的相似度。识别出与白样本相似度大于阈值,且能多次匹配上白样本的黑样本集合。这些黑样本集合很可能就是噪声标签数据。
e. 基于业务理解及人工规则识别错误标签
通过数据分析,我们发现部分噪声标签的来源具有一定的规律,通过这些规律可以提取出一些简单有效的过滤规则,可以直接清除掉一定数量的噪声标签数据。
例如,一些黑灰产商家主要通过图片来传递违规内容信息,为了规避审查他们发布的商品标题可能是一些无意义的字母和数字,或者是伪装成正常的商品描述。其中,无意义的字母和数字可以通过简单的字符类型识别来定位,我们总共检测出十万量级的无意义标题。另外,通过查看各个风险类目下风险点的定义和数据样本,提炼出一些系统性标签错误的规律,比如“军警用品”违规类目下不当使用国旗、国徽、党旗、党徽的风险点下标题不含“国旗、国徽、党旗、党徽”文字的商品一般是图片违规;图片类“暴力血腥”风险点下标题文本一般没有问题;保护动植物“情节特别严重”风险点下有很多恶意会员店铺正常商品连带处罚;以及不规范展示类“管制刀具”和摄影录像设备(涉嫌“个人隐私”违规)等。这些风险类目下是黑样本商品通常可以直接过滤,或者添加关键词匹配约束后过滤。
f. 实践及思考
观察并分析数据,从数据中总结规律,通常是每个项目首先应该做的事情,并且值得投资更多时间和精力。然而,由于该过程比较繁琐,且显得没有技术含量,所以经常被我们忽略或轻视,最终导致事倍功半。回头总结数据清洗的实践,我们发现基于业务理解及人工规则识别错误标签是非常有效,能够过滤掉几十万到百万量级的噪声样本,并且能够修正部分错误标签,同时也能够给后续的学习过程提供不错的启发。
我们的实验结果表明基于Confidence Learning识别错误标签的方法,以及基于Forgetting Events识别错误标签的方法,还有基于训练过程的样本loss值识别错误标签的方法,在单独使用的时候效果均不是十分令人满意。虽然他们都能够识别出一定量的错误标签,但同时也会把一部分比较难学的黑样本错误地当成噪声标签,这部分的比例取决于阈值的设定。个人觉得这三种方法的前提假设都不是必然成立,仅仅是基于经验的总结,它们的实际效果一定程度上收到训练样本分布的影响。比如,有黑灰产大量借助“儿童文具”这个类目下的正常商品的“壳”发布违规内容,并且我们在采样白样本时“儿童文具”这个类目下的白样本采样数量刚好较少时,上述三种方法均有很大可能会把该类目下的正常白样本识别为噪声,同时不能够识别出伪装的黑样本,产生本末倒置的错误效果。毕竟,谁黑谁白(label的正确与否)对模型来说本来就分不清,最终的结果取决于谁占了更大的比例。这也正是黑灰产厉害的地方,通过样本数量来混淆模型视听的做法有点类似于DDos攻击。最终,我们把三种方法集成在一起使用,是集成学习的一种思路,三个臭皮匠,顶个诸葛亮。
基于样本相似度识别错误标签的方法,虽然想法比较原始,但实际效果还是不错的,噪声标签的检测比较准确。当然,识别效果很依赖于相似度模型本身的性能,将会在下一篇文章中介绍商品风险相似度模型。
2. 关键词规则简介
在介绍关键词规则挖掘方法之前,有必要介绍一下风控引擎支持的关键词规则的形式。
关键词规则一般以集合的形式使用,待检测文本只要被规则集合中的一条规则匹配,则判断为命中。单条规则以不限长度的字符串为原子匹配单位,姑且称之为“pattern”。单条规则可以只有单个pattern,也可以由通过‘&’或者‘~’连接符连接的多个pattern组成。‘&’连接符连接的左右两个pattern必须同时是待检测文本的子串;‘~’连接符表示排除的意思,其右边的pattern不能是待检测文本的子串。
举例说明,待检测文本“克星大型10个逮钢丝大号田抓老鼠夹子铁质野外捕鼠器圆形捉机械式”
匹配上的规则:圆形&抓老鼠~内~窝~笼子~鼠神器
不匹配的规则:圆形&抓老鼠~钢丝
3. 关键词规则挖掘方法
由于文本违规信息主要在商品标题中呈现,所以我们的挖掘语料黑样本选择自清洗过后的已处罚商品,白样本选择自历史审核白样本商品和在线商品。
前面说到关键词规则的准确率较低的一个原因是匹配的“主题漂移”问题,即虽然关键词规则在字面上匹配上了待检测文本,但是待检测文本的整体语义并不是关键词规则原本想表达的语义。在发生“主题漂移”的匹配案例中,我们发现很大比例是由于提取出关键词规则的商品所在类目跟之后关键词规则应用的商品类目不一致导致的。已有的关键词规则集大多只跟风险类目相关,往往没有严格限制规则集作用的目标商品类目。限定每个关键词规则作用的风险类目和商品类目可以很大程度上缓解主题漂移问题。我们在挖掘关键词规则时,会同时挖掘规则的作用商品类目。
“主题漂移”问题的另一个原因是由于在规则挖掘阶段对文本执行了分词处理,而在匹配阶段并不会对文本分词,这就导致匹配阶段可能会存在跨越分词边界的匹配。
文本:新款 书画益智趣味早教训练粘贴纸多种手工思维入门聪明中性2岁
命中关键词: 教训~木~想~儿~子文本:【百草味-年货坚果大礼包1532g/9袋】每日干果过年零食混合礼盒
命中关键词: 日干
跨越分词边界的匹配由于语义转义会导致关键词规则准确率下降。因此我们设计了两阶段的关键词挖掘方案,第一阶段从语料中挖掘候选关键词,第二阶段识别并去除掉候选关键词中潜在错误风险较高的关键词。
3.1 关键词规则挖掘方案一
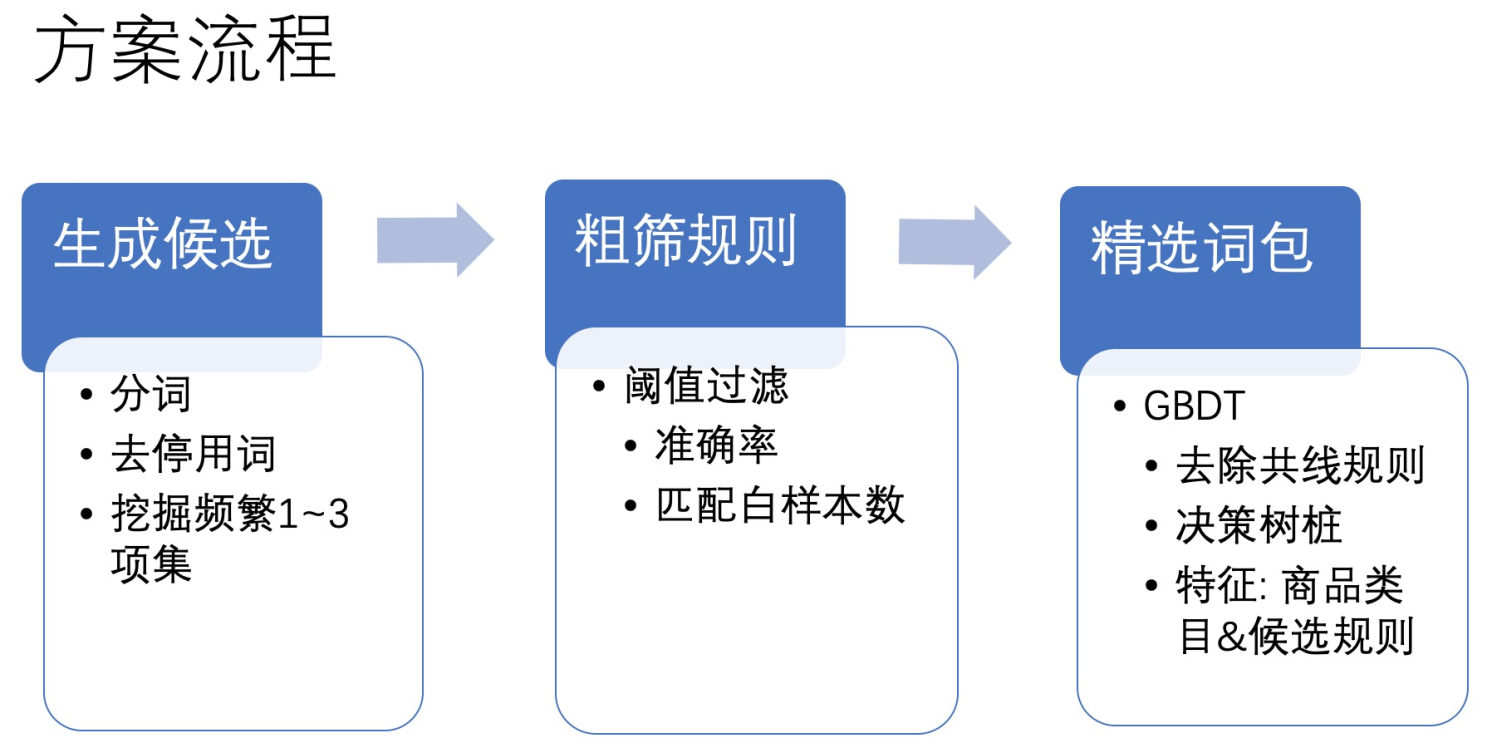
我们尝试的第一个方案没有考虑排除pattern,只考虑有单pattern或者多个pattern的情况。整体流程包含三大步:生成候选规则、粗筛过滤效果较差的规则、精选规则。
首先,在对商品标题分词和去除停用词后,通过Apriori关联规则挖掘算法挖掘风险类目与商品类目两个维度下由关键词组成的频繁1~3项集。这里没有挖掘更高阶项集主要是因为样本空间太大,算法时空复杂性过高。每一个频繁项集对应一条候选关键词规则。接着,统计每一个候选关键词规则的准确率已经在样本空间上匹配的白样本数量,根据阈值过滤掉效果较差的候选规则。
我们在完成第二步,候选规则的粗筛之后,为什么还需要一个精选的过程?第二步得到的候选规则集里的每条规则的准确率不都已经大于阈值了嘛。我观察到的现象是这些候选规则里有很多是接近“共线”的,就是说有些规则能够匹配上的黑样本集合是相似的,而白样本集合却各有各的不同,这就导致这些规则叠加在一起的时候,整体的准确率会比单个的准确率要低。另外,这些关键词规则在实际场景应用的时候面临的是一个开放且不断演变的环境,总会有新的在语料库中没有出现过的样本出现,它们可能会匹配上之前没有见过的白样本,而那些它们原本能够匹配上的黑样本也可能不再出现。所以,关键词规则集的规模并不是越大越好,相反,越大越脆弱。
接下来面临的一个难题是选择哪些候选关键词规则组成最终的规则集。比较自然的想法是使用贪心算法,即每次都选择一个增益最大的候选规则加入规则集。假设 $t-1$ 时刻的规则集是$R_{t-1}$,$R_0=\emptyset$,规则集整体的效用值用函数$f(\cdot)$表示,则贪心算法每次根据下面的等式选择一个候选规则。
虽然贪心算法思路很简单,而且也只能得到一个次优的结果,但其实在我们的场景下贪心算法根本实现不了,原因就在于效用值函数的每次求值都会耗费巨大的算力和时间,当然根本原因还在于样本空间太大(近亿的黑样本,几十亿的白样本)。那能不能只在一个采样出的小规模评估集上求解呢?很明显,也是不行的。
最终我们选择使用GBDT算法来精选候选规则。具体的操作是GBDT算法的一种特殊实现,每一颗新生成的树的深度为1,这样的子模型也叫做决策树桩。特征由关键词规则加对应商品一级类目组成。GBDT算法在生成一颗新的子树的时候只需要做一个简单的判断,即选择哪个关键词规则及其关联商品类目即可。为什么选择GBDT算法呢?因为GBDT算法是一个加法模型,它在生成新的子树的时候优化的目标是最大化整体的效用值,跟我们的需求非常贴近。这个过程天然具有去除冗余的共线特征(相关性很高的特征)的效果,因为共线的特征在选择了其中一个之后,剩下的对整体效用值的贡献很小。这里我们把特征设计为最终需要的(关键词规则,商品一级类目)二元组,并且使用决策树桩作为子模型是一种讨巧的做法。
3.2 关键词规则挖掘方案二
有研究表明具备特征反向选择能力的模型比不具备特征反向选择能力的模型可以表达更加复杂的规则,往往效果也更好。上述方案一并没有反向选择特征的能力,也就是说不能通过排除某些关键词来提升规则的准确率。如何能够使得规则能够反向选择特征呢?
我们熟悉的决策树算法是具备反向选择特征的能力的,树的每个节点对应的左右两个分支就对应着某个特征是否被选中。那么,能不能直接把关键词作为特征,使用GBDT算法来训练模型,最终通过解析每个子树从根节点到叶子节点的路径来学习关键词规则呢?毕竟,这样得到的关键词规则也是包含了“排除”特征的。这里的一个关键问题是如果GBDT算法使用关键词作为特征并且直接用原始的样本集训练,会面临维数灾和计算效率的巨大挑战。
最终,我们参考论文《Fast Effective Rule Induction》中提出的IREP方法,做出适当的修改用来挖掘关键词规则。
1 | procedure IREP(Pos,Neg) |
在生成新规则这一步,每次选择一个关键词添加到当前规则中,根据选择的关键词是正向词还是负向词来决定是用‘&’符号连接,还是用‘~’符号连接;循环迭代直到新规则的准确率大于阈值为止。这里还有一个剪枝的过程,如果有太多的负向词或正向词被选中,则直接放弃该规则,重新生成一个。另外,在选择关键词时需要过滤明显不合理的关键词,例如前一步已经选择了“节假日”加入规则,当前步就不能选择“节假日”的任意子串(如,“假日”)。
那么每次应该选择哪个关键词呢?这其实是一个古老的特征选择问题,有很多方法。参考《Feature Selection for Text Categorization on Imbalanced Data》,我们实现并测试了以下五种:卡方(CHI square)、基尼指数(gini index)、GiniTxt(基尼纯度的一种变种)【6】、优势率(odds ratio)、信息增益率、信息值(Information Value, Weight of evidence的变种)。除了卡方和基尼指数的结果比较类似之外,不同的特征选择方法得到的结果差异还是挺大的。最终我们选择了卡方、优势率、信息增益率三种特征选择方法,同时挖掘候选关键词,并对候选关键词规则做去重和合并的处理。
| 黑样本数 | 白样本数 | |
|---|---|---|
| 包含词 $t$ | A | B |
| 不包含词 $t$ | C | D |
假设某风险类目 $c_i$ 下的样本分布如上表所示,并且 $N=A+B+C+D$ 为总样本数,计算词 $t$ 与该风险类目的相关系数:
相关系数为正数时表示词 $t$ 与风险类目 $c_i$ 正相关,是正向词;相关系数为负数时表示词 $t$ 与风险类目 $c_i$ 负相关,是负向词,作为关键词规则中的排除词。相关系数的平方就是卡方,即$CC^2=\chi^2$。卡方特征选择方法每次都选择使上述公式平方值最大的词作为特征。
信息增益的计算公式为:$IG(t,c_i)=\sum_{c \in \{c_i,\overline c_i\}}\sum_{t’ \in \{t,\overline t\}}P(t’,c)log\frac{P(t’,c)}{P(t’)\cdot P(c)}$
优势率的计算公式为:$OR(t,c_i)=log\frac{P(t|c_i)[1-P(t|\overline c_i)]}{[1-P(t|c_i)]P(t|\overline c_i)}$
值得注意的是,关键词规则的去重合并并不是按照字符串是否完全匹配进行,而是按照关键词规则的语义识别出两者之间是否存在‘蕴含’关系。如规则B能匹配的文本集合只能是规则A匹配的文本集合的子集,在规则A蕴含规则B,即为‘A->B’,此时规则B就没必要存在于最终的规则集中。
规则蕴含关系举例:聊->陪聊;多&肉->多肉;聊天->聊天~姐姐;聊天~c1_123->聊天~c1_123~c1_456;聊天~清高->聊天~清;电影~电视->电影~电视~剧;电影~高清->电影~高~清;娃->娃&c1_123;娃&c1_123->娃&c1_123&c1_456
另外,由于规则集中的关键词规则彼此之间是‘或’的关系,待检测文本只要匹配其中一个就算匹配上了,所以形如“A~B”和“A~C”这样的两条规则不能同时存在于同一个规则集中,否则效果就等价于规则“A”,丢失了排除词的限定作用。可以选择保留其中之一,或者合并成“A~B~C”。
IREP规则挖掘算法可以理解为是一个广义加法模型(GAM,generalized additive model),预测函数为$F(x)=f_0(x)+f_1(x)+f_2(x)+\cdots+f_n(x)$,其中$f_i(x)$对应一条关键词规则,$x$是输入文本,$f_i(x)=1$表示关键词规则命中输入文本,反之,若$f_i(x)=0$表示关键词规则没有命中输入文本。采用前向分步算法(forward stagewise algorithm)来生成,每一步生成一个关键词规则,目标是使得总的经验误差最小。其学习过程非常类似于大名典典的GBDT算法,但能支持更大的数据规模。
我们是以风险类目和商品一级类目为单位执行挖掘算法,进一步限制了输入的样本数量,从而是算法能够做到每日更新。算法的每日更新能够一定程度上抵御对抗变异带来的准确率下降问题。
3.3 识别并去除潜在错误率较高的候选关键词
为了一定程度上避免跨越分别边界匹配引起的“主推漂移”问题,我们需要识别并去除潜在错误率较高的候选关键词。在这个阶段,我们重新准备一批测试数据,选择最近一段时间风控引擎接受到的新发和编辑商品及其审核结果,加上同时期其他渠道(风控、举报等)收集到的违规商品作为测试数据集。保证测试数据的分布和线上真实情况一致。然后,在上述测试集上用尽可能和线上一致的方式匹配候选关键词,并统计每个候选关键词的匹配白样本数和准确率,最终去除掉准确率低于阈值或者匹配白样本数大于阈值的候选关键词。
3.4 一点思考
仔细观察方案二中使用的IREP算法,发现其很多地方跟GBDT算法很像。两种都是通过不断添加子模型来最大化整体模型的效用值。GBDT的子模型是一颗决策树;IREP算法的子模型是一条关键词规则,也可以认为是决策树的一条从根节点到叶子节点的路径。为什么IREP算法只需要一条路径而不是一棵树呢?因为我们最终需要的是规则,而不是决策树。一颗决策树有多条从根节点到叶子节点的路径,其中有些路径分类为正,有些路径分类为负。那些分类为负的路径我们不需要提取出来,因为规则匹配引擎会在所有规则都不能命中时默认判断结果为负。那些分类为正的路径,IREP算法每次只学习出其中的一条出来,其余的嘛就留给下一次学习了。从这个角度看,GBDT算法比IREP算法的效率要高,相比IREP算法其复用了多次特征选择的结果。但从最终效果的角度看,两者的学习过程并没有本质的区别。另外,IREP算法把每次新生成的规则覆盖的样本删除之后再用剩余的样本生成下一条规则,这个做法其实跟GBDT算法根据损失函数的梯度来生在新的决策树发挥的作用是类似的,都是为了使新生成的决策树或者规则的效用值增益最大。
方案一和方案二都跟GBDT算法有某些联系,这其实并不是偶然的。因为关键词规则匹配系统的执行过程跟GBDT算法的预测过程是非常类似的,可以认为关键词匹配引擎就是GBDT算法预测过程的一种特殊实现。所以,关键词规则的挖掘当然也应该用GBDT算法来实现。怎奈何GBDT算法本身支撑不了这么大的数据量和这么高维的离散特征。方案一和方案二都是对GBDT算法的简化和近似。方案一限定了规则最多只能由三个关键词组成,而方案二没有这一限定。
四、总结与展望
通过学习形式更加复杂的关键词规则,可以一定程度上缓解【一词多义】、【主题漂移】与【敏感词滥用】的问题。通过限定关键词规则作用的风险类目和商品类目可以规避很多【主题漂移】的问题。通过关键词规则的每日更新可以一定程度上缓解【对抗变异】的问题。
不可否认的是,通过关键词规则来判断输入文本是否是某种类型的风险违规这一机制本身是有一些固有的缺陷的,比如没有办法去理解输入文本的语义,没有办法真正杜绝【主题漂移】问题。除此之外,关键词规则匹配引擎还有一些特殊的匹配逻辑,如跳字匹配,会导致规则挖掘时测试的准确率和线上真实准确率的不一致。问题和挑战依旧存在。在信息检索领域,搜索引擎至少需要召回和精排两个阶段才能返回比较让人满意的结果。同样,在风险判定问题中,关键词规则匹配只完成了第一步,也就是召回的过程。那么,类似于“精排”的第二步呢?
无论是关键词规则,还是目前的深度学习技术,都无法有效解决的一个问题就是风险的根因分析(不仅仅指可解释性),下一步该何去何从?
参考文献
- 【1】Confident Learning: Estimating Uncertainty in Dataset Labels
- 【2】AN EMPIRICAL STUDY OF EXAMPLE FORGETTING DURING DEEP NEURAL NETWORK LEARNING
- 【3】O2U-Net: A Simple Noisy Label Detection Approach for Deep Neural Networks
- 【4】Fast Effective Rule Induction
- 【5】Feature Selection for Text Categorization on Imbalanced Data
- 【6】尚文倩 et al,文本分类中基于基尼指数的特征选择算法研究.
- 【7】Weight of evidence and Information Value using Python

