背景介绍
随着互联网扁平化的发展,内容信息的分发和获取比以往更加便利,这也大大方便了以色情、赌博、非法政治言论、违禁药品买卖等为代表的违规信息的快速传播。这类信息的传播会造成难以估计的社会影响,甚至有可能影响国家的安定和谐。网站所有者可以随意更改网站页面的内容,发布任意形式的信息。论坛、博客、社交产品等web 2.0的网站可以让普通用户随意发布UGC内容。安全防控做得不到位的网站页面内容还可能被黑客随意篡改,甚至安装木马病毒。综上,网站页面内容的生成方式多种多样,内容发布者也是形形色色,其中就会有不少不法分子利用网络传播违规信息以达到非法牟利,甚至控制网民意识形态,颠覆国家政权的目的。
为了净化云平台以及维护网络环境的安全和稳定,对云上网站中存在的各类违规内容进行治理成为了意义重大又迫在眉睫的问题。本文主要介绍如何通过深度学习算法检测网页中是否包含了特定类型的违规内容。
算法框架
网页内容安全风险识别体系由数据资产构建和算法模型构建两方面组成,整体框架如下图所示。
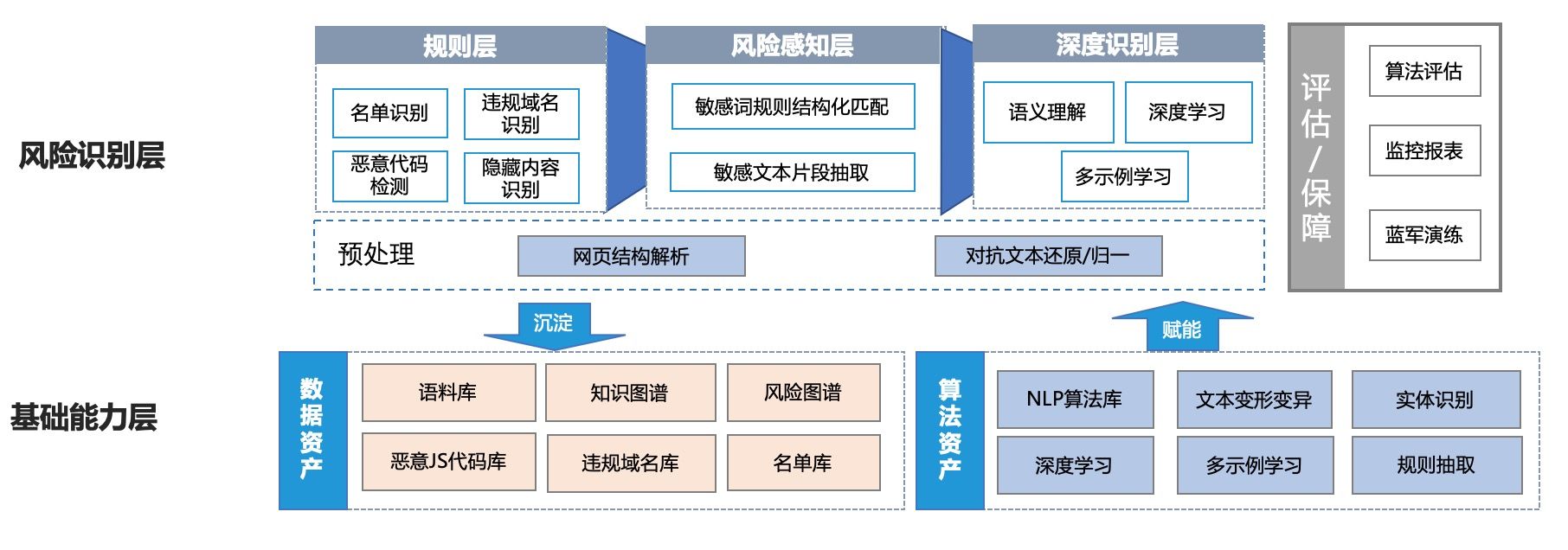
数据资产构建
1. 语料库
为了训练有效的算法模型,我们需要较多的训练样本。可以用爬虫来采集网页,构建训练数据集。
下面以非法政治风险为例,简要介绍如何构建训练语料。通过爬虫采集的方式,从海外主要的反华媒体,如新唐人电视台、大纪元、品葱、膜乎、中文禁文网等采集一批黑样本页面;从国内主要涉政媒体,如中国政府网、人民网、政治家网、求是网等采集一批白样本数据。当然,采集的语料的标签不完全正确,还需要集合其他技术手段做数据清洗。
2. 敏感词规则
敏感词规则主要用来召回风险,是风险防控的第一道漏斗。对风险识别算法的最终效果、服务性能都有重要的影响。另外一方面,敏感词规则在语料集数据清洗、网页敏感文本抽取、特征工程等多个环节都有重要的作用。
敏感词规则可以从各个渠道收集整理而来,比如针对色情风险,我们可以很容易找到很多AV女优名单。另外,也可以从语料库中挖掘敏感词规则。针对有标签的语料,我们采用RuleLearning算法挖掘敏感词规则。针对无监督语料,我们使用TopMine算法自动生成候选短语,再通过人工review的方式确定最终使用的敏感词集合。
算法模型构建
1. 文本预处理
文本预处理模块包括HTML代码解析与文本归一化两部分。
- HTML代码解析
HTML代码解析不仅仅是去除HTML标签保留纯文本,有两个重要的行动是保障算法效果的必要步骤。第一,是要根据CSS样式代码去除掉在页面渲染时无法展示的干扰内容;第二,是要尽可能保留页面内容的区块、段落、分行结构,这一步是为了保障敏感词规则匹配时尽可能减少误匹配。举例而言,敏感词规则有很多形如“A&B”这样的规则,那么A和B这两个子串如果分别在不同的区块、段落、甚至在不同行之间的匹配都是我们不希望的。因此,解析HTML代码需要细粒度识别每个HTML元素的语义,比如是块元素还是内联元素等,以及需要考虑是否与前一个元素内容连接等因素。
- 文本归一化
文本归一化模块提供一些通用的变异文本还原功能,主要包括:
- 繁体转简体
- 全角转半角
- 大写转小写
- html实体符号还原:
"λ" -> "λ"; "<" -> "<"; " " -> 空格 - unicode字符规范化:
① -> 1 ; ㊉㊚ -> 十男 ; ㏴ -> 21日 - html标签去除:
<div style='xxx'>hello world</div> -> hello world - emoji表情转汉字:
“🇨🇳🇺🇸📦📽️🇩🇪⬅️🏊🐓”->“中美合拍的西游记” - 拆分字合并:
三去车仓工力 -> 法轮功 - 特殊符号过滤
- 抽象字还原:
艹比 -> 操逼; 六亖 -> 六四; 六罒事件 -> 六四事件
举例如下:1
2输入:😲!㊥.國Zui.無.耳止 的<strong>謊.訁</strong>就要大.白.於天.㊦
输出:震惊 中国最无耻的谎言就要大白于天下
2. 特征工程
- HTML标签特征
除了常规的字符embedding(中文汉字,英文wordpiece)和位置embedding特征之外,我们根据网页内容的特点加入了html标签embedding。根据云管控业务的管控标准,某些风险如网络招嫖、赌博等违规内容需要有明显的联系方式或者超链接才会判定为违规。另外,网页信息的展现样式跟html标签有很强的关联,因此文本内容对应的html标签路径是一个很有用的特征。我们选择了一些重要的html标签,比如<a>等,作为模型的特征之一。
- 文本数据增强
数据增强是提升深度学习模型鲁棒性的一种重要手段。在少样本学习、正负类别样本分布不平衡、半监督学习等场景,通过数据增强给数据加上杠杆,是快速提升模型效果的一种简单易行的方法。
典型文本数据增强技术方案包括EDA、回译(Back translation)、基于上下文信息的文本增强、基于语言生成模型的文本增强等。
EDA是一种简单有效且实现成本低的方法,具体操作包括随机词删除、同义词替换、同义词插入、位置交换等。中文的同义词可以使用哈工大开源的同义词词林,或者使用阿里NLP团队的相关积累。另一种思路是使用word2vec模型生成近义词/相关词,用近义词替换或插入来做数据增强,这种方法可以大大扩充近义词数量,但也有改变原始文本的语义的风险。由于我们的业务场景需要从一大段文本中提取文本片段,因此我还尝试了通过平移或缩放滑动窗口的方法来生成数据增强的候选文本,这种方法可以在不改变语义的情况下获取大量的增强文本,也是一种很好用的方法。
得益于近几年文本翻译领域的显著进展、各种先进翻译模型的开源(包括百度、google 等翻译工具的接口开放),基于回译(back translation)方法的文本数据增强成为了质量高又几乎无技术门槛的通用文本增强技术。回译方法的基本流程很简单,利用翻译模型将语种1的原始文本翻译为语种2的文本表达,基于语种2的表达再翻译为语种3的文本表达,最后再直接从语种3的形式翻译回语种1的文本表达,此文本即是原始文本增强后的文本。当然,很多时候只采用一种中间语种也可以实现很好的增强效果。
基于上下文信息的文本增强技术在原理上也很直观:首先需要一个训练好的语言模型(LM),对于需要增强的原始文本,随机去掉文中的一个词或字(这取决于语言模型支持字还是词)。接下来,将文本的剩余部分输入语言模型,选择语言模型所预测的 top k 个词去替换原文中被去掉的词,以形成 k 条新的文本。
文本数据增强还有不少其他方法值得进一步探索,比如文本风格迁移等。该方法之所以有效,首先它无疑是一种有效的正则化方法,无论是回译、EDA、非核心词替换还是基于上下文的文本增强,本质上都是设计者表达了一种模型偏好(归纳偏置),或者对于模型的分布施加了较强的先验分布假设。其中,回译表达的模型偏好是,模型应该对于不同表达形式但同一语义的文本具有不变性。EDA、关键词替换等表达的模型偏好则是,模型应该对于文本的局部噪声不敏感,实现了类似于 dropout 层的功能。任何学习都需要有效的外部信息指导,上面所提的基于上下文信息的文本增强技术的有效性无疑也可以从迁移学习的角度来理解。因此,即使面临少样本场景,基于文本增强的模型也能够在假设空间中有效地收敛,实现较好的泛化误差。
3. 文本Encoder: DGCNN模型
文本编码器采用了膨胀门卷积神经网络(Dilate Gated Convolutional Neural Network),基于膨胀卷积和门卷积的CNN和简单的Attention的模型,由于没有用到RNN和Transformer结构,因此速度相当快。模型结构如下图所示。
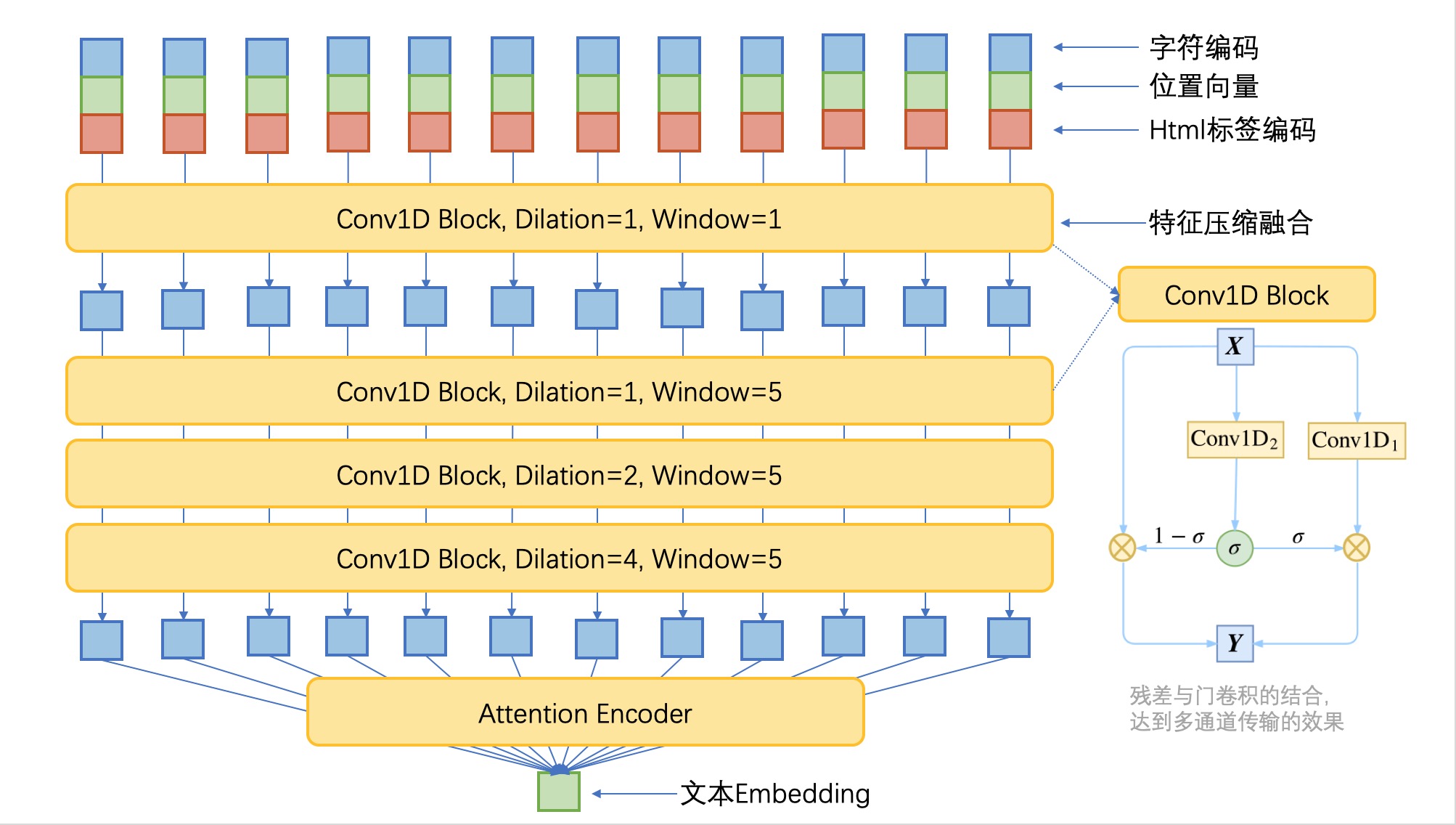
模型中采用的门卷积结构,来自FaceBook的《Convolutional Sequence to Sequence Learning》。假设我们要处理的向量序列是$\boldsymbol{X}=[\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_n]$,那么我们可以给普通的一维卷积加个门:
这里的两个Conv1D形式一样(比如卷积核数、窗口大小都一样),但权值是不共享的,也就是说参数翻倍了,其中一个用sigmoid函数激活,另外一个不加激活函数,然后将它们逐位相乘。因为sigmoid函数的值域是(0,1),所以直觉上来看,就是给Conv1D的每个输出都加了一个“阀门”来控制流量。这就是GCNN的结构了,可以将这种结构看成一个激活函数,称为GLU(Gated Linear Unit)。进一步,可以采用残差结构使得信息能够在多通道传输。
接下来,为了使得CNN模型能够捕捉更远的的距离,并且又不至于增加模型参数,我们使用了膨胀卷积。普通卷积跟膨胀卷积的对比如下图所示。

同样是三层的卷积神经网络(第一层是输入层),窗口大小为3。普通卷积在第三层时,每个节点只能捕捉到前后3个输入,而跟其他输入完全不沾边。
而膨胀卷积在第三层时则能够捕捉到前后7个输入,但参数量和速度都没有变化。这是因为在第二层卷积时,膨胀卷积跳过与中心直接相邻的输入,直接捕捉中心和次相邻的输入(膨胀率为2),也可以看成是一个“窗口大小为5的、但被挖空了两个格的卷积”,所以膨胀卷积也叫空洞卷积(Atrous Convolution)。在第三层卷积时,则连续跳过了三个输入(膨胀率为4),也可以看成一个“窗口大小为9、但被挖空了6个格的卷积”。而如果在相关的输入输出连一条线,就会发现第三层的任意一个节点,跟前后7个原始输入都有联系。
按照“尽量不重不漏”的原则,膨胀卷积的膨胀率一般是按照1、2、4、8、…这样的几何级数增长。
4. 学习范式:多示例学习
多示例学习(multiple-instance learning)与监督学习、半监督学习和非监督学习有所不同,它是以多示例包(bag)为训练单元的学习问题。在此类学习中,训练集由若干个具有标签的包组成,每个包包含若干没有标签的示例。若一个包中至少有一个正例,则该包被标记为正(positive),若一个包中所有示例都是反例,则包被标记为反(negative)。通过对训练包的学习,希望学习系统尽可能正确地对训练集之外的包的标签进行预测。
与监督学习相比,多示例学习中的训练示例是没有标签的,这与监督学习中所有训练示例都有标签不同;与非监督学习相比,多示例学习中训练包是有标签的,这与非监督学习的训练样本中没有任何标签也不同。更重要的是,在以往的各种学习框架中,一个样本就是一个示例,即样本和示例是一一对应关系;而在多示例学习中,一个样本(包)包含了多个示例,即样本和示例是一对多的关系。
对应到网页风险识别场景,我们从每个网页中抽取若干文本片段作为训练数据。每个文本片段对应一个示例,若干个文本片段组成一个包,也就是一条训练样本。风险类型标签与网页相关联,而不与文本片段相关联,对应到多示例学习框架中就是标签与包相关联,而不与示例相关联。
我们从网页中抽取的若干文本片段并不能保证所有文本片段都包含了特定风险的违规信息,抽取的过程中可能存在噪音。多示例学习框架只要求每个包中至少包含一个正例,则该包就可以标记为正例;因此,我们只需要尽可能保证批量抽取的文本片段中有一个文本片段包含了违规内容,就可以放心地把该包标记为违规。由此可见,多示例学习对数据噪声有很好的鲁棒性,比较贴合网页风险识别业务的需求。
在预测阶段,使用与训练阶段相同的流程从待检测网页中抽取若干文本片段,每个文本片段作为一个示例,同一网页中抽取出的所有文本片段组成一个包,输入给预测模型,由模型结果来判断是否是某种类型的风险违规。
我们参考《Attention-based Deep Multiple Instance Learning》论文中的方法来构建训练模型。首先,我们对每个包中的若干个示例,通过上文提到的DGCNN文本编码器转换为一个固定长度的embedding向量;其次,通过attention机制把第一步得到的若干个embedding向量融合为一个最终的embedding向量;最后,在上一步得到的embedding向量之后接一个softmax分类层即可。架构示例图如下。
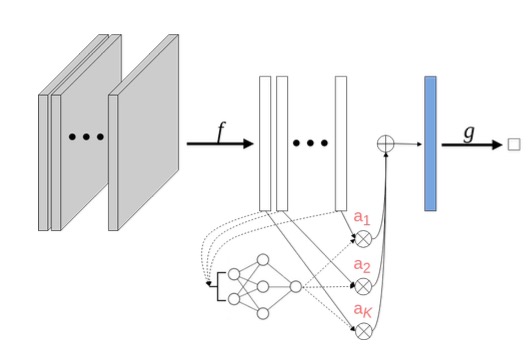
具体地,假设第 $k$ 个文本片段对应的embedding向量为 $h_k$,则最终得到的包的embedding向量为$z=\sum_{k=1}^K a_k h_k$,其中
上式中,$w,V$ 都是待学习的参数。
5. 损失函数:F1 score 动态加权的类别分布自平衡 loss function
现实世界中的监督学习问题,大多是类别分布不平衡的。虽然已存在多种处理类别分布不平衡的方法,常用的方法包括re-sampling和re-weighting两大类。Re-sampling类方法存在浪费训练数据或有过拟合的风险。Re-weighting大多对数据中的噪音非常敏感。
我经常使用的处理类别分布不平衡问题的损失函数是F1 score动态加权损失函数,该损失函数经测试能较好地处理类别分布不平衡问题,比如在正负样本比例为1:200的情况下也能有较好的表现,并且有一个很好的特性就是对数据噪声不敏感。使用该损失函数还可以根据业务需求动态调整对准确率-召回率的偏好。
简单地说,F1 score动态加权损失函数保持正样本的权重为 1,为负样本动态地计算权重:
其中,$\beta$ 为准确率-召回率的偏好调节因子,$P$、$N$ 分别为当前mini batch中的正样本和负样本数量,$TP(\theta)$、$TN(\theta)$ 分别为当前mini batch中用当前模型参数预测为True-Positive和True-Nagative的样本数量。
关于该损失函数,更详细的信息可参考《Adaptive Scaling for Sparse Detection in Information Extraction》。
总结
网页风险防控因数据是以源码的形式作为输入,区别于传统的文本安全场景的输入,具有一定的独特性,后续可以进一步挖掘该类型文本的特征。另外,长文本分类也属于一类比较难的NLP问题,值得进一步研究。欢迎有兴趣的同学交流想法,共同探讨。

